Machine Learning | Accelerated Computation | Artificial Intelligence

This article discusses Groq, a new approach to computer hardware that’s revolutionizing the way AI is applied to real world problems.
Before we talk about Groq, we’ll break down what AI fundamentally is, and explore some of the key components of computer hardware used to run AI models. Namely; CPUs, GPUs, and TPUs. We’ll explore these critical pieces of hardware by starting in 1975 with the Z80 CPU, then we’ll build up our understanding to modern systems by exploring some of the critical evolutions in computer hardware.
Armed with an understanding of some of the fundamental concepts and tradeoffs in computer hardware, we’ll use that understanding to explore what Groq is, how it’s revolutionizing the way AI computation is done, and why that matters.
Naturally there’s a lot to cover between early CPUs and a cutting edge billion dollar AI startup. Thus, this is a pretty long article. Buckle up, it’ll be worth it.

Who is this useful for? Anyone interested in Artificial Intelligence, and the realities of what it takes to run AI models.
How advanced is this post? This post contains cutting edge ideas from a cutting edge AI startup, and explains them assuming no prior knowledge. It’s relevant to readers of all levels.
Pre-requisites: None, but there is a curated list of resources at the end of the article for related reading.
Disclaimer 1: this article isn’t about Elon Musk’s chat model "Grok". Groq and Grok are completely unrelated, besides the fact that their names are based on the same book.
Disclaimer 2: During the time of writing I am not affiliated with Groq in any way. All opinions are my own and are unsponsored. Also, thank you to the Groq team for clarifying technical details and pointing me in the right direction. Specifically, thanks to Andrew Ling, VP of software engineering at Groq. I requested a few meetings with Andrew, and he was gracious enough to help me untangle some of the more subtle nuances of Groq’s hardware. Without those conversations this article wouldn’t have been possible.
Defining AI
Many people think of AI as a black box. You put stuff in, the AI does some obscure math, and you get stuff out.

This intuition is popular because it’s sometimes difficult for a human to understand a model’s thought process.
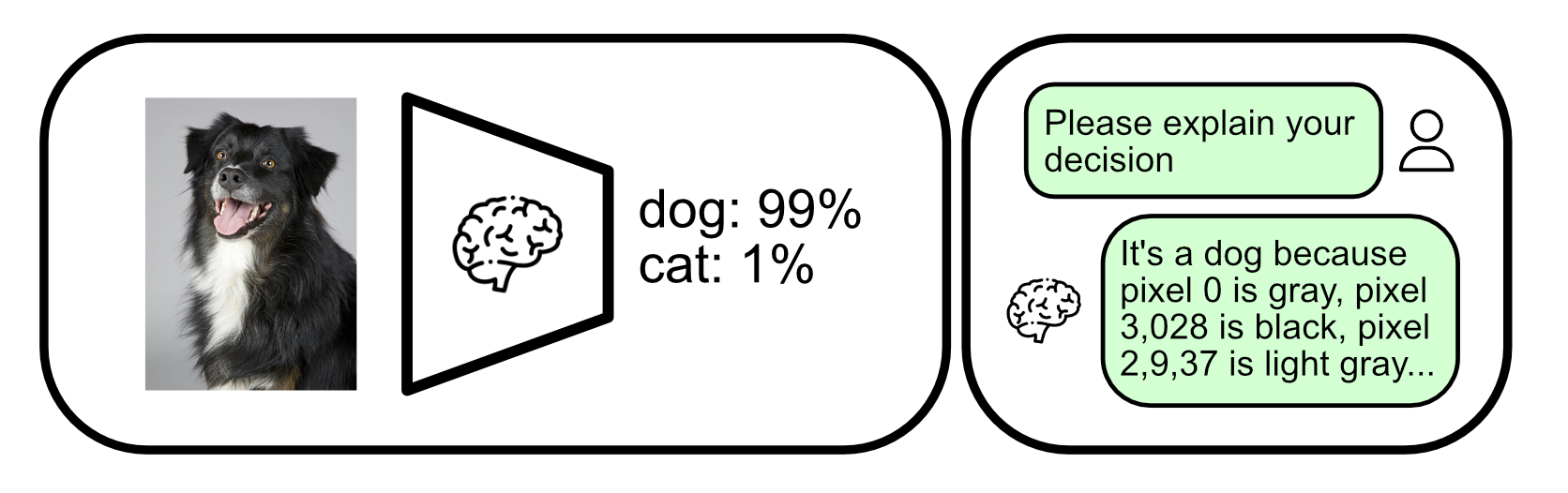
Even though it can be difficult to understand the rationale behind a models decision as a whole, under the hood AI models employ very simple mathematical operations to come to their conclusions.
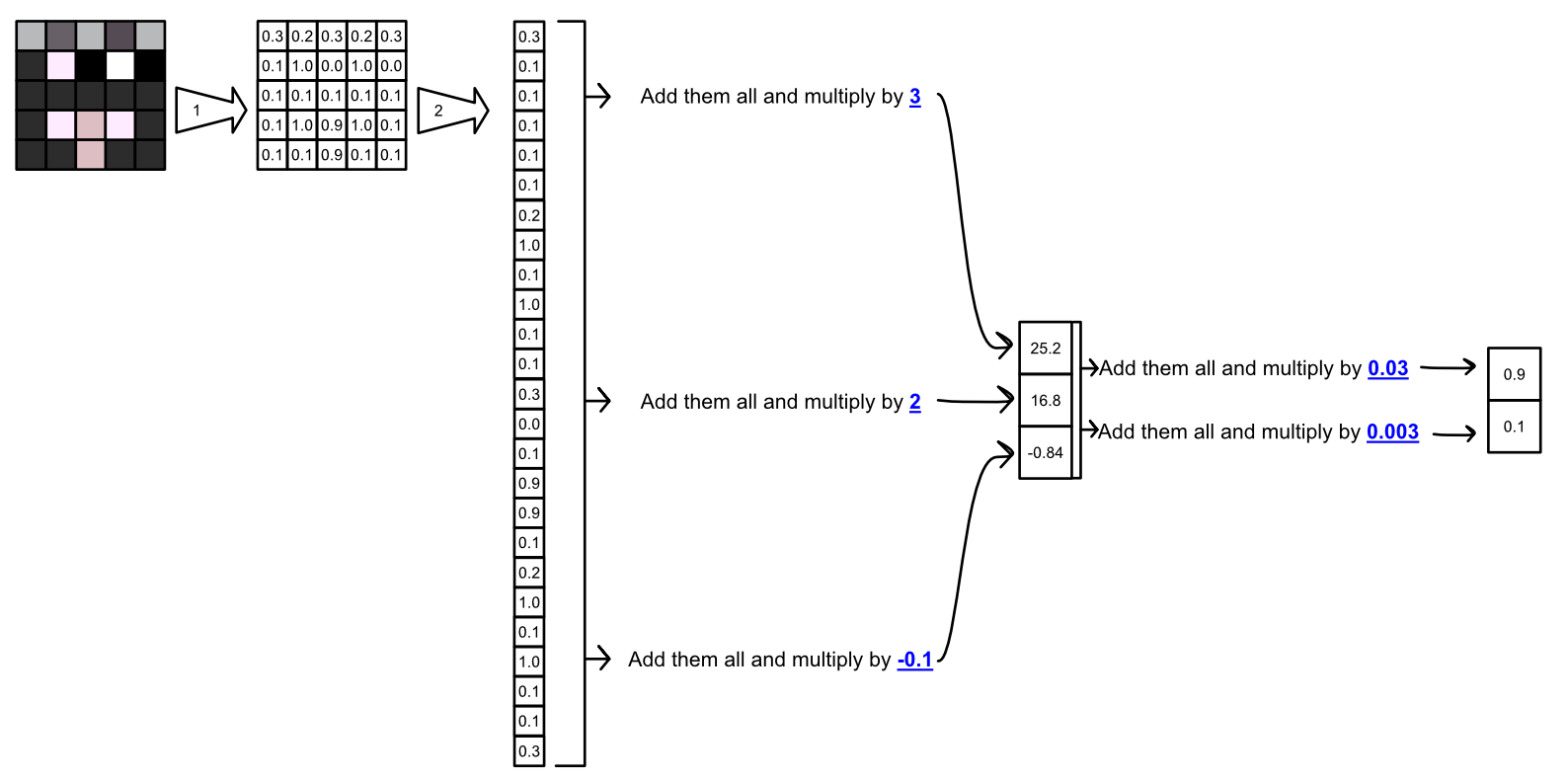
In other words, the reason AI models are complicated isn’t because they do complicated things, its because they do a ton of simple things, all at once.
There are a lot of hardware options that can be used to run AI. Let’s start by describing the most fundamental one.
The CPU
The main component of most modern computers is the CPU, or "Central Processing Unit". CPUs are the beating heart of virtually every modern computer.

At its most fundamental, the CPU is based on the "Von Neumann architecture".
