
Whether we deal with machine learning, operations research, or other numerical fields, a common task we all have to do is optimizing functions. Depending on the field, some go-to methods emerged:
- In machine learning when training neural networks, we usually use gradient descent. This works because the functions we deal with are differentiable (at least almost everywhere – see ReLU).
- In operations research, often we deal with linear (or convex) Optimization problems that can be solved with linear (or convex) programming.
It is always great if we can apply these methods. However, for optimizing general functions – so-called blackbox optimization – we have to resort to other techniques. One that is particularly interesting is the so-called particle swarm optimization, and in this article, I will show you how it works and how to implement it.
Note that these algorithms won’t always give you the best solution, as it is a highly stochastic and heuristic algorithm. Nevertheless, it’s a nice technique to have in your toolbox, and you should try it out when you have a difficult function to optimize!
#
In 1995, Kennedy and Eberhart introduced particle swarm optimization in their paper of the same name. The authors draw an analogy from sociobiology, suggesting that a collective movement, such as a flock of birds, allows each member to benefit from the experiences of the entire group. We will see what this means in a second.
Let us assume that you want to minimize a function in two variables, for example, f(x, y) = _x_² + _y_². Sure, we know that the solution is (0, 0) with a value of 0, and our algorithm should find this out as well. If we cannot even do that, we know that we did something completely wrong.
Static particles
We start by randomly initializing a lot of potential solutions, i.e., two-dimensional points (xᵢ, yᵢ) for i = 1, …, N. The points are called particles (birds), and the set of points is the swarm (flock). For each particle (xᵢ, yᵢ), we can compute the function value f(xᵢ, yᵢ).

We could stop here already and output the particle with the lowest value of f. This would be a random search, and it can work in low dimensions but usually gets worse in high dimensions.
Push them!
But we do not want to stop here! Instead, we start a dynamic system by giving each particle a little push in some random direction. The particles should fly in a straight line, like in outer space without gravity. We can check the positions of all particles at several timesteps, and then report the lowest value of f we have ever seen.

This is basically a random search, but then we shift the random points around a bit, so they can fly around and give us a higher coverage of the search space. You can implement it like this:
Python">def f(x): # function to minimize
return x[0] ** 2 + x[1] ** 2
def easy_push(dimension, swarm_size, n_steps):
x = np.random.normal(loc=0, scale=3, size=(dimension, swarm_size)) # initial swarm
v = np.random.normal(loc=0, scale=1, size=(dimension, swarm_size)) # initial velocities (directions)
best_position = x[:, [f(x).argmin()]]
best_value = f(x).min()
for step in range(n_steps):
x = x + v # update positions according to the push direction
new_candidate = f(x).min()
if new_candidate < best_value:
best_value = new_candidate
best_position = x[:, [f(x).argmin()]]
return best_position
print(easy_push(dimension=2, swarm_size=100, n_steps=100)) # use functionIn the matrix x, each column is the position of a particle. Similarly, each column of the other matrix v represents the direction vector of the corresponding article with the same index. The code is heavily vectorized, so it is more performant. Otherwise, we would have to write a for-loop over all particles in the swarm.
While this seems a bit better than a random search, the particles are still quite dumb— they only travel in a straight line, and we have to hope that one of them gets close to the minimum.
So far, there is no flock. Just a bunch of egoistic birds flying straight, doing their thing.
Add attraction
There are many variants of particle swarm optimization, but in each of them the particles are made a bit smarter in the following sense:
- They get a memory: each particle knows the best position it has ever found so far.
- They are aware of the swarm: each particle knows the best position any particle has ever found so far.
Now, the high-level idea is that the particles don’t only fly straight, but also move towards
- their best-known location – the locally best location -, but also
- the best-known location of the swarm – the globally best location.
You can implement this idea by changing the direction in each time step. Before in the code, the direction v stayed the same in each iteration of the loop. We set it once and then updated x = x + v . Now, we want to update v as well, for example using the following formula:
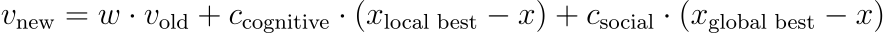
In words: the direction in the next time step consists of three components:
- a scaled (usually shorter, i.e, 0 < w < 1) version of the old direction,
- a cognitive direction that points to the locally best solution each particle has found so far, and
- a social direction that points to the globally best solution found by the entire swarm so far.
This means that each particle will slow down over time, moves to the best solution it has ever seen, but also moves to the best solution the swarm has ever seen.
You can also phrase it like this: each particle is attracted by its own best location it has ever seen, but also by the global best location. In the end, our particles will behave like this:

Here is another animation from optimizing the more difficult Rastrigin function in two dimensions:

This function has many local minima, a common problem when training neural networks. Still, our simple algorithm seems to work well here. Some particles get stuck in the wrong local minima, but many particles also gather around the global minimum in the middle, which is sufficient for a good result.
Implementation
That looks complex, but the code itself is straightforward as well if you have understood the code for the egoistic birds before. Here it is:
def simple_pso(dimension, swarm_size, n_steps, w, c_cognitive, c_social):
x = np.random.normal(loc=0, scale=3, size=(dimension, swarm_size))
v = np.random.normal(loc=0, scale=1, size=(dimension, swarm_size))
best_position_particle = x # in the beginning, the best position known for each article is its initial position
for step in range(n_steps):
best_value_particle = f(best_position_particle) # the corresponding function values for the best known positions
best_position_global = x[:, [best_value_particle.argmin()]] # global best position that attracts all particles
r = np.random.random(2) # this is new, see below
x = x + v # same as before
v = w*v + c_cognitive*r[0]*(best_position_particle - x) + c_social*r[1]*(best_position_global - x) # the direction change formula
improvement = f(x) <= best_value_particle
best_position_particle[:, improvement] = x[:, improvement] # update each particle's locally best solution
best_position_global = x[:, [best_value_particle.argmin()]]
return best_position_global
print(simple_pso(dimension=2, swarm_size=100, n_steps=100, w=0.8, c_cognitive=0.1, c_social=0.1))More randomness
Note that I introduced another source of randomness into the code. Instead of using the direction change formula from above, I use
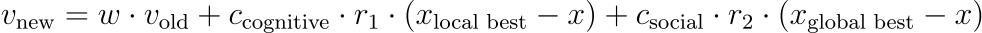
where _r_₁ and _r_₂ are random numbers between 0 and 1. You can also use matrices, and not just single numbers, but let us keep it simple here. Many authors use such an additional form of randomness, but I could not figure out why this is the case. If you know, drop me a message!
Conclusion
In this article, we have seen how to implement a simple form of particle swarm optimization. As with other nature-inspired algorithms such as evolutionary algorithms, the algorithm is heuristic and not guaranteed to find the global optimum of a function. Still, in practice, the results can be fantastic.
The algorithm starts by scattering a bunch of particles, giving them a little push, and letting them interact with each other. This results in a seemingly complex dynamic system that is luckily easy to describe in formulas.
Spread out the particles!
A word of caution: if your particles are not scattered enough in the beginning, the algorithm might fail miserably. In the following picture, the initial positions of all particles are far away from the true global minimum in the middle.

There might be ways to improve our algorithm to handle cases like this, but I suggest spreading out the particles as much as possible, so the minimum that you search for is likely to be within your initial swarm.
I hope that you learned something new, interesting, and valuable today. Thanks for reading!
If you have any questions, write me on LinkedIn!
And if you want to dive deeper into the world of algorithms, give my new publication All About Algorithms a try! I’m still searching for writers!







