Imagine you’re a data scientist at a large multi-national bank and the Chief Customer Officer approaches you to develop a means of predicting customer churn. You develop a snapshot dataset of 10,000 customers with class imbalance of 1:4 in favour of customers not leaving to use to train such a binary classification model. To assist in model development, you decide to investigate various sampling techniques that might help with the class imbalance.

This multi-part series will cover the following topics in the process of developing and explaining a model, with a focus on translating model output to business outcomes and communicating to senior stakeholders.
- Part 1 Model Development for Imbalanced Classification
- Part 2 Threshold Analysis and Cost Impacts
- Part 3 Explainable ML with DALEXtra & Tidymodels
- Part 4 Alternative Approach Using Survival Analysis
The end goal is to create a model that enables the bank to target current customers that might be classified as churning and apply some intervention to prevent that churn. Interventions come at a cost so we’ll seek to balance the false negative rate against the false positive rate. We’ll develop a cost function and threshold analysis in Part 2 with the probably package.
Part 3 will focus on understanding the variable space where churn is more predominant in and enable us to understand at local and global levels the leading factors that lead to customer churn by using the DALEX/DALEXtra XAI packages.
In Part 4 we will take a different approach and apply survival analysis methods to this dataset as it is right censored and features time to event (Tenure) and outcome utilising the recently published survival analysis features in tidymodels.
Load Packages
library(tidymodels)
library(themis) #Recipe functions to deal with class imbalances
library(tidyposterior) #Bayesian Resampling Comparisons
library(baguette) #Bagging Model Specifications
library(corrr) #Correlation Plots
library(readr) #Read .csv Files
library(magrittr) #Pipe Operators
library(stringr) #String Manipulation
library(forcats) #Handling Factors
library(skimr) #Quick Statistical EDA
library(patchwork) #Create ggplot Patchworks
library(GGally) #Pair Plotsoptions(yardstick.event_first = FALSE) #Evaluate second factor level as factor of interest for yardstick metricsLoad Data
Data is taken from https://www.kaggle.com/shivan118/churn-modeling-dataset (License CC0: Public Domain) and loaded as below.
train <- read_csv("Churn_Modelling.csv") %>%
select(-c(Surname, RowNumber, CustomerId))Exploratory Data Analysis
I like the skimr package to quickly provide a summary of all dataset variables.
skim(train)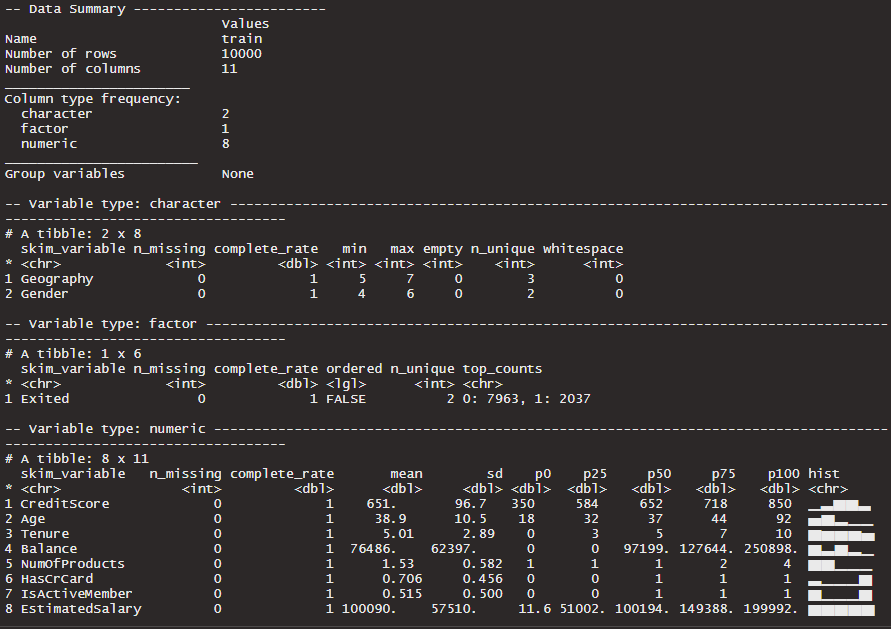
Our target variable, Exited has an approximate 4:1 ratio between two possible outcomes where Exited = 1 refers to customer churn. To visualise this we take the custom function below.