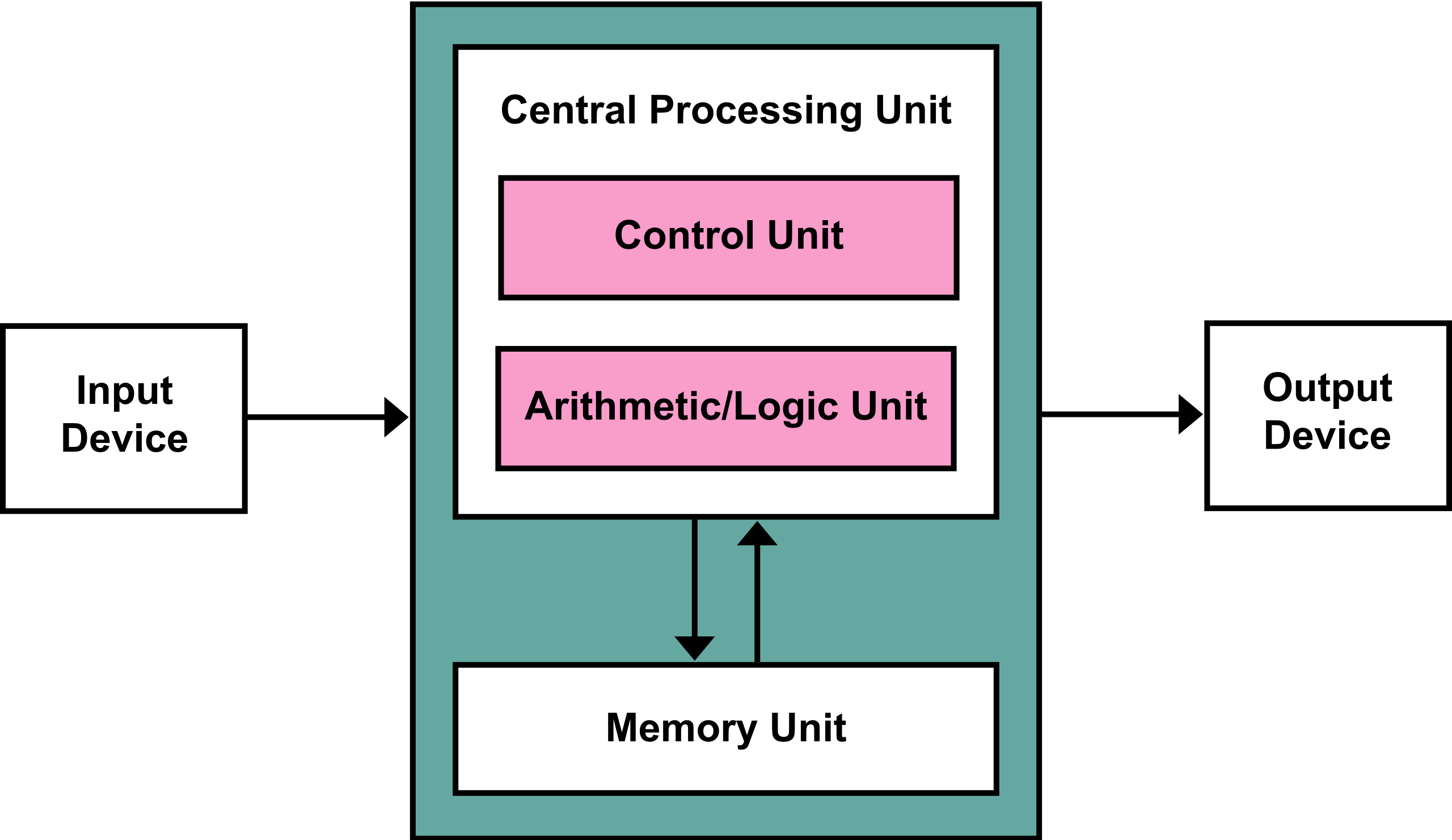
The Von Neumann architecture is pretty abstract; there’s a lot of leeway in terms of putting it into practice. Pretty much all the hardware we’ll be discussing in this article can be thought of as particular flavors of a Von Neumann device, including the CPU.
A popular early computer, the ZX Spectrum, employed the Z80 CPU to get stuff done. Conceptually, modern CPUs aren’t very different than the Z80, so we can use the Z80 as a simplified example to begin understanding how CPUs work.

Even the diagram for this humble CPU is fairly complex, but we can pick it apart to get an idea of some of the core components, which largely persist into modern CPUs.
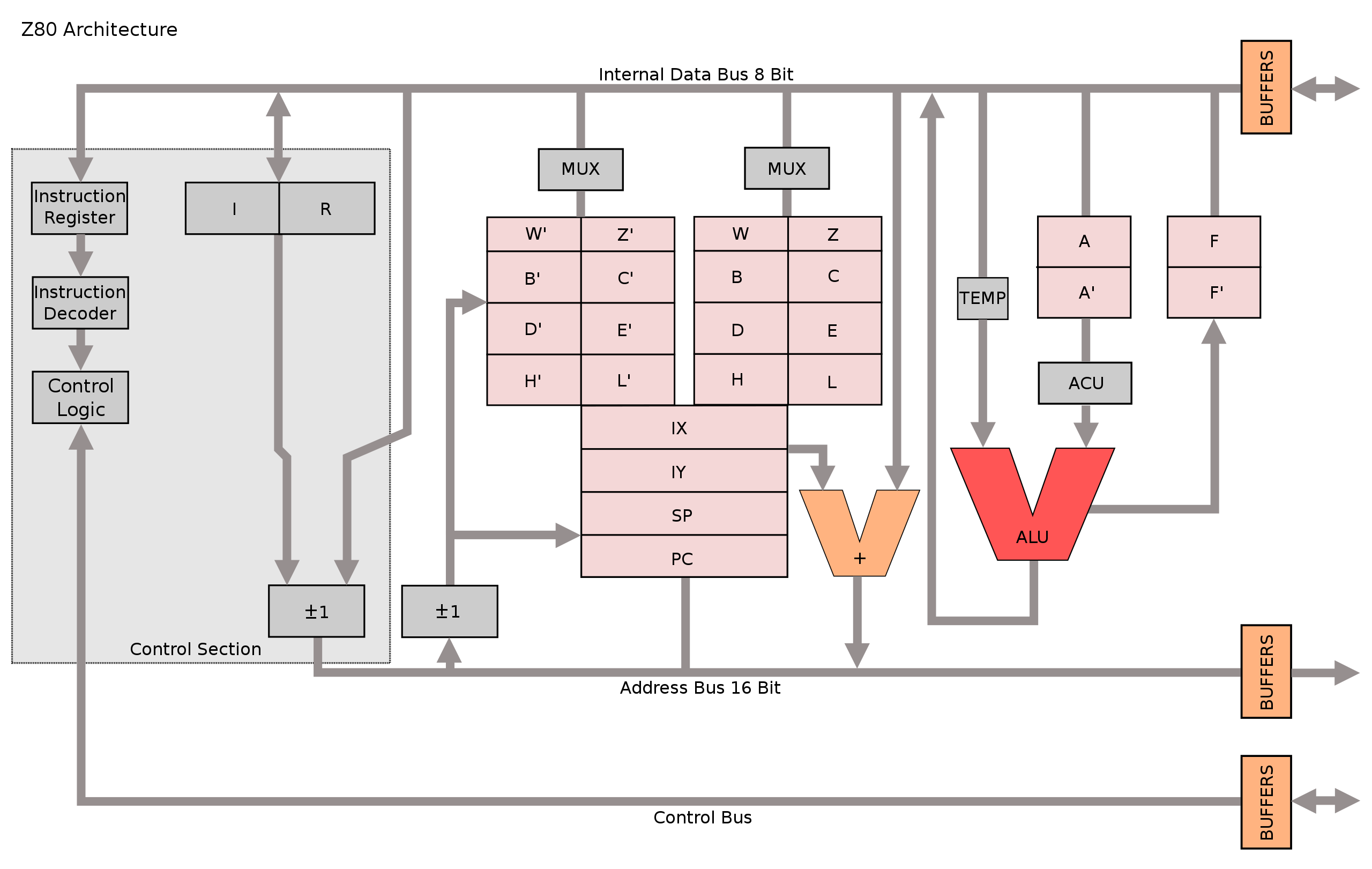
The Z80 featured a control circuit, which converted low level instructions into actual actions within the chip, as well as kept track of book keeping things, like what commands the CPU was supposed to do.
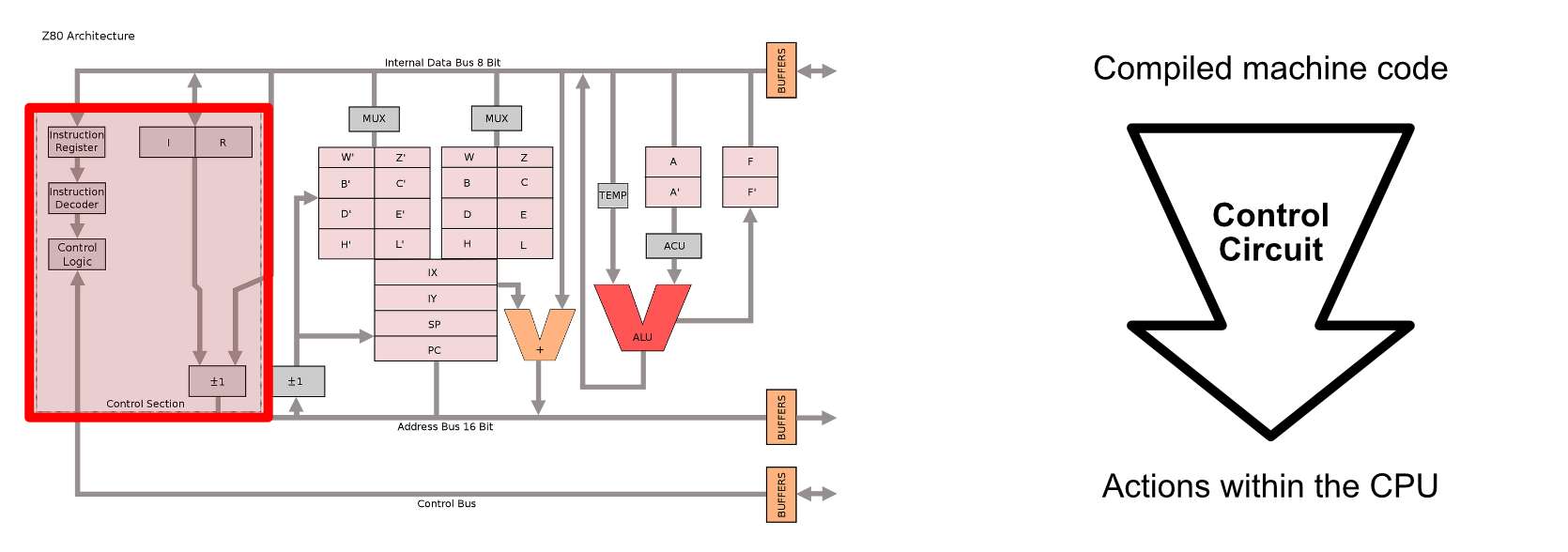
The Z80 featured an "arithmetic logic unit" (or ALU for short) which was capable of doing a variety of basic arithmetic operations. This is the thing that really did a lot of the actual computing within the Z80 CPU. The Z80 would get a few pieces of data into the input of the ALU, then the ALU would add them, multiply them, divide them, or do some other operation based on the current instruction being run by the CPU.
