Hacking the constraints
Databricks has became an important building block in Cloud Computing, especially now, after Google announces the launch of Databricks on Google Cloud. However, it must be said that it is still an experimenting technology, with a long way to go in terms of efficiency and coverage.
R is one of the most powerful-and-employed languages and environments for Data Science, years and years of statistical folks working hard on developing different libraries. Thanks to that, one can find almost any mathematical model implemented with R, which is quite useful to success in most DS projects you can imagine. However, R has an important drawback: BigData. SparkR and other formulas are still far away to provide a huge catalog of ML libraries when working with massive data. Most BigData SaaS and PaaS are focused on Python and Spark, such as Databricks, making efforts to develop a complete framework and trying to define the end-to-end cycle of a ML artifact, rather than paying attention to completely support their products in R.
This happens, for example, when using MLFlow for R models within Databricks. It is true that Databricks supports both R, Python and Scala codes, but different weaknesses are found when working with MLFlow and R, specifically when trying to register a ML model.
What MLFlow is
MLFlow is a ML platform built around REST APIs which allows to record instances of ML models as a repository. These instances are packaged in order to be sent to a deploy tool, but it also register the different metrics, data around the model, config or code versions when running your experiments. Later you can visualize them and compare the output of multiple runs.

If you are not familiar with MLFlow, please take a look at their documentation and try a free trial with Databticks.
MLFlow is currently in alpha, reason why it has still weaknesses, but it is a powerful idea to keep in mind when thinking in deploying our ML models.
How MLFlow works on Python/Spark
Let’s see a quick example of MLFlow on Python. First, we have to install and load the libraries:

After this, we must create or set the experiment using the following command: _mlflow.set_experiment(path_toexperiment). Before registering any experiment, we can go to the given path and we will see that the experiment was created but it is empty:

Then, we can run our model and register the execution in our experiment:

With autolog() we automatically log all parameters, scores and the model itself, but if we do not want to keep track of the whole context, we can select what to save with _log_metric(), log_param(), logartifact() or _logmodel() functions. Actually, I find really interesting the _logmodel function, as it allows us to track the model together with a label, which can help us to load the model later from the repository. Check the doc here.
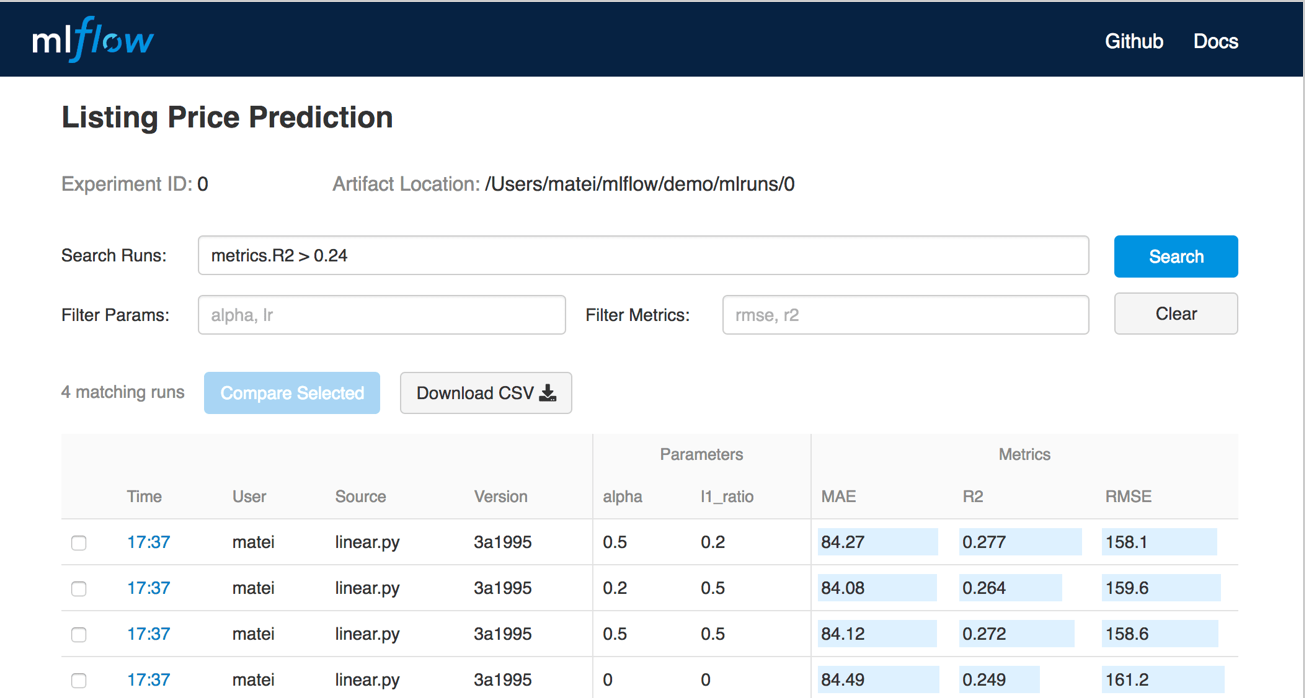
After this, if you go to the experiments path now, you will see the record of all experiments you have logged. Something like this:

Once the model is trained and logged, it can be propagated from None to Staging and to Production stages (look for the _transition_model_versionstage() function) in the model repository. In Databricks, the repository can be visualized in the "Models" tab:
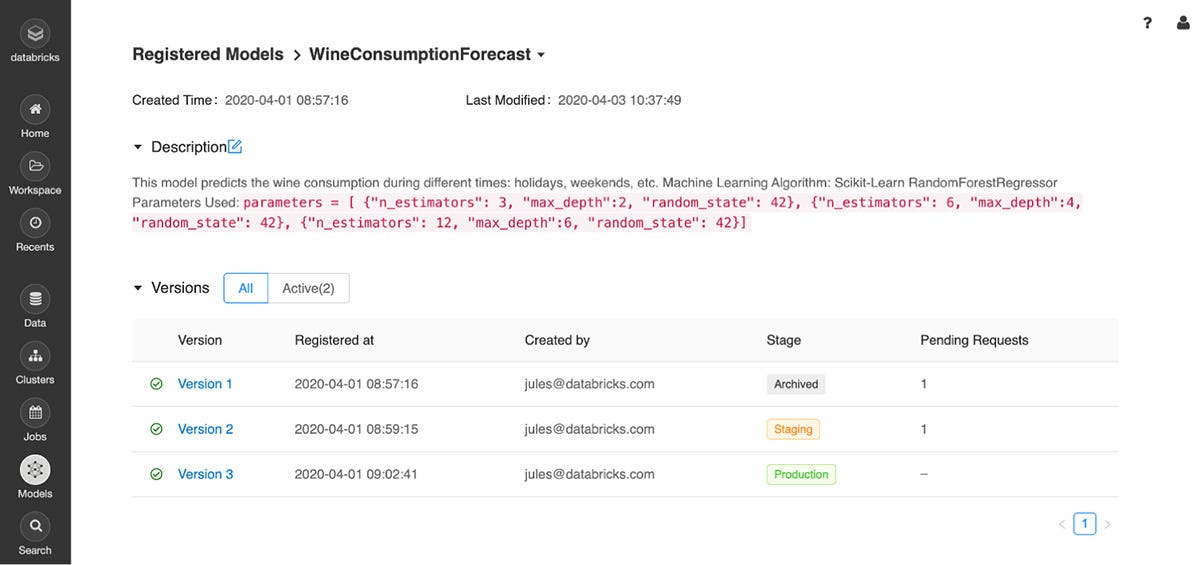
Then, it can be easily loaded from the repository to be used in our predictions. One just has to call the _mlflow.load_model(path_tomodel) instruction to use the desired model within a notebook.
Trying to use the R API of MLFlow in Databricks
Following the same structure as the Python flow, we firstly load the libraries and install mlflow:

The first difference appears when setting the experiment. In R, we cannot set an experiment that does not exist; so it is mandatory to use a try-catch to capture the error, just-in-case, and create the experiment if needed. After that, let’s try to run the execution and log the model:

Now, if we check the experiment path we will see that the experiment and the run were created; however, no model was tracked in the repository. This is surprising, since no error was returned. Most people are here stuck, and MLFlow has to work on this, but here the reason:
The _registered_modelname (‘predictorLDA’ in our example) is a useful parameter to use within _mlflow.logmodel, unfortunately is not currently available in the R library.
This is a pain in the neck if we want to load MLFlow models in our R notebooks, but there is a solution. At any Databrick notebook, you can override the default language by specifying the language magic command %<language> at the beginning of a cell. The supported magic commands are: %python, %r, %scala, and %sql. The solution passes through calling to python (or use the REST API) from the R notebook:

We first set the experiment we have created in the previous R commands, and then we look for the last run of that experiment. Remember that both the experiment and the run were registered in R, the only thing we were no able to track was the model. Once we have found the run, we can get the URI of the created artifact and we will use this URI to get the model in python and register it. We just create a mlflow client to do the registration with the _create_modelversion instruction. This operation can take up to 300 seconds to finish the creation, so keep it in mind (it could be interesting to use a time.sleep(300) in the next command). Now, after this "trick" the model has been correctly registered in the Model repository and it is ready to be used.
Both Databricks and MLFlow are powerful and promising technologies that are being developed. Especially MLFlow is still too green, so we must be patient. In the meantime, I hope this trick can help you with your cloud deploys.
Adrian Perez works as Data Scientist and has a PhD in Parallel Algorithms for Supercomputing. You can checkout more about his Spanish and English content in his Medium profile.








{kind=link}