viz_by_dtype <- function (x,y) {
title <- str_replace_all(y,"_"," ") %>%
str_to_title()
if ("factor" %in% class(x)) {
ggplot(train, aes(x, fill = x)) +
geom_bar() +
theme_minimal() +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1),
axis.text = element_text(size = 8)) +
scale_fill_viridis_d()+
labs(title = title, y = "", x = "")
}
else if ("numeric" %in% class(x)) {
ggplot(train, aes(x)) +
geom_histogram() +
theme_minimal() +
theme(legend.position = "none") +
scale_fill_viridis_d() +
labs(title = title, y = "", x = "")
}
else if ("integer" %in% class(x)) {
ggplot(train, aes(x)) +
geom_histogram() +
theme_minimal() +
theme(legend.position = "none") +
scale_fill_viridis_d()+
labs(title = title, y = "", x = "")
}
else if ("character" %in% class(x)) {
ggplot(train, aes(x, fill = x)) +
geom_bar() +
theme_minimal() +
scale_fill_viridis_d() +
theme(legend.position = "none",
axis.text.x = element_text(angle = 45, hjust = 1),
axis.text = element_text(size = 8)) +
labs(title = title, y ="", x= "")
}
}
variable_list <- colnames(train) %>% as.list()
variable_plot <- map2(train, variable_list, viz_by_dtype) %>%
wrap_plots(
ncol = 3,
heights = 150,
widths = 150)
ggsave("eda.png", dpi = 600)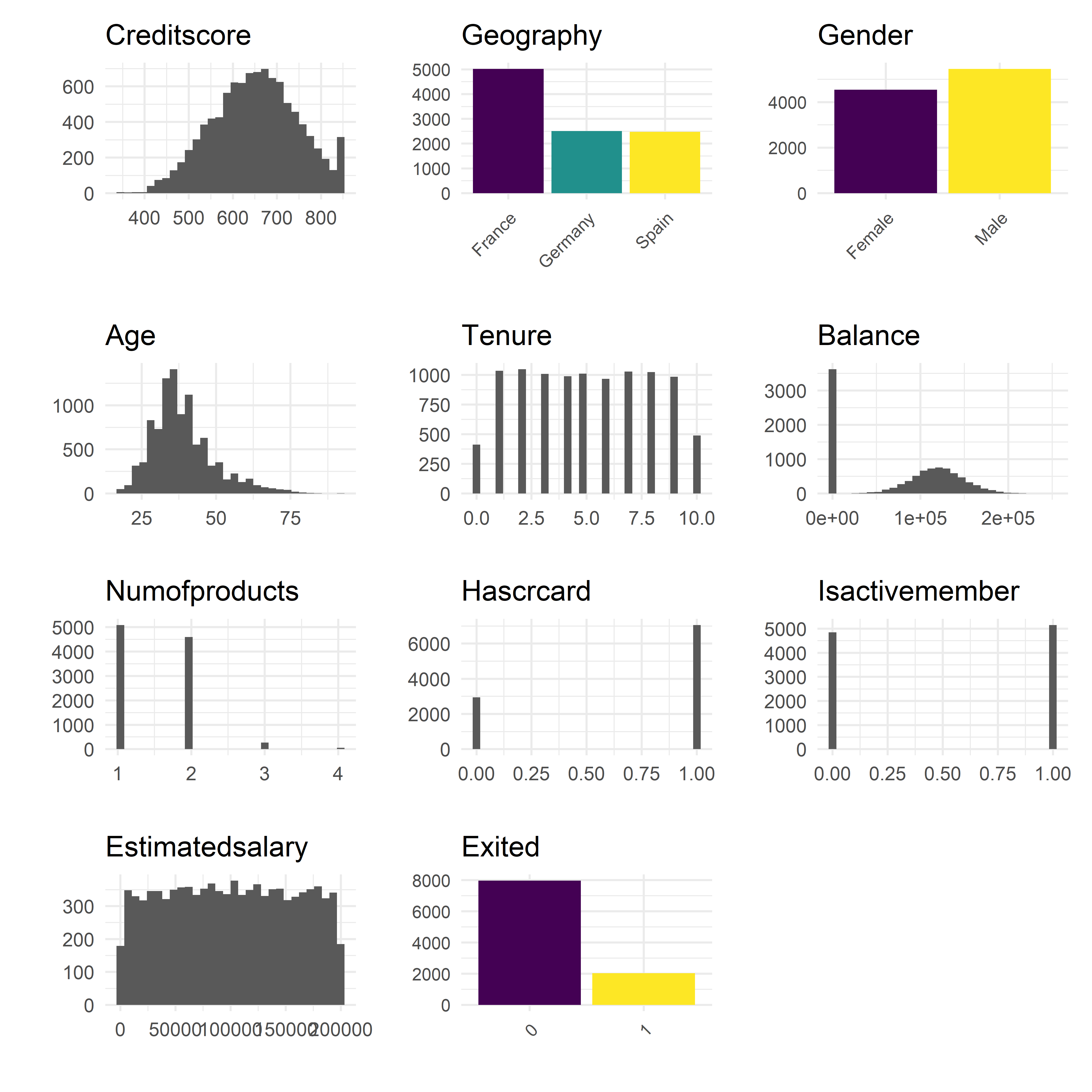
From the above we get a better understanding of the distribution of continuous variables and counts of discrete variables.