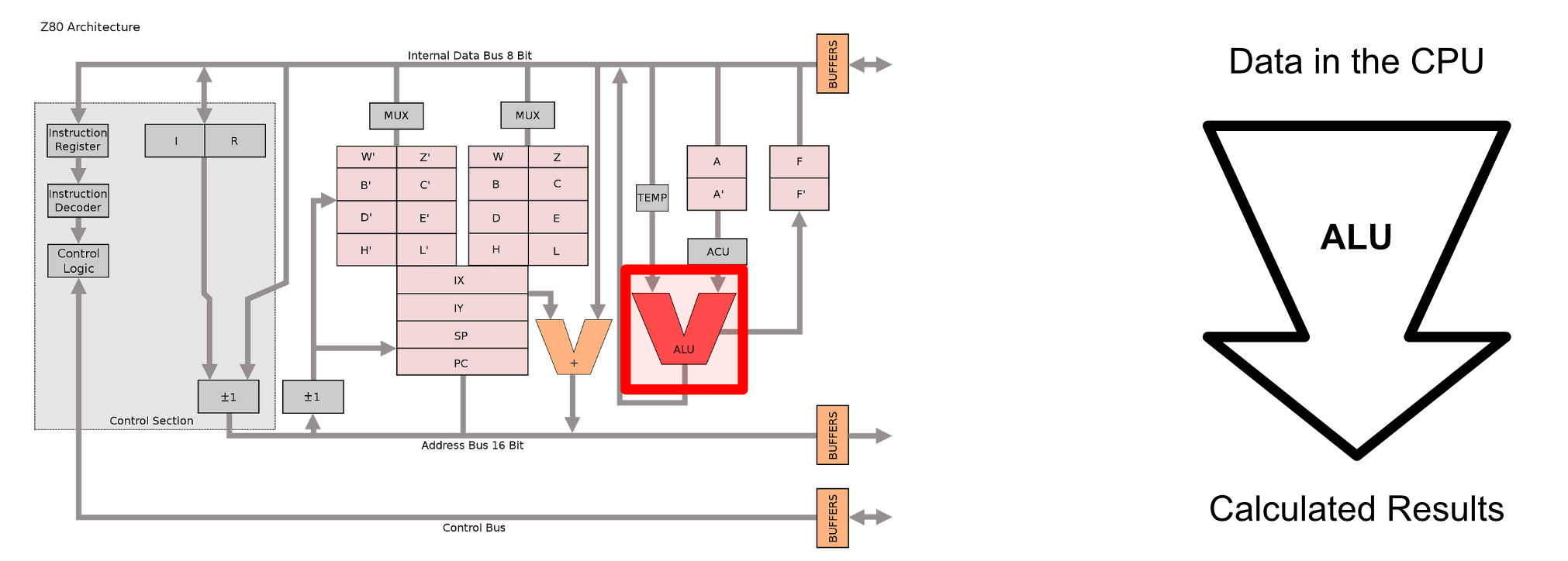
Virtually any complex mathematical function can be divided into simple steps. The ALU is designed to be able to do the most fundamental basic math, meaning a CPU is capable of very complex math by using the ALU to do many simple operations.
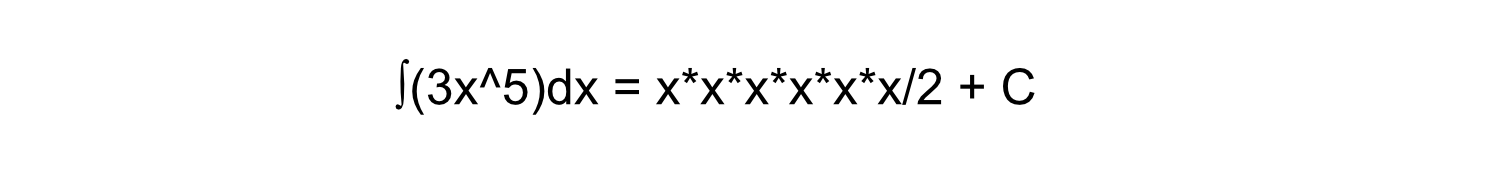
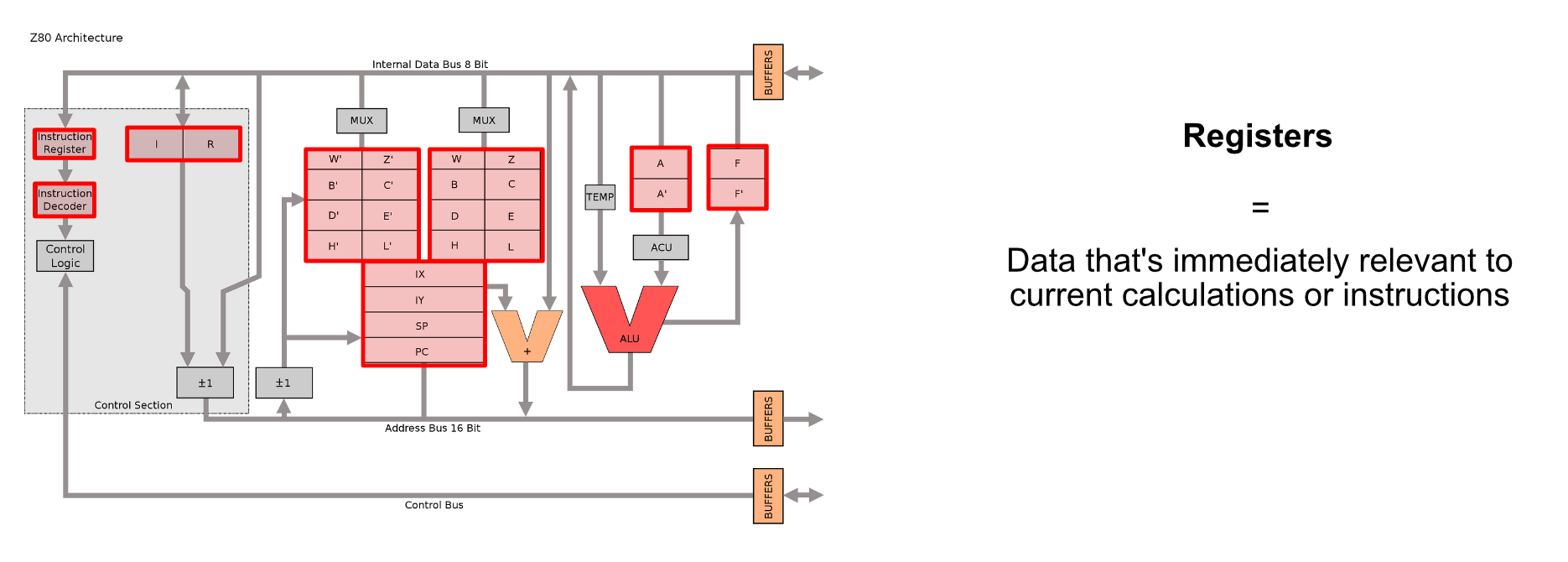
The Z80 also contained a bunch of registers. Registers are tiny, super fast pieces of memory that exist within the CPU to store certain key pieces of information like which instruction the CPU is currently running, numerical data, addresses to data outside the CPU, etc.
When one thinks of a computer it’s easy to focus on circuits doing math, but in reality a lot of design work needs to go into where data gets stored. The question of how data gets stored and moved around is a central topic in this article, and plays a big part as to why modern computing relies on so many different specialized hardware components.
