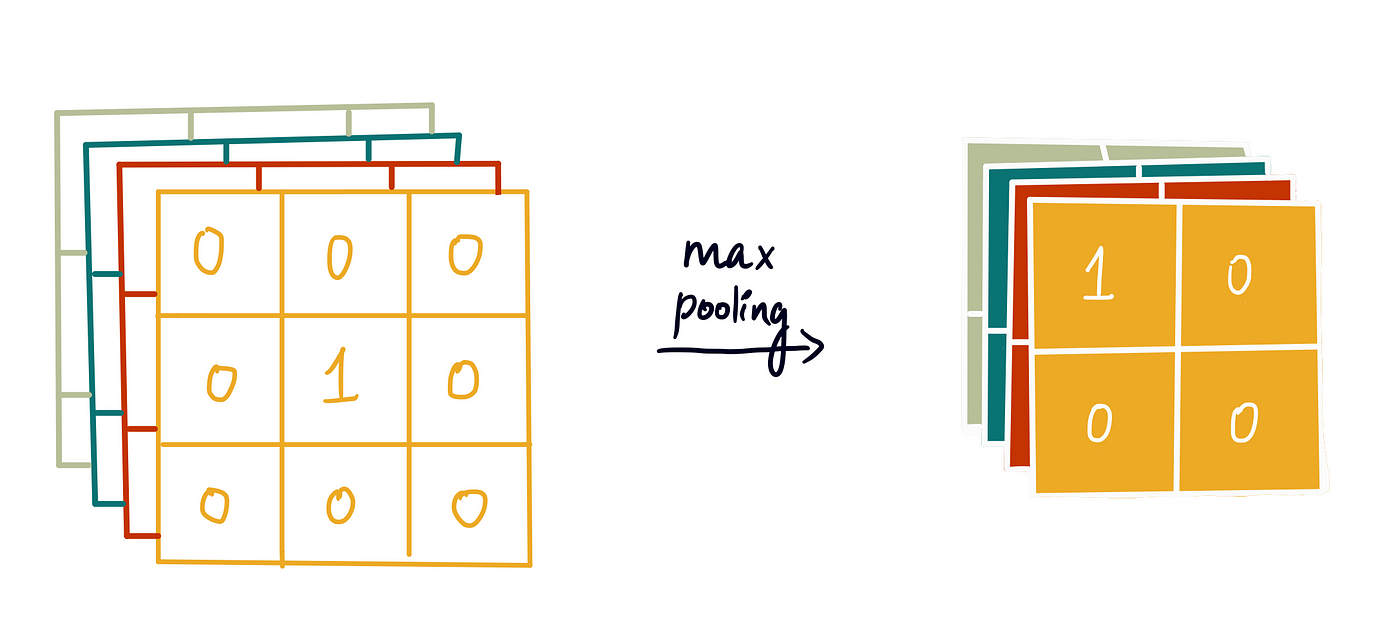
Solving a data science problem often starts with asking the same simple questions over and over again, with the occasional variation: Is there a relationship here? Do these data points belong together? What about those other ones over there? How do the former relate to the latter?
Things can (and do) become complicated very quickly—especially when we try to detect subtle patterns and relationships while dealing with large datasets. This is where Clustering algorithms come in handy with their power to divide a messy pile of data into distinct, meaningful groups, which we can then leverage in our analyses.
To help you on your clustering learning journey, we’ve selected our best recent articles on the topic—they cover a lot of ground, from basic concepts to more specialized use cases. Enjoy!
- The fundamentals of k-means clustering. Whether you’re brand new to machine learning or a veteran in need of a solid refrehser, Jacob Bumgarner‘s introduction to the most widely used centroid-based clustering method is a great place to start.
- An accessible guide to density-based clustering. Once you’ve mastered k-means clustering and are ready to branch out a bit, Shreya Rao is here to help with a clearly explained guide to DBSCAN (Density-Based Spatial Clustering of Applications with Noise), an algorithm that "requires minimum domain knowledge, can discover clusters of arbitrary shape, and is efficient for large databases."
- How to put an algorithm to good use. Feeling inspired to apply your clustering knowledge to a concrete problem? Lihi Gur Arie, PhD‘s new tutorial is based on k-means clustering; it patiently walks readers through the steps of identifying and quantifying objects in an image based on their color.
- Clustering methods meet renewable energy. In the real world, it’s not always self-evident which clustering approach works best for a given use case. Abiodun Olaoye looks at a number of algorithms—k-means, agglomerative clustering (AGC), Gaussian mixture models (GMM), and affinity propagation (AP)—to determine which one is the most effective at discovering wind-turbine neighbors.
- How to choose the right density-based algorithm. Deciding which model is the best one to use with your dataset can sometimes hinge on small, nuanced differences. Thomas A Dorfer presents one such example by comparing the performance of DBSCAN to that of HDBSCAN, its more recent sibling, and shows us how to look at the pros and cons of different clustering options.
Ready for a few more standout articles on other topics? Here’s a human-made cluster we’re thrilled to share:
- Every new installment in Adrienne Kline‘s Statistics Bootcamp series is a cause for celebration, and the latest—on type I and II errors—is no exception.
- We were thrilled to publish a new deep dive by Joseph Rocca and Baptiste Rocca: they patiently explain the inner workings of diffusion probabilistic models.
- "If left to their own devices, people will find remarkable ways of foiling your data collection intentions." Cassie Kozyrkov stresses the importance of mastering the art of data design.
- How can we address the gap between deep learning architectures and relational databases? Gustav Šír shares a thought-provoking proposal that can have far-reaching consequences.
- Don’t succumb to the sunk-cost fallacy – Sarah Krasnik‘s latest post provides a helpful roadmap for deprecating and bidding farewell to under-used and unused dashboards.
As the year draws to a close, we’re as grateful as ever for our readers’ support. If you’d like to make the biggest impact, consider becoming a Medium member.
Until the next Variable,
TDS Editors