- Credit Score is approximately normally distributed
- Geography is split across three countries, with France being predominant
- Gender is almost evenly split
- Age is approximately right-skewed normally distributed
- Tenure has no apparent distribution, with the bulk of customers staying between 2–9 years
- Balance is normally distributed with a large number of customers with a zero balance
- Most customers either have 1 or 2 products
- Has Credit Card indicates 70% of customers have a credit card
- Is Active Member shows that 51.5% of customers are active users
- Estimated Salary shows no apparent distribution
Bivariate Numeric Analysis
Now we’ll seek to understand if there is any relationship between numeric variables using the GGally::ggpairs()
ggpairs(train %>%
select(-c(HasCrCard,IsActiveMember,NumOfProducts, Gender, Geography)) %>%
drop_na() %>%
mutate(Exited = if_else(Exited == 1, "Y","N")), ggplot2::aes(color = Exited, alpha = 0.3)) +
scale_fill_viridis_d(end = 0.8, aesthetics = c("color", "fill")) +
theme_minimal() +
labs(title = "Numeric Bivariate Analysis of Customer Churn Data")
Only thing worth noting in the above is the rightward shift of customers who have churned, indicating older customers may have a greater likelihood of leaving.
Categorical Variable Analysis
Next step is to establish if there are any relationships between the categorical variables and target.
The below describes the creation of a summary dataframe that calculates the mean and 95% confidence interval for each categorical variable and the target variable.
train %>%
mutate(Exited = if_else(Exited == 1, "Y", "N"),
HasCrCard = if_else(HasCrCard == 1, "Y", "N"),
IsActiveMember = if_else(IsActiveMember == 1, "Y", "N"),
NumOfProducts = as.character(NumOfProducts)) %>%
select(Exited,where(is.character)) %>%
drop_na() %>%
mutate(Exited = if_else(Exited == "Y",1,0)) %>%
pivot_longer(2:6, names_to = "Variables", values_to = "Values") %>%
group_by(Variables, Values) %>%
summarise(mean = mean(Exited),
conf_int = 1.96*sd(Exited)/sqrt(n())) %>%
ggplot(aes(x=Values, y=mean, color=Values)) +
geom_point() +
geom_errorbar(aes(ymin = mean - conf_int, ymax = mean + conf_int), width = 0.1) +
theme_minimal() +
theme(legend.position = "none",
axis.title.x = element_blank(),
axis.title.y = element_blank()) +
scale_color_viridis_d(aesthetics = c("color", "fill"), end = 0.8) +
facet_wrap(~Variables, scales = 'free') +
labs(title = 'Categorical Variable Analysis', subtitle = 'With 95% Confidence Intervals')
Of note, we see that gender, a non-active membership, the number of products and geography show a significant different propensity to churn. Conversely, whether or not a customer has a credit card shows no significant impact on churn likelihood. This should be taken with a slight grain of salt given the class imbalance.
Model Development
Data Splitting – rsample
Using rsample::initial_split(), we specify a split of the training data 3:1.
set.seed(246)
cust_split <- initial_split(train, prop = 0.75, strata = Exited)Model Specifications – Parnsip & Baguette
We are going to constrain the range of model specifications to those that are tree based models of increasing complexity using parsnip and baguette packages (for bag_trees). Each model specifies that their respective hyperparameters are set to tune() for screening in the next step.