The CPU needs to talk with other components in the computer, which is the job of the busses. The Z80 CPU had three busses:
- The Address Bus communicated data locations the Z80 was interested in
- The Control Bus communicated what the CPU wanted to do
- The Data Bus communicated actual data coming to and from the CPU
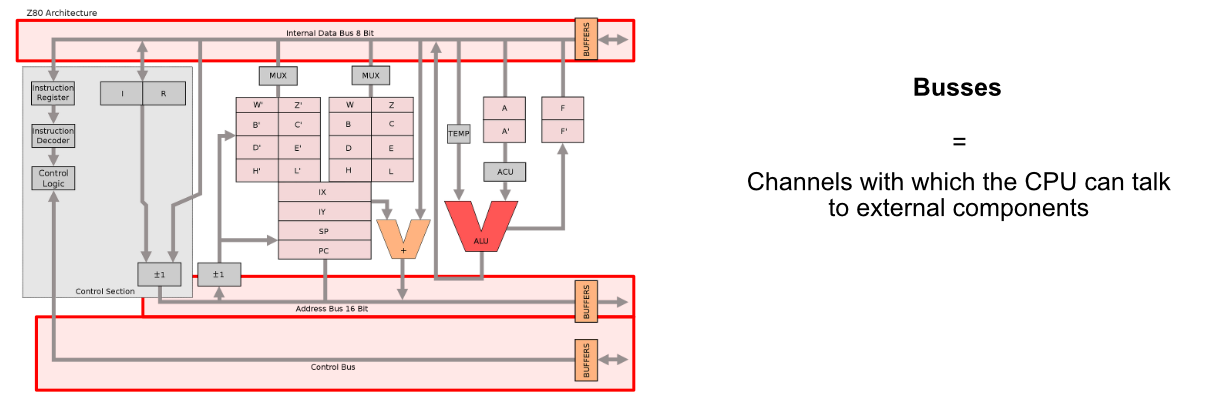
So, for instance, if the Z80 wanted to read some data from RAM and put that information onto a local register for calculation, it would use the address bus to communicate what data it was interested in, then it would use the control bus to communicate that it wanted to read data, then it would receive that data over the data bus.
The whole point of this whole song and dance is to allow the CPU to perform the "Fetch, Decode, Execute" cycle. The CPU "fetches" some instruction, then it "decodes" that instruction into actual actions for specific components in the CPU to undertake, then the CPU "executes" those actions. The CPU then fetches a new instruction, restarting the cycle.
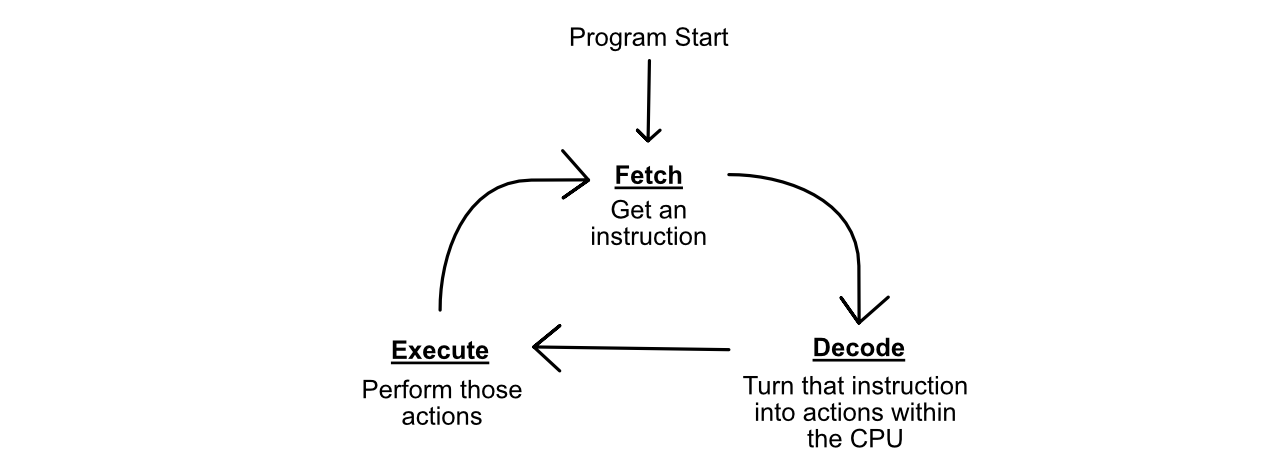
This cycle works in consort with a program. Humans often think of programs as written in a programming language like Java or Python, but after the text of a program is interpreted by a compiler into machine code, and that machine code is transmitted to the CPU, a program ends up looking very different. Essentially, the compiler turns the program written by a human into a list of instructions which the CPU can perform based on it’s predefined control logic.
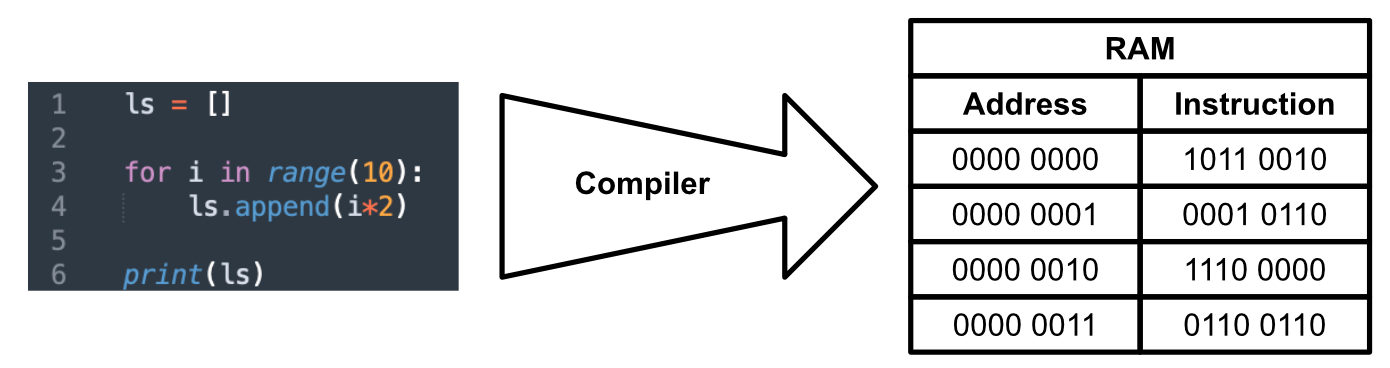
Once the code has been compiled, the CPU simply fetches an instruction, decodes it into actions within the CPU, then executes those actions. The CPU keeps track of where it is with a program counter, which usually increments each time an instruction is called, but it might also jump around the program based on some logic, like an if statement.
And that’s basically it. It turns out, even a simple CPU is capable of doing pretty much any calculation imaginable just by following a series of simple instructions. The trick, really, is getting the CPU to do those instructions quickly.
Design Constraints of the CPU
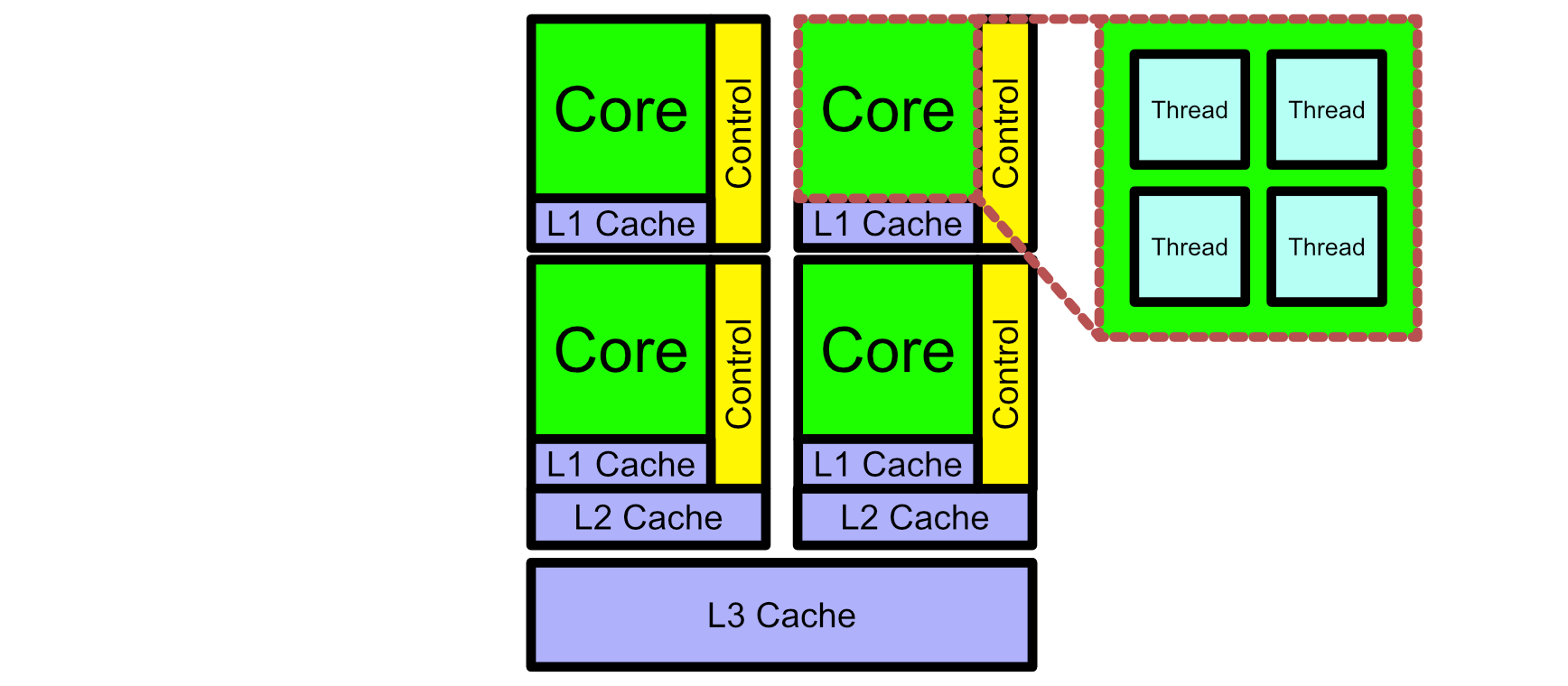
The Z80 was a fairly simplistic CPU. For one thing, it was a single "core". The actual specifics of a core can get a little complicated, but a core is essentially a thing that does work on a CPU. Imagine instead of one Z80, we had a few Z80s packed together on a single chip, all doing their own thing. That’s essentially what a modern multi core CPU is.
