Getting Started

This article is dedicated to explain one of the most classical Machine Learning classifier – Naïve Bayes. In this story I am going to explain the theory behind Naïve Bayes and most importantly will present a simple-from-scratch implementation of this model. This article is going to be very useful and interesting for people entering Machine Learning field. I also believe that the readers with ML experience will also learn something new. So without a further-ado let’s begin.
As Isaac Newtown once said: "If I have seen further than others, it is by standing upon the shoulders of giants", this is something I believe myself as if you want to create something new, you have to understand what has been done before. This could allow you not to waste your time on something that was invented or to find opportunities to improve previous methodologies and to challenge the status-quo.
Because of that I would like to talk about how Naïve Bayes can be used in order to solve Text Classification problems, and will not touch latest Deep Learning approaches yet. This will allow majority of the readers to be able to follow and understand this article regardless of educational background.
If you are new to the world of Natural Language Processing (NLP) I would suggest you to check my previous article where I discussed how we can use simple probability rules to perform text generation, before you read this story.
In this article we are going to create an email spam filter using Naïve Bayes classifier from scratch, without using any external library. First I would like to cover some theory, and then we will move to the implementation part.

Theory.
Bayes Formula.
There are plenty of articles that cover Naïve Bayes and how does it conceptually work, so I am not going to go in-depth with the theoretical explanations but will cover the most essential and important parts.
As we all know Bayes formula looks like that:

In our NLP setting we would like to calculate what is P(spam|text) and what is P(not spam|text).
By the commonly used terminology I will refer to "not spam" as to "ham".
As we all know, text of any email usually consists of words. Therefore, we are interested in calculating P(spam | word1, word2, …, wordN). To put it in the form of Bayes formula:

When we compute similar probability but for ham case we will get the following formula:

As you can see, the denominator P(w1, w2, …, wN) [also known as normalization] is the same in both cases, and because our task is to identify which probability is higher (rather than the exact values) we can drop normalization part. Reasoning is shown below:

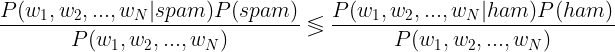

So in the end of the day, in Bayesian classification we end up with the following simplification:

Side Note: normalization part is ignored in most of the cases not only because it is redundant but also because it is usually very complicated to compute from the data, so not having to deal with it simplifies our life a lot!
Why are we Naive?
To recap, in order to say if email is spam or not we will need to see what value is higher P(spam|w1, …, wN) or P(ham|w1, …, wN).
And to compute P(spam|w1, …, wN), we need to have:
- P(spam) – easy to find as it is going to be just a ratio of spam emails to all emails in our dataset.
- P(w1, …, wN| spam) – a bit harder to compute directly, so lets use "naive" assumption that words in the text are independent, by doing this we can simplify this term to:

So in the end to compute P(spam|w1, …, wN) we will do:

Looks quite simple but, let us not make one mistake which is going to make our results break. Consider what happens if we need to check a word _wi but it has never appeared in a spam email?
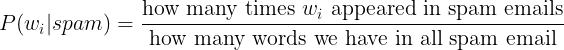
In other words: _P(wi|spam) = 0.
Obviously in such a scenario because of the multiplication we will end up with P(spam|w1, …, wN) = 0, which might lead to the wrong conclusion, as we can never assume to have a perfect training data which has all the words. It is also possible that a word contained typo and thus will be clearly unknown to the system. (also consider situation when the word has never appeared in both spam and ham emails, how shall we classify the email containing this word then?)
To address this issue, a smoothing approach is used which makes sure that we assign non-zero probability to any term:

Here α (alpha) is a smoothing parameter should be a nonnegative number.
Make it efficient – Use Logarithms.
As we have seen before to compute the probability we will have to do multiplication a lot (as many times as we have the words in the email to be evaluated):
And the problem is that all the probability numbers are going to be less than 1, and in general are going to be very small. And as we all know, product of 2 small values 0 < a, b < 1 is going to result in a smaller number. So in the case of Naïve Bayes approach we will be limited by the floating point precision of our computer (as at some point spam and ham equations will just converge to zero, only because of the computer’s limitations when working with very small numbers).
What shall we do? Do we need to move our computation to some supercomputer that can keep track of very small numbers? Fortunately, this is not needed and Logarithms come to help! And we will use Logarithm’s Product Rule.

The other reason why we use logarithm is because:
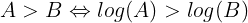
Hence, if log(P(spam|text)) > log(P(ham|text))
then P(spam|text) > P(ham|text)So it is going to be much easier for us to compute the probabilities using logarithms which will have the following form:

Implementation.

Enough of the theory, let’s bring that theory into life. As I mentioned before, I am going to implement Naïve Bayes classifier from scratch and will not be using any python’s external library, as it allows to achieve multiple things:
- It helps us to better understand the theory behind Naïve Bayes. Will be very beneficial for the reader who is new to Machine Learning field.
- It allows us to have some flexibilities and to improve the standard approach. In this article we will be using Unigrams and Bigrams simultaneously (if you don’t know what a bigram is read this article).
The full code and the dataset can be found on my github repository.
The dataset contains emails in a raw format, therefore in order to work with emails data we would have to use python’s email library.
Now, let’s look at supporting functions:
The first one is a tokenizer, in your modifications feel free to use any other approach, but here this method tokenization approach works well enough (you will see how good our accuracy is going to be).
Below you can see the function that we will use to calculate the log probabilities for spam and ham emails.
As mentioned earlier, I am going to use here both unigrams and bigrams to identify if an email is a spam or not, hence we are working with calculating
_P(spam|token_1, token_2, … tokenn), where a _tokeni could be either represented by a unigram or bigram. Which is better than working on a word (unigram) level only, as we becoming less Naive (because we accept some dependency of words in a text).
Apart from what we have discussed in the theoretical part, I also introduce some special tokens like <UNK> , which will be used during the inference part if we stumble across the unknown word that we have not seen in the training set.
Apart from that I create a token <LONG_W> which corresponds to the long word which is larger than 12 characters, which probability is computed similarly as for all other tokens.
Spam Filter Class.
Now let’s move to the implementation of the Spam Filter class:
Initialization of the class takes around 10 seconds because we need to make a pass through all spam and ham emails and compute all the word-class dependent probabilities.
The is_spam function does all the inference job, and is responsible for deciding if an email is a spam based on the tokens that appear in the text. Since this function does exactly what we have discussed in the theoretical part, I am not going to provide detailed explanation of the implementation.
Now, let’s create the main function and test how good does our solution work.
As a result we get:
done with initialization! 9.24 s
spam errors: 1
ham errors: 1
correct identified: 0.99599.5% Accuracy, with only 1 False Negative and 1 False Positive, this is a very impressive result!
Feel free to change some parameters like smoothing or get rid of using bigrams and use only unigrams, to see how much the model’s accuracy goes lower. Here, I have presented the optimal model that achieves perfect result.
As you have seen from this article, Naïve Bayes is a very simple and easy to implement Machine Learning model that is capable of achieving some incredible results for language classification tasks.
The most incredible thing is that it took us only 10 seconds to train the model and to achieve very good accuracy. Compare it to Deep Learning approaches which would take couple of hours to train and are most likely going to be able to only achieve a similar performance as our Naïve Bayes.
Let me know in the comments if there some ML topic you would like me to cover in the next article.
Stay tuned for more articles about Artificial Intelligence and Natural Language Processing.







