Thoughts and Theory
UT Austin physics grad student Chris Roth tackles exotic quantum problems with the power of symmetry.
The laws of quantum mechanics, infamous for being unintuitive, predict a litany of strange effects. Many exotic materials, such as superconductors, have such complicated behavior that even the most powerful computers cannot handle their calculations [1]. As a result, some systems must be conquered through innovative, large-scale simulations [2]. UT Austin researcher Chris Roth has developed a machine-learning algorithm that uses two symmetries to make this problem more tractable [3]. First, his periodic system finds an analog in the input structure. Second, the forces between the particles conveniently obey a type of dependence characteristic of the output of the algorithm.
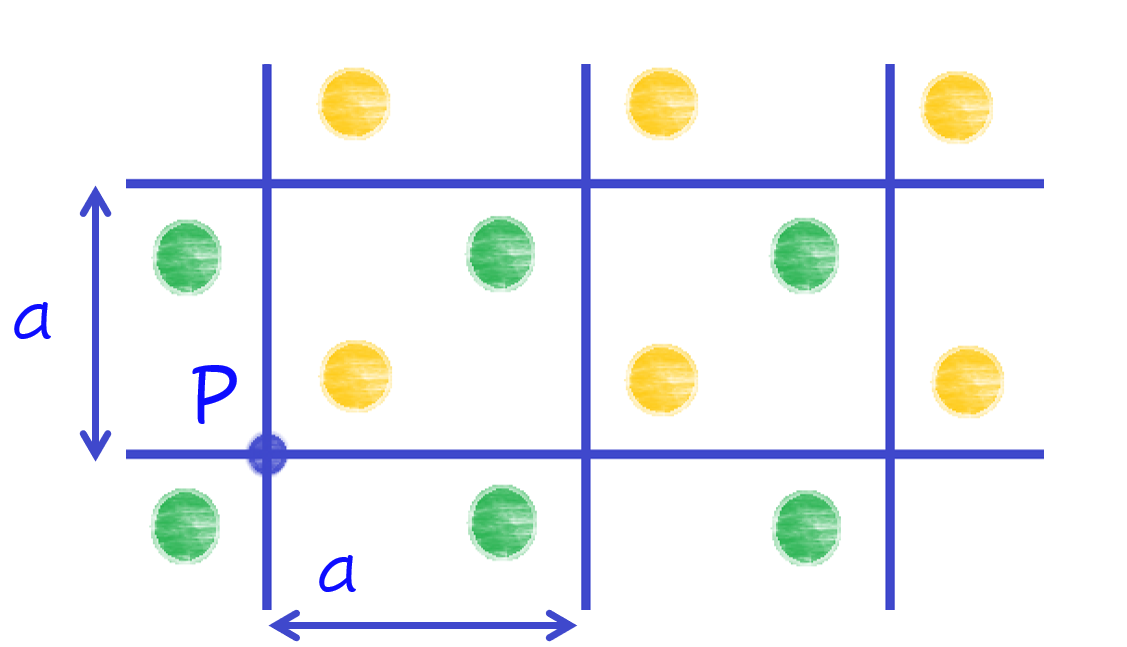
The concept of symmetry constantly appears in physics; it simplifies problems and highlights relationships between different properties. To quote pioneering quantum physicist, Philip Anderson: "it is only slightly overstating the case to say that physics is the study of symmetry." It can take many forms, such as two sides of a leaf being reflections of each other or cyclical patterns in time. Crystals are defined by exhibiting symmetry: as you move through a material in discrete steps you will find the same local environment anywhere. This is called "translational invariance" and is displayed in Figure 1.
In solids, the positively-charged nuclei are fixed in a periodic pattern, and the electrons are more or less free to roam. Consequently, simulations only focus on modeling the interactions between the electrons [4]. The Coulomb force causes like-charged particles to repel each other and doesn’t depend on electrons’ exact locations, but rather the distance between them. This property of only caring about relative distances instead of exact positions also appears in recurrent neural networks (RNN), a type of Machine Learning algorithm. In the case of an RNN, however, the distance is between the index of input steps, not actual space. Input is broken up into discrete, sequential pieces, and each piece is encoded to produce its own output. RNN’s allow earlier input to be passed forward to inform the outcome, so that the final output depends on all the input [5]. The process is demonstrated in Figure 2. The three colored circles represent this "hidden state,” the step between the input and output. In this example, there are three pieces of input, indexed 1–3. Input 1 (i1) is fed to the algorithm, which will be specific to the question the RNN is trying to solve. Then, i2 and the previous hidden state are fed to the algorithm. They produce o2, which is even more informed. This will propagate for many steps until all the input has been considered. In this drawing, there is only one more step, producing the final output, o3.

As the drawing depicts, not all input matters equally- the most recent input weighs most heavily on the output. This is known as "short-term memory loss," and the way RNN’s are built causes this effect. Models are trained on datasets with both the input and the correct output. Training a model fine-tunes parameters in each hidden state to produce the right final value. After a prediction, the error is calculated based on comparison with the known answer, and each layer’s parameters are adjusted. This adjustment is how the machine learns! The update in each layer depends on how much the previous layer had to be altered. Generally, adjustments lessen with each layer, propagating backwards from the end. Consequently, the first layers experience almost no adjustment and do not learn as much.
Although short-term memory loss is a shortcoming in some cases, it actually reflects nature in others. Electrons have a property called spin, which is a measure of internal angular momentum. The probability of an electron being in a certain position can be predicted from something called the wavefunction [4]. In Roth’s case, the input is the spin state of each unit cell, and the output is the wavefunction. If electrons only care about other nearby ones, then short-term memory loss is not a problem- the answer should depend less on distant electron input! Thus, the property of a RNN to value local input more than further input mimics the physics of the system. One thing to note, however, is that each output only considers previous input, effectively ignoring later input even if it is equally nearby. This amounts to favoring a direction, though electron repulsion should be spatially symmetric. To account for this asymmetry in the RNN architecture, one can take averages of the outputs to achieve an accurate result. The second analog between the systems appears in the RNN’s discrete input format, which is appropriate in crystals since their properties only apply for discrete spatial translations.
Calculating the wavefunction for a few unit cells can be qualitatively interesting, but approaching sizes of actual crystals used in experiments would provide more definitive answers about novel quantum behavior. Roth’s method not only works well for small systems, but the quality of the calculation improves as the size of the input increases. This suggests that the RNN is capable of learning the physics of the system, perhaps capturing how natural it is to model a system using algorithms with similar symmetries. Computational advances such as these are necessary if physicists are to understand some of the most interesting quantum phenomena of our day, such as superconductivity, effects of interacting magnetic and electric fields (Quantum Hall Effect), and entanglement.
References
[1] https://www.nature.com/articles/s41524-018-0085-8
[2] https://www.nature.com/articles/s41567-018-0048-5
[3] https://arxiv.org/abs/2003.06228
[4] R. M. Martin, Electronic Structure: Basic Theory and Practical Methods (Cambridge University Press, Cambridge, UK, 2004).
[5]https://towardsdatascience.com/illustrated-guide-to-recurrent-neural-networks-79e5eb8049c9