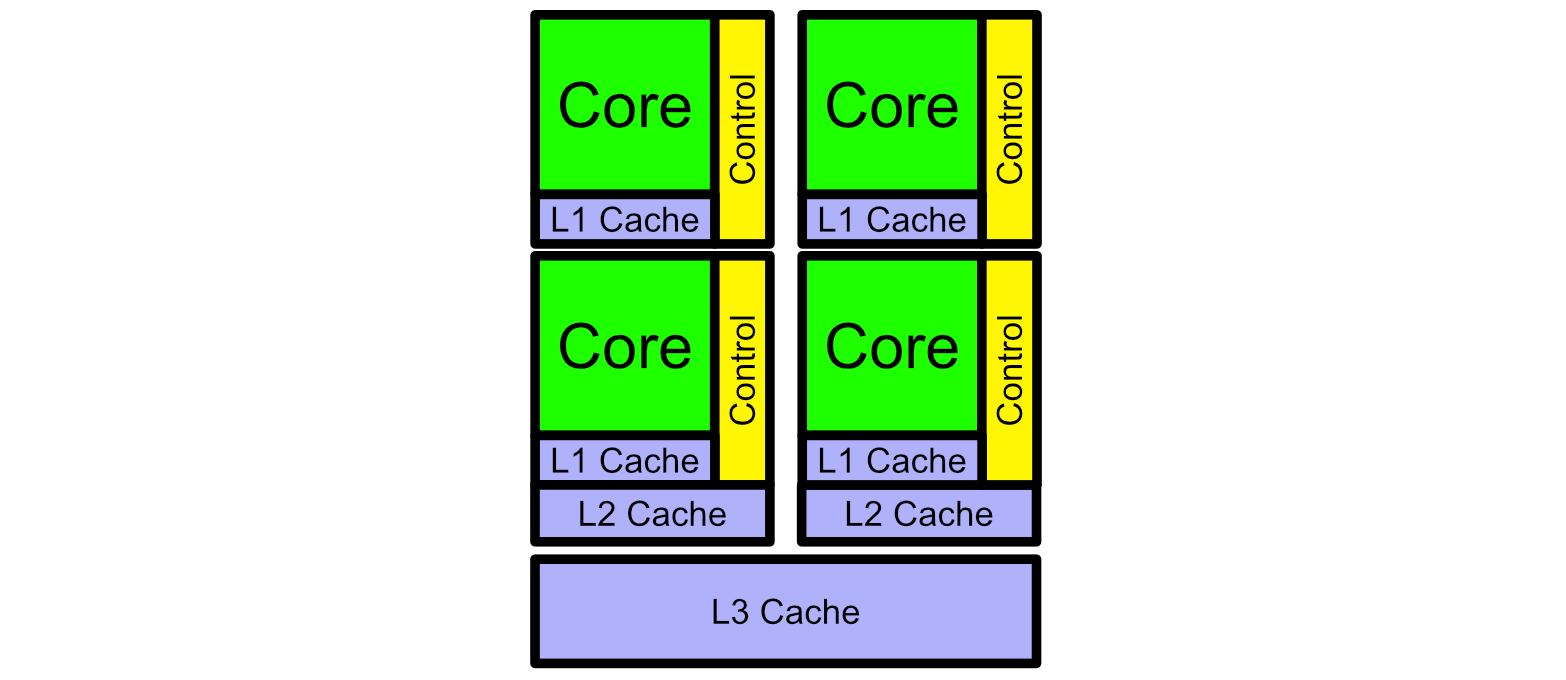
It is possible for the cores in a CPU to talk with each other, but to a large extent they usually are responsible for different things. These "different things" are called a "process". A process, in formal computer speech, is a program and memory which exists atomically. You can have multiple processes on different Cores, and they generally won’t talk to one another.
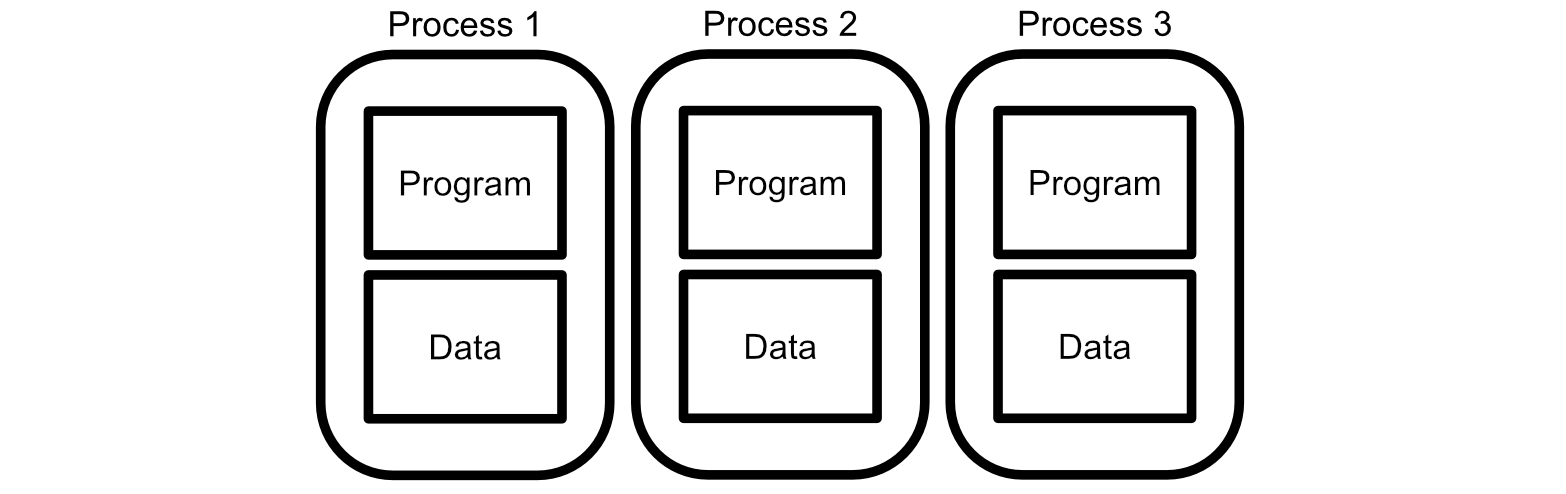
Chrome actually uses a separate process for each tab. That’s why, when one tab crashes, other tabs are not affected. Each of the tabs is a completely separate process. That’s also, to a large extent, why chrome consumes so much memory on a computer; all of these tabs are operating in near isolation from one another, which means they each need to keep track of a bunch of information.

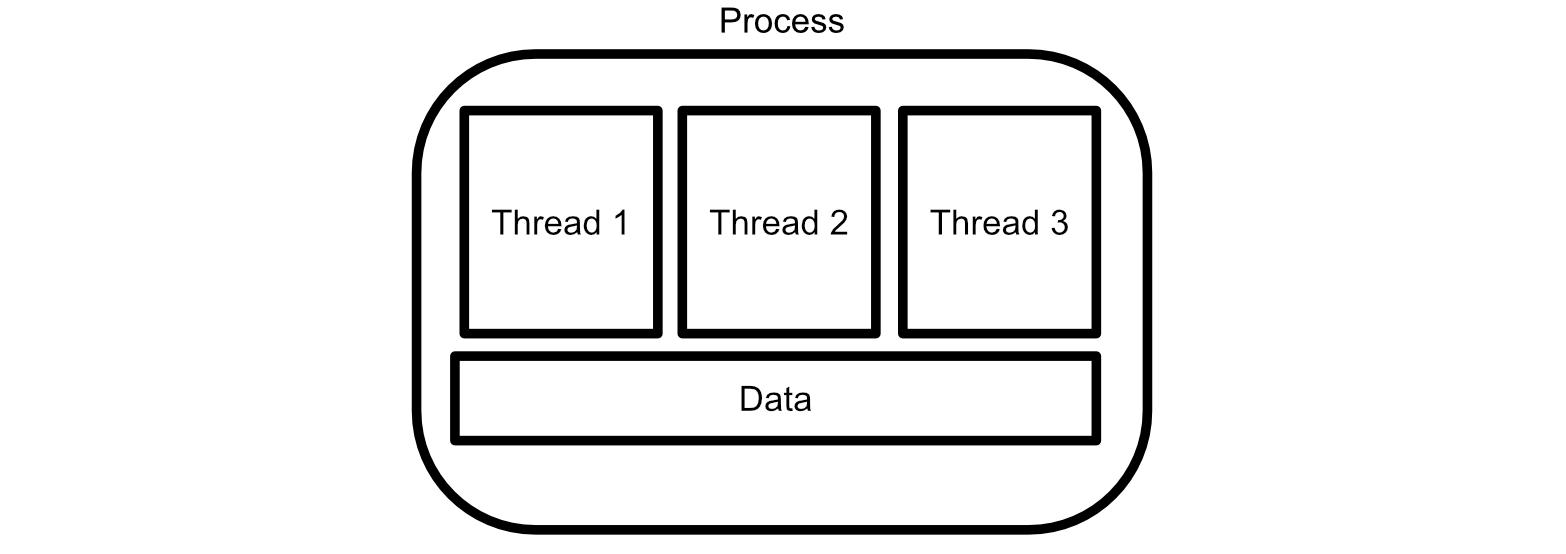
Sometimes it’s useful for a computer to be able to break up multiple calculations within a single program and run them in parallel. That’s why there are usually multiple "threads" within each core of a CPU. Threads can share (and cooperatively work together) on the same address space in memory.
