Data is the backbone for every data project; data analysis, machine learning model training, or a simple dashboard need data. Thus, acquiring the data that satisfies your project is important.
However, it is not necessarily the data you want is exists or is available in public. Moreover, there are times you want to test your data project with "Data" that meet your criteria. That is why generating your data become important when you have certain requirements.
Generate data might be important, but collecting data manually that meets our needs would take time. For that reason, we could try to synthesize our data with programming language. This article will outline my top 3 python package to generate synthetic data. All the generated data could be used for any data project you want. Let’s get into it.
1. Faker
Faker is a Python package developed to simplify generating synthetic data. Many subsequent data synthetic generator python packages are based on the Faker package. People love how simple and intuitive this package was, so let’s try it ourselves. For starters, let’s install the package.
pip install FakerTo use the Faker package to generate synthetic data, we need to initiate the Faker class.
from faker import Faker
fake = Faker()With the class initiated, we could generate various synthetic data. For example, we would create a synthetic data name.
fake.name()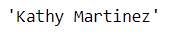
The result is a person’s name when we use the .name attribute from the Faker class. Faker synthetic data would produce randomly each time we run the attribute. Let’s run the name one more time.
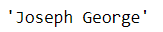
The result is a different name than our previous iteration. The randomization process is important in generating synthetic data because we want a variation in our dataset.
There are many more variables we could generate using the Faker package. It is not limited to the name variable – the other example are address, bank, job, credit score, and many more. In the Faker package, this generator is called Provider. If you want to check the whole standard provider, community provider, and localized provider, you could check it out in their documentation.
2. SDV
SDV or Synthetic Data Vault is a Python package to generate synthetic data based on the dataset provided. The generated data could be single-table, multi-table, or time-series, depending on the scheme you provided in the environment. Also, the generated would have the same format properties and statistics as the provided dataset.
SDV generates synthetic data by applying mathematical techniques and machine learning models such as the deep learning model. Even if the data contain multiple data types and missing data, SDV will handle it, so we only need to provide the data (and the metadata when required).
Let’s try to generate our synthetic data with SDV. First, we need to install the package.
pip install sdvFor our sample, I would use the Horse Survival Dataset from Kaggle because they contain various datatype and missing data.
import pandas as pd
data = pd.read_csv('horse.csv')
data.head()
Our dataset is ready, and we want to generate synthetic data based on the dataset. Let’s use one of the available Singular Table SDV models, GaussianCopula.
from sdv.tabular import GaussianCopula
model = GaussianCopula()
model.fit(data)The training process is easy; we need only to initiate the class and fit the data. Let’s use the model to produce synthetic data.
sample = model.sample(200)
sample.head()
With the .sample attribute from the model, we obtain the randomized synthetic data. How much data you want depends on the number you pass into the .sample attribute.
You might realize that the data sometimes contains a unique identifier. For example, I could assign the identifier in the above dataset as the ‘hospital_number.’ The data here above have multiple instances of ‘hospital_nunber,’ which is something we don’t want if it is unique data. In this case, we could pass the primary_key parameter to the model.
model = GaussianCopula(primary_key='hospital_number')
model.fit(data)The sample result would be a unique primary key for each sample generated from the model.
Another question we might ask is, how good is the generated synthetic data? In this case, we could use the evaluate function from SDV. This evaluation would compare the real dataset with the sample dataset. Many tests are available, but we would only focus on the Kolmogorov–Smirnov (KS) and Chi-Squared (CS) tests.
from sdv.evaluation import evaluate
evaluate(sample, data, metrics=['CSTest', 'KSTest'], aggregate=False)
KSTest is used to compare the continuous columns, and CSTest compares the discrete columns. Both tests result in a normalized score between 0 to 1, with the target is to maximize the score. From the result above, we can assess that the discrete sample columns are good (almost similar to the real data). In contrast, continuous columns might have a deviation in distribution. If you want to know all the evaluation methods available in SDV, refer to the documentation page.