dt_cust <-
decision_tree(cost_complexity = tune(), tree_depth = tune(), min_n = tune()) %>%
set_engine("rpart") %>%
set_mode("classification")rf_cust <-
rand_forest(mtry = tune(), trees = tune(), min_n = tune()) %>%
set_engine("ranger", importance = "impurity") %>%
set_mode("classification")xgboost_cust <-
boost_tree(mtry = tune(), trees = tune(), min_n = tune(), tree_depth = tune(), learn_rate = tune(), loss_reduction = tune(), sample_size = tune()) %>%
set_engine("xgboost") %>%
set_mode("classification")bagged_cust <-
bag_tree(cost_complexity = tune(), tree_depth = tune(), min_n = tune()) %>%
set_engine("rpart") %>%
set_mode("classification")Feature Engineering – Recipes
Next we’ll specify the feature engineering steps using the recipes package. We will use this stage to develop 10 recipes that each have different sampling techniques to handle the class imbalance. The themis package provides recipes steps to facilitate different sampling techniques.
- SMOTE – Synthetic Minority Oversampling Technique
- ROSE – Random Oversampling Technique
- BSMOTE – Borderline Synthetic Minority Oversampling Technique
- UPSAMPLING – Add duplicate minority class data to specified ratio with majority class
- ADASYN – Adaptive Synthetic Oversampling
- TOMEK – Remove TOMEK links in Majority Class
- NEARMISS – Remove Majority Class Instances by Undersampling
- NOSAMPLING – No sampling procedure
- SMOTE-DOWNSAMPLING – Generate synthetic minority instances and remove majority instances
- ROSE-DOWNSAMPLING – Oversample minority instances and downsample majority
recipe_template <-
recipe(Exited ~., data = training(cust_split)) %>%
step_integer(HasCrCard, IsActiveMember, zero_based = T) %>%
step_integer(NumOfProducts) %>%
step_mutate(SalaryBalanceRatio = EstimatedSalary/Balance,
CreditScoreAgeRatio = CreditScore/Age,
TenureAgeRatio = Tenure/Age,
SalaryBalanceRatio = if_else(is.infinite(SalaryBalanceRatio),0,SalaryBalanceRatio)) %>%
step_scale(all_numeric_predictors(), -c(HasCrCard, Age, IsActiveMember, NumOfProducts)) %>%
step_dummy(all_nominal_predictors()) %>%
step_samplingmethod(Exited) #Change or Add Sampling Steps Here as NecessaryThe above we’ve engineered additional features taking the quotients of of the different continuous variables.
Correlation Plot – corrr
We visualise the correlation plot of the entire trained dataset, using the recipe with no sampling techniques applied.
cust_train <- recipe_8 %>% prep() %>% bake(new_data = NULL)
cust_test <- recipe_8 %>% prep() %>% bake(testing(cust_split))cust_train %>%
bind_rows(cust_test) %>%
mutate(Exited = as.numeric(Exited)) %>%
correlate() %>%
rplot(print_cor = T, .order = "alphabet") +
scale_color_gradient2(low = 'orange', high = 'light blue') +
theme(axis.text.x = element_text(angle = 90)) +
labs(title = "Correlation Plot for Trained Dataset")
Nothing surprising in the above, negative correlations between age and the derivative ratios that we generated. Exited has a positive correlation with age, slight negative correlation with the CreditScoreAgeRatio and slight positive correlation with the SalaryBalanceRatio.
Workflow Map – workflowsets
Using the workflowsets package we can generate a list of 40 workflows between the parsnip and recipes combinations AND screen 20 hyperparameter combinations for each workflow. We create a a 5-fold cross validation obect using the rsample::vfold_cv(), using the strata kwarg to Exited, such that each fold has the consistent ratio of the target variable levels.
recipe_list <-
list(SMOTE = recipe_1, ROSE = recipe_2, BSMOTE = recipe_3, UPSAMPLE = recipe_4, ADASYN = recipe_5, TOMEK=recipe_6, NEARMISS = recipe_7, NOSAMPLING = recipe_8, SMOTEDOWNSAMPLE= recipe_9, ROSEDOWNSAMPLE = recipe_10)model_list <-
list(Decision_Tree = dt_cust, Boosted_Trees = xgboost_cust, Random_Forest = rf_cust, Bagged_Trees = bagged_cust)wf_set <-
workflow_set(preproc = recipe_list, models = model_list, cross = T)set.seed(246)
train_resamples <-
vfold_cv(training(cust_split), v = 5, strata = Exited)class_metric <- metric_set(accuracy, f_meas, j_index, kap, precision, sensitivity, specificity, roc_auc, mcc, pr_auc)doParallel::registerDoParallel(cores = 12)
wf_sample_exp <-
wf_set %>%
workflow_map(resamples = train_resamples,
verbose = TRUE,
metrics = class_metric,
seed = 246)We use the parsnip::metric_set() function to create a custom set of metrics for evaluation. These custom metrics are passed along with the wf_set object to workflow_map to screen all 40 workflows and output all of the metrics calculations for each workflow. The resulting workflow_set object wf_sample_exp can now be analysed and used for model comparisons.
This is quite computationally taxing, so I recommend firing up all available cores to ease this along.
collect_metrics(wf_sample_exp) %>%
separate(wflow_id, into = c("Recipe", "Model_Type"), sep = "_", remove = F, extra = "merge") %>%
group_by(.metric) %>%
select(-.config) %>%
distinct() %>%
group_by(.metric, wflow_id) %>%
filter(mean == max(mean)) %>%
group_by(.metric) %>%
mutate(Workflow_Rank = row_number(-mean),
.metric = str_to_upper(.metric)) %>%
arrange(Workflow_Rank) %>%
ggplot(aes(x=Workflow_Rank, y = mean, color = Model_Type)) +
geom_point(aes(shape = Recipe)) +
scale_shape_manual(values = 1:n_distinct(recipe_list)) +
geom_errorbar(aes(ymin = mean-std_err, ymax = mean+std_err)) +
theme_minimal() +
scale_color_viridis_d() +
labs(title = "Performance Comparison of Workflows", x = "Workflow Rank", y="Error Metric", color = "Model Types", shape = "Recipes") +
facet_wrap(~.metric,scales = 'free_y',ncol = 4)
The purpose of the above is to demonstrate just a sample of classification metrics that one might look at with an imbalanced dataset. We want a model that sufficiently differentiates between classes, but given our particular problem we need to minimise false negatives (customers that churn but are predicted otherwise). Part 2 discusses a cost function to find balance between cost of intervention and class differentiation.
Given class imbalance, ROC AUC and Accuracy are not appropriate metrics. We consider Precision-Recall AUC, KAP, J-Index, Mathews Correlation Coefficient and Specificity. With this in mind UPSAMPLE_Boosted_Trees is a strong candidate with good results across all these metrics.
Bayesian Model Comparison – tidyposterior
Focusing on the J-index, we can compare the resampling posterior distributions using tidyposterior. tidyposterior::perf_mod() takes the wf_sample_exp object that contains results from workflow_map and completes bayesian comparision of resamples and generates posterior distributions of the metric mean of interest. N.B the workflow_set object MUST have the target metric calculated else this will not work.
jindex_model_eval <-
perf_mod(wf_sample_exp, metric = "j_index", iter = 5000)
jindex_model_eval %>%
tidy() %>%
mutate(model = fct_inorder(model)) %>%
separate(model, into = c("Recipe", "Model_Type"), sep = "_", remove = F, extra = "merge") %>%
ggplot(aes(x=posterior, fill = Model_Type)) +
geom_density(aes(alpha = 0.7)) +
theme_minimal() +
scale_fill_viridis_d(end = 0.8) +
facet_wrap(~Recipe, nrow = 10) +
labs(title = "Comparison of Posterior Distributions of Model Recipe Combinations",
x = expression(paste("Posterior for Mean J Index")),
y = "")
There is a lot to unpack in the above, but in short, it demonstrates the impact of the sampling procedure to handle class imbalance and effect on J-Index. This can be completed for any metric and I think is a useful exercise to explore impact of different up- and downsampling procedures. The sampling procedure should be treated like a hyperparameter and the ideal will be different depending on the nature of the dataset, feature engineering and the metrics of interest. We note that boosted trees performs generally well, alongside the bagged tree methods all depending on the sampling procedure.
Concluding Remarks
We have demonstrated the model development process for a binary classifier with a 4:1 imbalanced dataset. Our best performing workflow features an XGBoost model with an upsampling procedure to level the ratio of classes. In Part 2 we will fit the model and complete decision threshold analysis using the probably package and develop two scenarios – either change the decision threshold to minimise cost of churn and intervention OR enables better class differentiation. Part 2 will focus heavily on translating the model output to business stakeholders and enable them to make an informed decision around cost and risk of customer churn.
Thankyou for reading and please keep an eye out for the subsequent parts. I hope you enjoyed reading this as much as I enjoyed writing. If you’re not a Medium member – use my referral link below and get regular updates on new publications from myself and other fantastic Medium authors.