Threads are useful if you have a bunch of calculations which don’t depend on one another within a program. Instead of doing things back to back, you can do calculations in parallel across multiple threads.
So, a CPU can have multiple cores to run separate processes, and each of those cores have threads to allow for some level of parallel execution. Also CPUs contain computational units (ALUs) that can do pretty much any calculation imaginable. So.. We’re done right? We just need to make bigger and more powerful CPUs and we can do anything.
Not quite.
As I previously mentioned, CPUs are the beating heart of a computer. A CPU has to be able to do any of the arbitrary calculations necessary to run any program, and it has to be able to do those calculations quickly to keep your computer’s response time near instantaneous.
To synchronize the rapid executions in a CPU, your computer has a quartz clock. A quartz clock ticks at steady intervals, allowing your computer to keep operations in an orderly lock step.
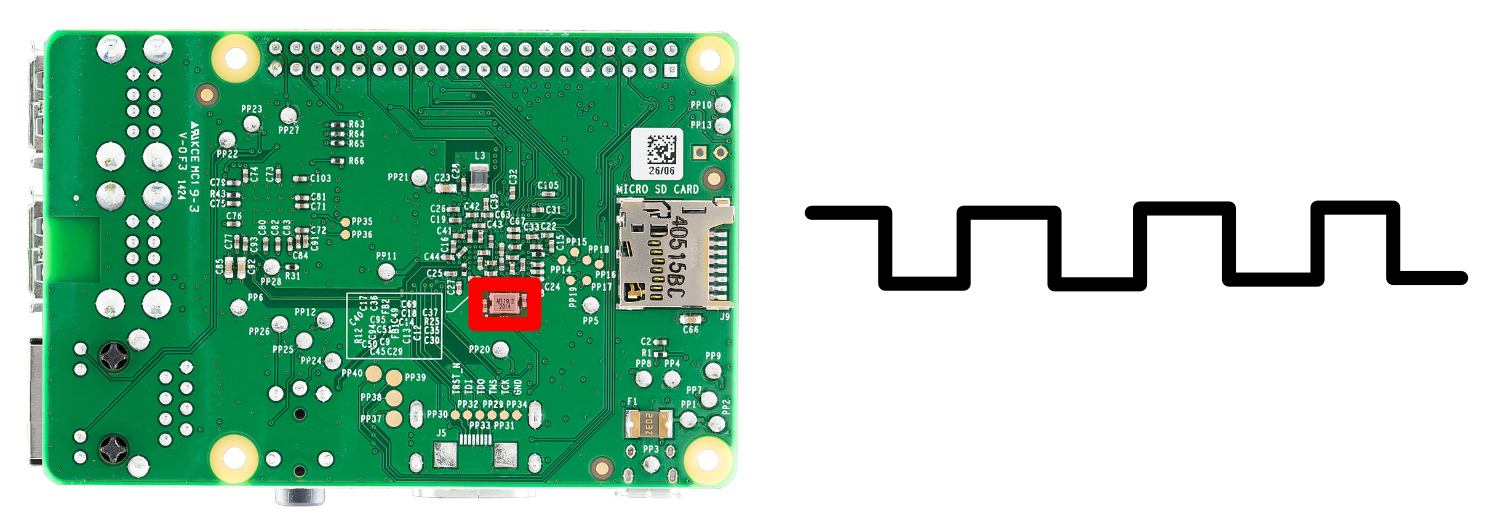
These clocks are crazy fast. On the raspberry pi pictured above the clock oscillates at 19.2MHz, but modern CPUs can reach into the Gigahertz range. For those not familiar with these units, 1 Gigahertz is one billion oscillations per second, and with each of those oscillations the CPU is expected to fetch and execute an instruction for every core. Here’s a picture of a billion things, for reference:

So, CPUs do things fast. They run based on a clock that’s oscillating billions of times per second. In fact, that’s so fast that the speed of light (the speed limit of the universe) starts coming into play.
The speed of electricity through silicone is around 60 million meters per second. a Typical CPU clock might oscillate 3 billion times per second. That would mean that electricity can only travel 20mm (less than an inch) within a CPU for every clock tick.
If CPUs get much bigger than they currently are then designers will run into serious challenges in terms of keeping operations across the chip synchronized. Imagine one part of a CPU trying to do addition, but one of the values didn’t fully arrive yet because the source of that information is over an inch away. This issue is certainly solvable… With more components, which take up space within the CPU, further exasperating the issue.
There’s other issues that I won’t go into; the cost of manufacturing square chips on round silicone wafers, intricacies in terms of cooling, etc. Basically, "just making CPUs bigger" has a lot of serious issues.
Another serious design consideration arises when we consider what CPUs are chiefly responsible for.
I mentioned CPUs have to be fast. More specifically, they need to have incredibly low latency. latency, generally, is the amount of time something takes from starting to ending. When you’re running a program sequentially the amount of latency in running each execution has a big impact on performance.

So, the CPU attempts to minimize latency as much as possible. The cores in a CPU need to be blazingly fast, the data needs to be right there, ready to go. There’s not a lot of wiggle room.

CPUs optimize for latency in a lot of ways. They have a special type of memory called Cache, which is designed to store important data close to the CPU so that it can be retrieved quickly.
CPUs employ a lot of other fancy technologies that, frankly, I don’t fully understand. Intel spends approximately $16 Billion annually on research and development. A decent chunk of that goes into squeezing as much performance out of this rock as possible. For CPUs, that means more Cores, more threads, and lower latency.
Focusing on faster and faster CPUs was the focal point of computation until the 90s. Then, suddenly, a new type of consumer emerged with a new type of performance requirement.
Enter Gamers
With video games, CPUs don’t stand a chance.
CPUs are great for running sequential programs, and even have some ability to parallelize computation, but to render video on a screen one needs to render millions of pixels multiple times a second.
On top of that, the values of pixels are based on 3D models, each of which might be made of thousands of polygons. A lot of independent calculations need to be done to turn video games into actual video, a very different use case than the rapid and sequential tasks the CPU was designed to handel.

There were a variety of chips designed to help the CPU in handling this new load. The most famous was the GPU.
The Origins of the GPU
The first mainstream GPU was created by Nvidia – The GeForce 256.

The idea behind this particular device was to offload expensive graphical processing onto purpose built hardware. The GeForce 256 was a very rigid and specific machine, designed to handle the "graphics pipeline". The CPU would give the 256 a bunch of information about 3D models, materials, etc. and the GPU would do all the processing necessary to generate an image onto the screen.

The 256 did this with specialized chips designed to do very specific operations; hardware for moving models in 3D space, calculating information about lighting, calculating if this was on top of that, etc. We don’t need to get too into the weeds of computer graphics, and can cut straight to the punchline: this specialized hardware improved the framerate of some games by up to 50%, which is a pretty monumental performance increase.
Naturally the first ever GPU wasn’t perfect. In being so rigidly designed it didn’t have a lot of flexibility to meet different needs for different applications. Nine years after the GeForce 256, Nvidia released the first modern GPU, which improved on the original GPU in many ways.
Modern GPUs
The Nvidia GeForce 8 was the first modern GPU, and really set the stage for what GPUs are today.

Instead of employing components designed to do specific graphical operations, the GeForce 8 series was a lot more like a CPU. It had general purpose cores which could do arbitrary calculations.
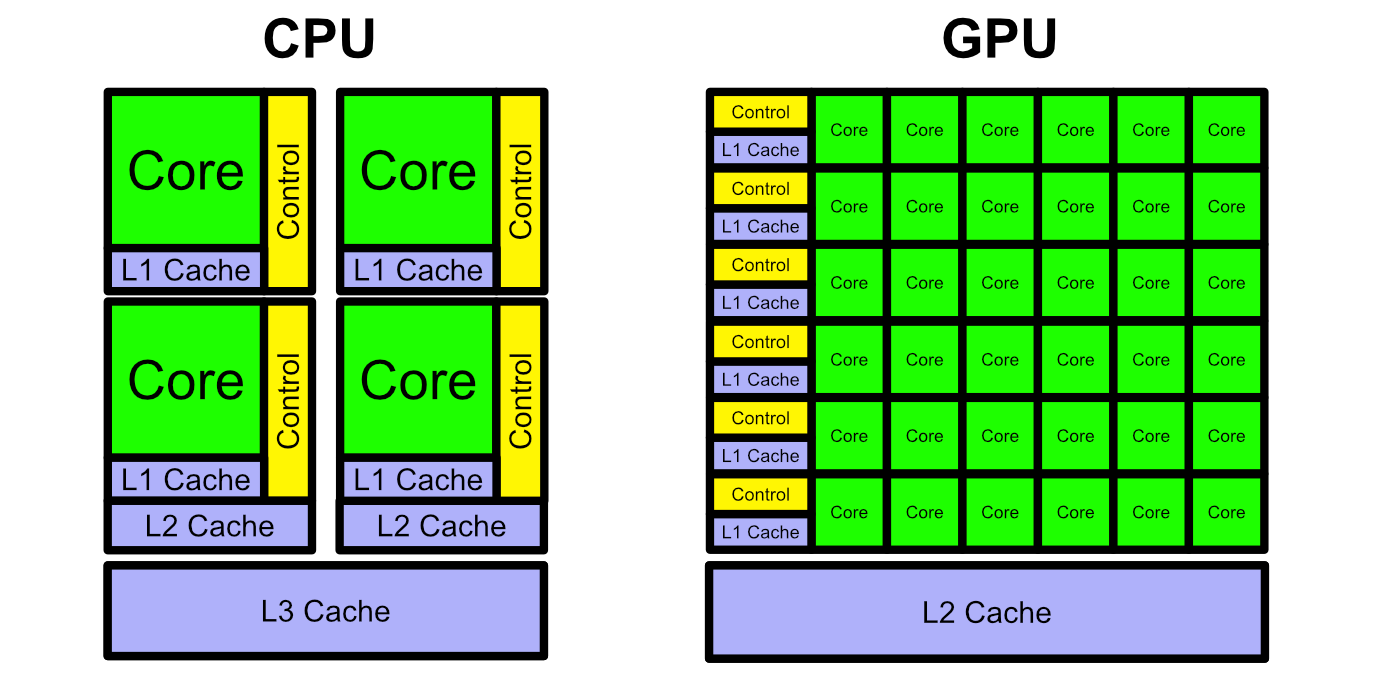
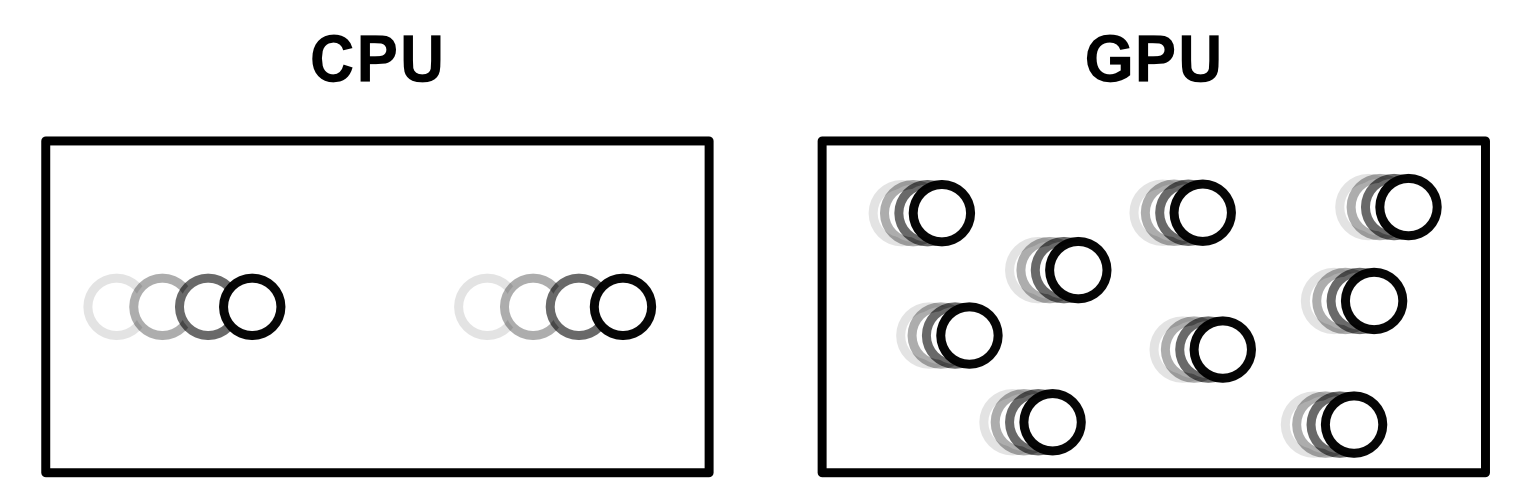
However, instead of focusing on low latency calculations for sequential programs, the GeForce 8 focused on a high throughput for parallel computation. In other words, CPUs do things back to back really quickly. GPUs are designed to do things a bit more slowly, but in parallel. This is a distinction between the CPU and the GPU which persists to this day.
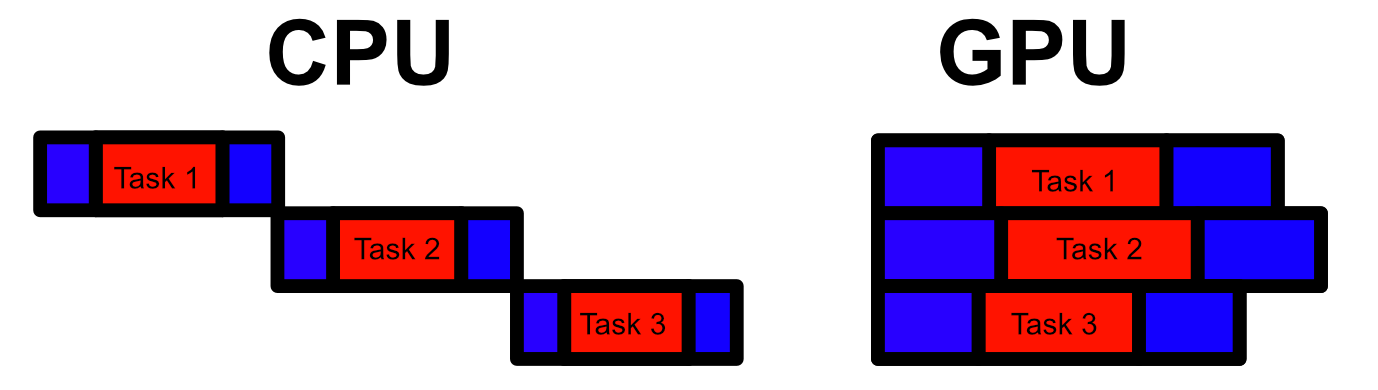
The GPU achieved parallel computation by employing the "Single Instruction, Multiple Data" (SIMD) approach to computation, allowing multiple cores to be controlled simultaneously. Also, by not caring too much about the latency of a particular calculation, the GPU can get away with a bit more setup time, allowing for the overhead to set up numerous computations. This makes a GPU really bad for running a sequential program, but very good for doing numerous calculations in parallel (like those needed to render graphics). Also, because the GPU was designed to do specific calculations for graphics (instead of anything under the sun like a CPU), the GPU can get away with smaller cores and less complex control logic. The end result is a lot of cores designed to do as many parallel calculations as possible.
To give you an idea of how different the capabilities are, the Intel Xeon 8280 CPU has 896 available threads across all its cores. The Nvidia A100 GPU has 221,184 threads available across all its cores. Thats 245x the number of threads to do parallel computation, all made possible because GPUs don’t care (as much as CPUs) about latency.
GPUs and AI
As you might be able to imagine, graphics aren’t the only thing that can benefit from parallel computation. As GPUs took off, so did their use cases. Quickly GPUs became a fundamental building block in a variety of disciplines, including AI.
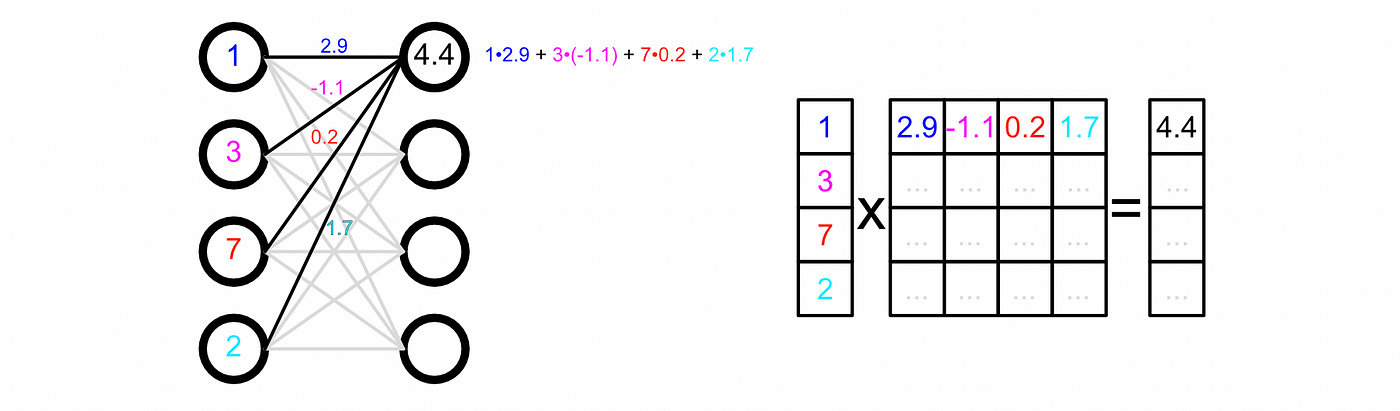
Back in the beginning of the article I provided a simplified demonstration of AI.
Running this simple AI model with a CPU might look something like this:
- Add up all the values in the first vector. That would be 24 calculations.
- Multiply the result by 3, 2, and -0.1. That would be three more calculations.
- Add those results together, two more calculations.
- Multiply that result by 0.03 and 0.003, two more calculations.
that’s 31 sequential calculations. Instead, you could parallelize it.