3. Gretel
Gretel or Gretel Synthetics is an open-source Python package based on Recurrent Neural Network (RNN) to generate structured and unstructured data. The python package approach treats the dataset as text data and trains the model based on this text data. The model would then produce synthetic data with text data (we need to transform the data to our intended result).
Gretel required a little bit of heavy computational power because it is based on the RNN, so I recommend using free google colab notebook or Kaggle notebook if your computer is not powerful enough. For accessibility purposes, this article would also refer to the tutorial provided by Gretel.
The first thing we need to do is install the package using the following code.
pip install gretel-syntheticsWe would then use the following code to generate a config code as a parameter to train the RNN model. The following parameter is based on the training on GPU, and the dataset used is the scooter journey coordinates dataset available from Gretel.
from pathlib import Pathfrom gretel_synthetics.config import LocalConfig# Create a config for both training and generating dataconfig = LocalConfig(# the max line length for input training
max_line_len=2048, # tokenizer model vocabulary
datavocab_size=20000, # specify if the training text is structured, else ``None``
sizefield_delimiter=",", # overwrite previously trained model checkpoints
overwrite=True,# Checkpoint location
checkpoint_dir=(Path.cwd() / 'checkpoints').as_posix(),#The dataset used for RNN training
input_data_path="https://gretel-public-website.s3-us-west-2.amazonaws.com/datasets/uber_scooter_rides_1day.csv" # filepath or S3)We will train our RNN model using the following code when the config is ready.
from gretel_synthetics.train import train_rnntrain_rnn(config)Depending on your processing power, the config, and the dataset, the process might take some time. When it’s done, the config would automatically save your best model and be ready to generate synthetic data. Let’s try to generate the data using generate_text.
from gretel_synthetics.generate import generate_text#Simple validation function of the data is containing 6 data parts or not. You could always free to tweak it.
def validate_record(line): rec = line.split(", ")
if len(rec) == 6:
float(rec[5])
float(rec[4])
float(rec[3])
float(rec[2])
int(rec[0])
else:
raise Exception('record not 6 parts')#Generate 1000 synthetic data
data = generate_text(config, line_validator=validate_record, num_lines=1000)print(data)
The generated data, by default, is a generator object that contains all the synthetic data. We could try to iterate the object values and print the result to access the data.
for line in data:
print(line)Let’s take a look closely at the generated synthetic data.
line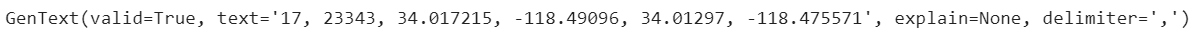
The above image is the synthetic data example from the Gretel RNN model. The text parameter is our data is in the form of text data. If we want to access it, we could use the .text attribute.
print(line.text)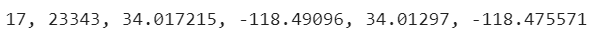
Hence we only need to split the data by the delimiter (‘, ‘) and process it to the tabular form. Although, not all the data might be valid (depending on your evaluation) and need to be cleaned thoroughly before using it.
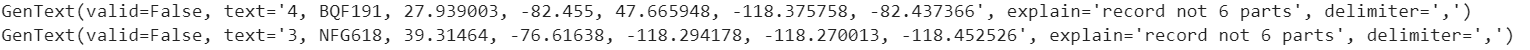
The data above are not valid because they produce more than six parts of data while we only need 6. This is why we need to be careful of the data produced by the RNN model. However, the useability outweighs the cons, so a little work should be fine if you use Gretel.
Get ready to learn Data Science from all the experts with discounted prices on 365 Data Science!
Get ready for a Data Science Summer – 65% Off | 365 Data Science
Conclusion
Data is the backbone of any data project, but sometimes the data we want is not available or hard to meet our requirements. That is why we could use the Python package to generate synthetic data. This article explains 3 top Python packages for generating data, they are:
- Faker
- SDV
- Gretel
I hope it helps!
Visit me on my Social Media.
If you are not subscribed as a Medium Member, please consider subscribing through my referral.