Introduction
This week, I decided I would like to learn more about working with text, starting by building some wordclouds based on Newspaper data. At the same time, I wanted to improve my knowledge of collecting data and saving it to a database.
My main goal here was to get and save some interesting data I could work with. I thought newspaper articles for the months of 2020 could be interesting to see the main subjects in the news each month.
Initially, I looked at different newspaper archives out there for articles. There are many great ones, but not many I could find that offer an API. I discovered that the New York Times does have an API with data related to their articles.
This is an article that documents my learning journey, getting the data from the API and saving it to a SQLite DB.
About the APIs
The APIs are accessible at https://developer.nytimes.com/apis
I found the documenation for the APIs (including the FAQ at https://developer.nytimes.com/faq) very good for getting started.
There are a number of different APIs available from the New York Times, including the Books API, which has information on best sellers lists and book reviews, the Film API, for film reviews, and the Community API, which has information on user generated content such as comments.
In this article, I am using the Archive API (https://developer.nytimes.com/docs/archive-product/1/overview). If you pass a year and month to the API, it returns that month’s article data. The article data tells us many things, including where the full article is available on the NYT website, when it was published, its headline and its lead paragraph.
Getting access
The first step to using the API is to set up an account and get access (https://developer.nytimes.com/get-started)
Requirements
I used Requests, sqlite3, and time.
Steps
There are three steps I go through here. I:
- Connect to the API to explore the data available and see what data I want to save.
- Build a database table based on the data I want to save.
- Get data for each month of the year and save to the DB.
Exploring the data
Here, I import what I will use. Requests will be to call the API, sqlite3 for interacting with the database and time so the script can be directed to sleep between calls. The docs recommend 6 seconds between calls to avoid hitting limits.
import requests
import sqlite3
import timeIn this line, I make an initial request to see what the data looks like. The API key generated in your New York Times API account would go in the [YOUR API KEY] placeholder. Authentication with this API is very straightforward
data_2020_01 = requests.get("https://api.NYTimes.com/svc/archive/v1/2020/1.json?api-key=[YOUR API KEY]")The Archive API returns the data as a JSON response. This information is given on the API website, but it is also possible to check the requests response headers to see what content type has been returned. It is "application/json":

Knowing this, I can use Requests’s own JSON decoder to convert the response to a Python dictionary:
data_2020_01_json = data_2020_01.json()Priting the data shows it is a dictionary. The articles themselves are contained in a list within a dictionary:

data_2020_01_articles = data_2020_01_json['response']['docs']The list has a length of 4480, meaning it has this number of articles:

To explore one article, I take a number in the list up to 4480 to see it. For example, article at position 10:
data_2020_01_articles[10]There is a lot of information about the article – things like its web_url, the lead_paragraph, which section it was in (section_name) and when it was published (pub_date)

I want to save the headline, the lead_paragraph, and the published date to start with. I think the type_of_material might also be interesting, along with the word_count, the main headline, the print_page, the news_desk and the section_name.
The database
There are many options for the database. Here I use Sql lite. A major advantage of this is I can easily create it and interact with it in python. I worked using the documentation at: https://docs.python.org/3/library/sqlite3.html
Structuring the database
I want to save every article returned as a row in our database and have a column for each of the fields mentioned above (i.e. main headline, the print_page, the news_desk etc.,)
The specific columns I am creating:
_id (this will be a unique ID for the article. One is returned by the API for each article), web_url, main_headline, pub_date, news_desk, section_name, type_of_material, word_count.
Creating the DB and table
Connecting and create the DB directly with python:
connection = sqlite3.connect('nytimes_articles.db')Creating a cursor object so I can start executing queries:
cur = connection.cursor()Using the cursor’s execute method to create the table:
cur.execute('''CREATE TABLE articles(_id TEXT, lead_pargraph TEXT, web_url TEXT, main_headline TEXT, pub_date TEXT, news_desk TEXT, section_name TEXT, type_of_material TEXT, word_count INT)''')Saving the data
So, I wanted to get data for every month of the year. Earlier, I got data for one month to explore the structure of the data, but now I need to write a function to get data for each month and then save each month to the database just created.
Here, I write a function to generate a URL for each month I want to get data for.
def generate_urls():
month_range = range(1,13)
api_key = "[YOUR API KEY]"
urls = []
for month in month_range:
url = (f"https://api.nytimes.com/svc/archive/v1/2020/{month}.json?api-key={api_key}")
urls.append(url)
return urlsI am going to loop through the list of urls I want to go to (returned by the above function, go to each url, and with the data returned for each month, loop through the list of articles. I then add the values for each row I want in the DB as a tuple and then store each tuple in a list. After completing each month I write those to the DB.
It is important that the data is saved in the tuple in the same order of the columns in the database – that is: _id, lead_paragraph, web_url, main_headline, pub_date, news_desk, section_name, type_of_material, word_count
month_urls = generate_urls()for month in month_urls:
data = requests.get(month)
data_json = data.json()
data_articles = data_json['response']['docs']
values_for_db = []for article in data_articles:
row = (article['_id'], article['lead_paragraph'], article['web_url'], article['headline']['main'], article['pub_date'], article['news_desk'], article['section_name'], article['type_of_material'], article['word_count'])
values_for_db.append(row)
cur.executemany('INSERT INTO articles VALUES (?,?,?,?,?,?,?,?,?)', values_for_db)
time.sleep(6)
connection.commit()connection.close()The data
I used DB Browser for SQLite to view the article data. Here, I can see easily what has been saved. Data for 55,493 articles:
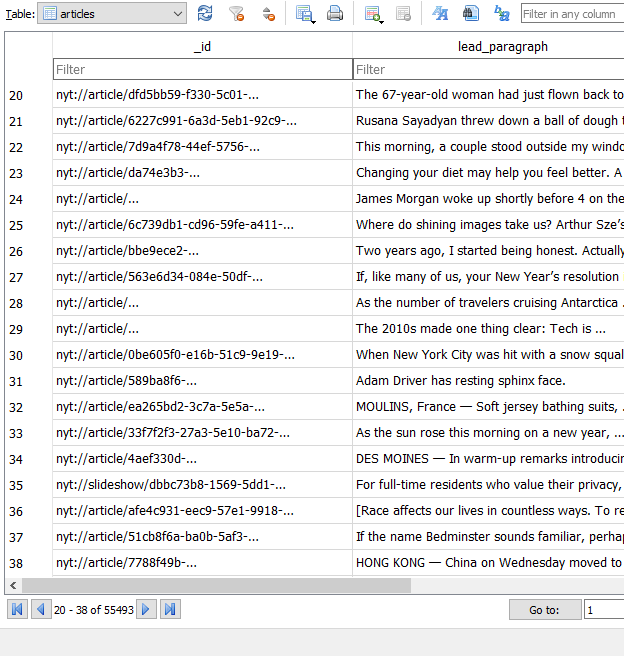
I found working with this API very straightforward and it has so much interesting information about articles that have appeared in the New York Times. Though there is no full article text provided by the API, the lead_paragraph field should be a decent indicator of what is mentioned throughout each article. I plan to perform named-entity recognition on the text before visualising it in wordclouds for the year. It might also be interesting data to use for sentiment analysis.
The introductory image is a photo by Stéphan Valentin on Unsplash. All other images are taken by the author. The code used in this article can be found here: