Hands-on Tutorials
This project aims to build a Multi-label Classification model capable of detecting different classes of toxicity: ‘toxic’, ‘severe toxic’, ‘threat’, ‘obscene’, ‘insult’, and ‘identity hate’ for each comment. A comment could belong to more than one or none of the above categories. I have created an NLP data preprocessing pipeline using Regex (regular expressions), NLTK lib, Bag-of-Words and TF-IDF and then used supervised machine learning models such as Logistic Regression and Naive Bayes to classify comments.
Background
It has become evident that human behaviour is changing; our emotions are getting attached to the likes, comments and tags we receive on social media. We get both good and bad comments but seeing hateful words, slurs and harmful ideas on digital platforms on a daily basis make it look normal when it shouldn’t be. The impact of toxic comments is much more catastrophic than we think. It not only hurts one’s self-esteem or deters people from having meaningful discussions, but also provokes people to such sinister acts as recent capital riots at US Congress and attacks on farmers for protesting in India. Therefore, having a solid toxicity flagging system in place is important if we want to maintain a civilized environment on social media platforms to effectively facilitate conversations.
Dataset
The dataset used in this project is the Jigsaw/Conversation AI dataset provided for the Kaggle Toxic Comment Classification Challenge. It contains Wikipedia comments which have been labelled by human raters for six types of toxicity.
A snapshot of the dataset looks like this:

Exploratory Data Analysis
- Total comments: 159,571
- Decent comments (negative class): 143,346
- Not-decent comments (positive class): 16,225
These 16,225 not-decent comments are multi-labelled under six different types of toxic labels, which can be seen in figure 2.

Note that comments could have more than one label assigned to them, so figure 3 shows the count of comments and the number of labels associated with them.
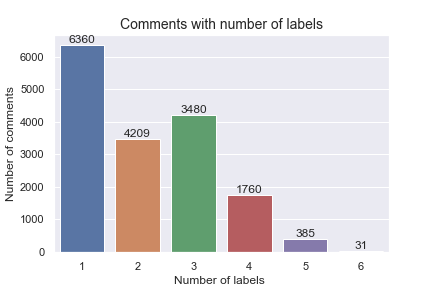
This dataset is highly imbalanced as the ratio of the negative class to the positive class is 89.8:10.2. With a dataset that is this skewed, the model will give a default accuracy of 90% in classifying a comment as a decent comment without learning anything. For the same reason, accuracy shouldn’t be a measure of model performance in this case. We need more descriptive performance metrics. Furthermore, multi-label classification problems must be assessed using different performance measures than single-label classification problems. Some examples of multi-label classification metrics are Precision at k, Average Precision at k, Jaccard Similarity Score, Hamming Loss, Sampled F1-score, etc. I have used Jaccard Similarity Score and also checked the F1-score and ROC score (AUC) to better evaluate and select a model.
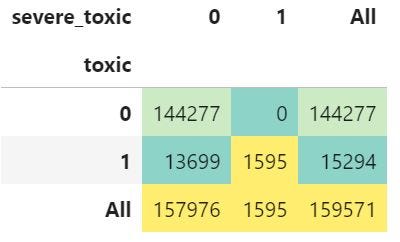
At this point of my exploration, I figured out the nature of the problem, statistics of the dataset and evaluation metrics to be used to assess the model. The question then arises – what are the correlations between these categories? I assumed that any comment that is "severe toxic", "obscene", "threat", "insult" or "identity hate" automatically falls under the "toxic" category. To verify this, I compared "toxic" category comments with the five other categories in pairs, figure 4 shows that all 1,595 severe toxic comments are also labelled as toxic comments, proving my assumption to be true.
But when comparing the "toxic" and "obscene" category in figure 5, it is interesting to notice that out of 8449 obscene comments 523 are not toxic. Upon investigating a few comments, I concluded that human raters labelled the comment as an obscene comment when the comment gives an in-general negative vibe but doesn’t contain vulgar words. However, I see comments which are labelled toxic and obscene as well. What is the explanation for that?

Next, figure 6 shows there are a total of 478 "threat" comments out of which 29 are not toxic. It makes sense if this comment "You will be blocked " is labelled as a "threat" but not "toxic". But the comment " That’s funny. You was personally offended? So the bad things writer new you, your name etc, right? And one get offended by a comment, or epithets on a website, then that same person must grow up spiritually for some more 5 centuries at least. And if one get more offended by the previous comment, then that same person must kill him/hersef. Take care!" is labelled as a "threat" but not "toxic" which doesn’t make much sense to me.

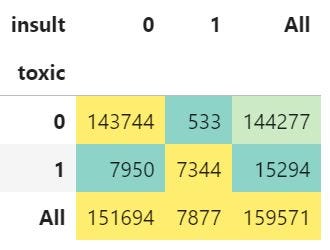
When I checked all 7,877 insult comments, I found 533 insult comments were not toxic (figure 7). On further investigation, I found that "insult" comments are not "toxic" if they don’t contain harsh or vulgar words.
Lastly, I checked the toxic and identity hate comment category (Figure 8), 103 identity-hate comments out of 1,405 were not toxic and the reason is these 103 comments didn’t contain foul or vulgar words but they did contain words that target ethnicity, colour, race, sexual orientation, religion-based hate etc.

Now, let’s have a look at the raw comment.
df.comment_text[0]
" ExplanationnWhy the edits made under my username Hardcore Metallica Fan were reverted? They weren’t vandalisms, just closure on some GAs after I voted at New York Dolls FAC. And please don’t remove the template from the talk page since I’m retired now.89.205.38.27 "
In this example, we see that the raw comment has some unnecessary information such as digits, punctuations and stopwords. These are not useful to the model in making predictions so we are removing them in data preprocessing.
Data Preprocessing
- Non-characters, unrequired spaces, digits are removed and all letters converted to lowercase with the help of the regex library.
These are the patterns I have noticed in the comments:
Let’s use these substitutions to write a function that cleans the text
- Lemmatisation, stemming, tokenization and removal of stopwords done using NLTK
With these two steps, we get clean comments. Now the raw comments look like this:
"explanation edits made username hardcore metallica fan reverted vandalism closure gas voted new york doll fac please remove template talk page since retired"
Better right!!!
Rule-Based Model
Before moving to Machine Learning models, I wanted to see if I could make predictions for all six categories in a comment by checking if the most frequently used words of the categories exist in the comment.
To do this, label-wise six datasets were created, then all the words from each dataset were stored in their respective dictionaries (vocabulary dictionary) with their respective occurrence counts in descending order. Finally, predictions were made by checking the presence of any of the top three words from the dictionary, in the comment.
Baseline model accuracies for predicting toxic, severe_toxic, obscene, threat, insult, and identity_hate classes are:
- toxic: 89.4%
- severe_toxic: 88.2%
- obscene: 96.3%
- threat: 87.8%
- insult: 95.8%
- identity_hate: 98.3%
Based on the rules implemented here, the baseline classifier is classifying decent and not-decent comments with an accuracy of 76.6%. Now we have to see if AI-based models give better performance than this.
Convert Comments into Vectors using Bag-of-Words or TF-IDF
Machine learning models don’t accept input in the text format so we need to convert the text data into vector form. This process is called Word Embeddings. Word Embeddings can be broadly classified as:
- Frequency-based – Most popular techniques are Bag-of-Words, TF-IDF
- Prediction-based – Most popular techniques are Word2vec and Glove
Here I will be using Frequency-based word embeddings.
The resultant embeddings are in NumPy array format, and if we observe the embeddings we will see high dimensional sparse data.
Machine Learning Models
To tackle the multi-label classification problem OneVsRestClassifier is used with estimators such as Logistic Regression and Naive Bayes.
Logistic Regression was the first choice to try because it works well with high dimensional sparse data. The second choice was Multinomial Naive Bayes because it assumes count data, which means each feature represents an integer count of something. In our problem, the integer count represents how often a word appears in a sentence.
Code used for training OneVsRestClassifier:
In the trainmodel function, I have used j_score and print_score_ these are defined as:
Training Result of the Different Models
Performance summary of all the models trained on different sets of parameters:

It’s clear from training results that Logistic Regression performs well with continuous data (when features were computed with "TF-IDF") and Naive Bayes does well when data is in discrete form (when features were computed with "Bag-of-Words"). I noted Naive Bayes performs well by comparing the Jaccard score, F1-score, and _ROCAUC score of these two models. I am sure with the further fine-tuning of the hyperparameters on Logistic Regression, we could get a good model but it is quite expensive in terms of computations and training time to get the comparable outcome to Naive Bayes. So, I choose to go with Naive Bayes using the "Bag-of-Words" embedding technique with _maxfeatures count as 2000.
Another thing to be noted here is that the model learns to associate frequently used words within the respective category with the respective toxic classes. For example, the model will predict this comment "I am a beautiful black gay woman" as a "toxic" and "identity hate" because the words "Black" and "Gay" are heavily used within "toxic" and "identity hate" categories in the dataset. To avoid such unintended biases Jigsaw/Conversational AI came up with another dataset where they have labelled a subset of non-toxic comments with identity attributes.
Conclusion
We saw the machine learning models beat the rule-based baseline. In the future, I would like to try advanced models like LSTM, BERT but here I have a question for you readers…
Should I be worried about my model performance and try advanced models like LSTM or BERT when I have discovered the dataset is weakly labelled or I should try a new dataset and see if my current model could perform better?
To try this application click here. I look forward to hearing your thoughts or comments.