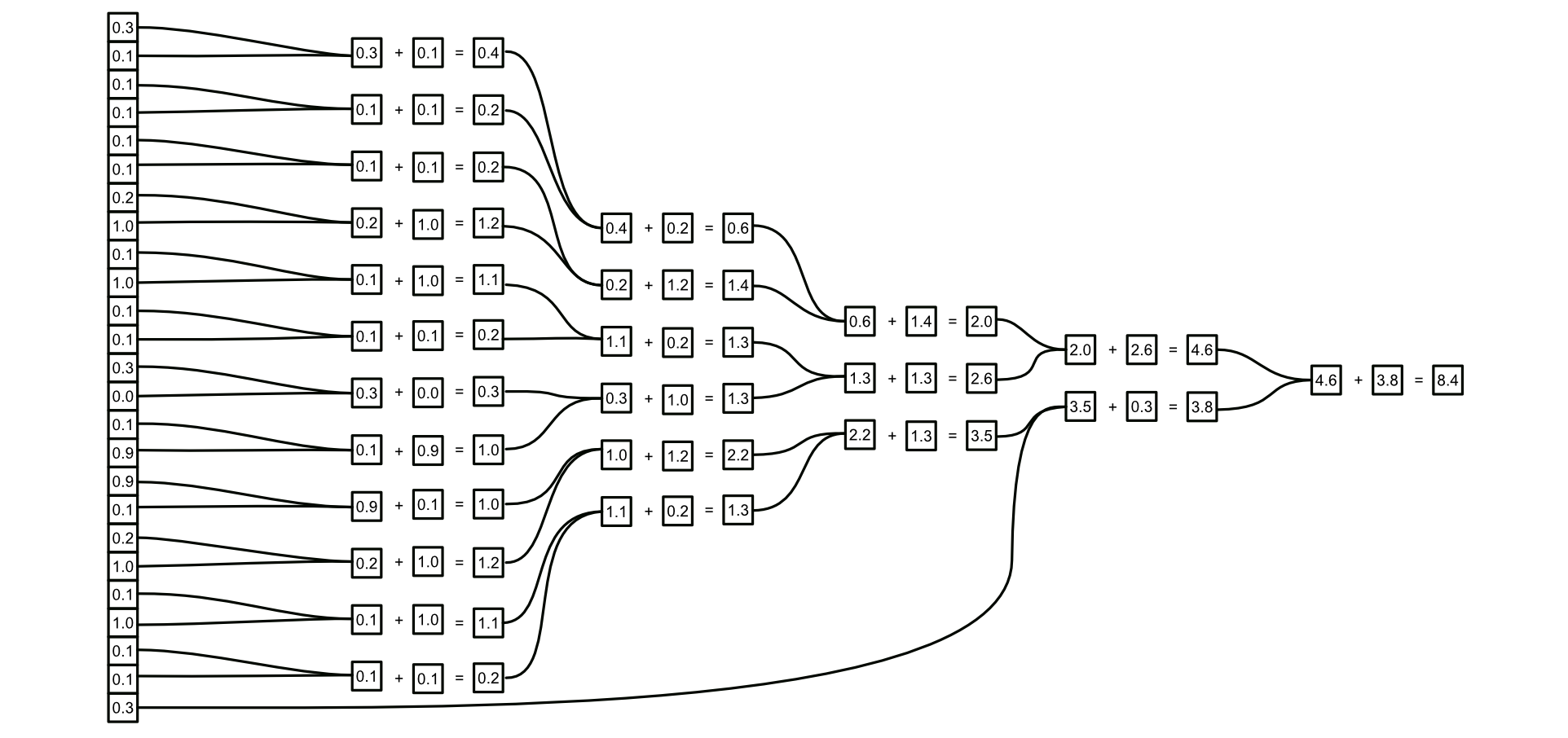
If you parallelized the addition in this particular example, and parallelized multiplication, you would end up shrinking the 31 sequential operations into 9 parallelized steps. Assuming all else is equal, running this model in a parallelized fashion would be 2.4 times faster.
This example get’s the point across, but it’s actually less dramatic than real world examples. Actual modern AI models often use matrix multiplication under the hood. In matrix multiplication, every row gets multiplied by every column and the results are added together to construct a resultant matrix.
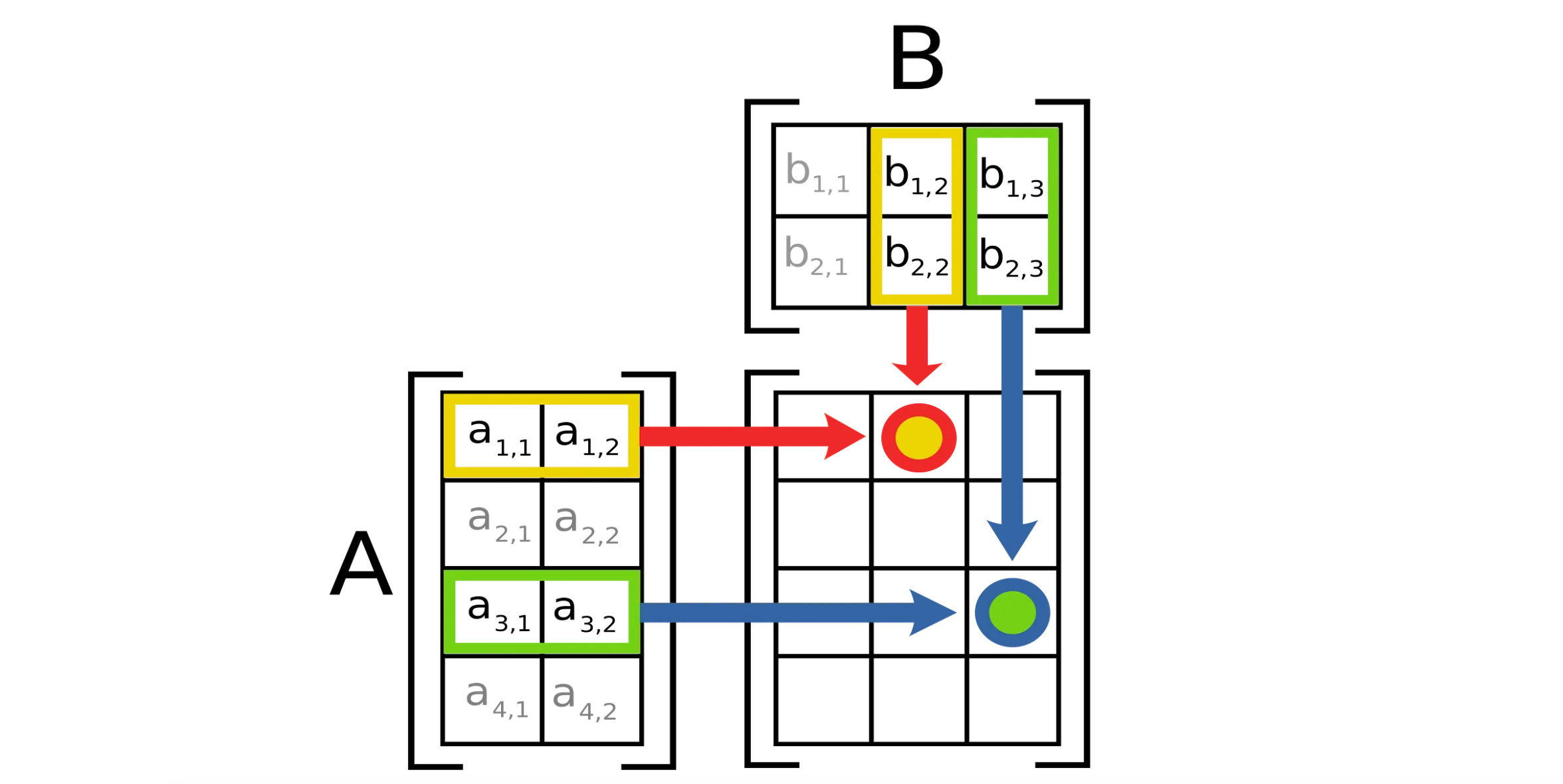
Modern Machine Learning models are big, which means the matrices within them are also big. The number of calculations required to do matrix multiplication for an M x N and a N x P matrix would be M * N * P . So, if you had a two square matrices of shape 256 x 256 , you would have to do over 16 billion operations to compute the matrix multiplication between them. Imagine this, over and over again, throughout a massive multi billion parameter model.
Because there’s so many parallel operations in machine learning, it quickly becomes vital to employ GPUs, rather than CPUs, in machine learning tasks. To parallelize matrix multiplications, GPUs use something called "fused multiply-add" (FMA) to quickly multiply rows by columns, then they do that operation numerous times to quickly calculate all the individual elements in the resultant matrix.
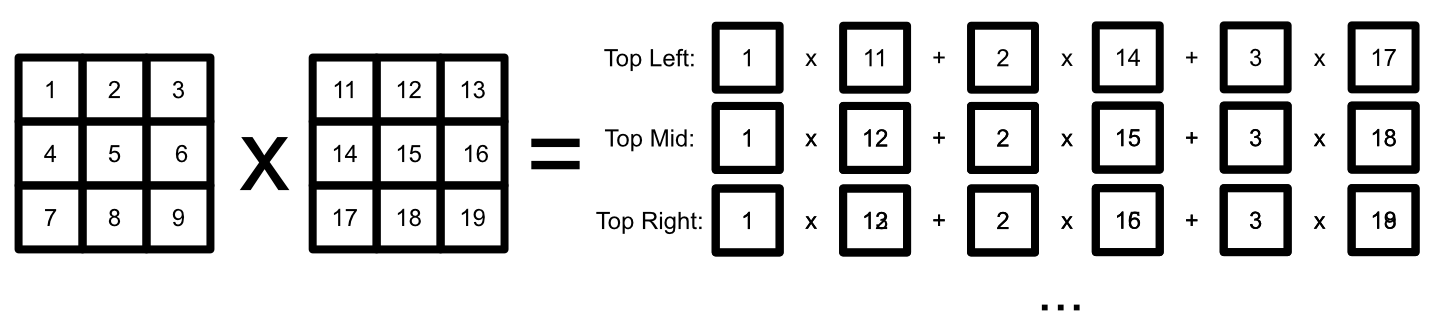
GPUs can do matrix multiplication way faster than a CPU, but they could be faster. In order to do matrix multiplication even more quickly, we need to introduce a new piece of hardware.
The Pendulum Swings
The general Vibe of the GPU, as described in the previous section, remained dominant for almost a decade. Any improvements largely consisted of scaling up the architecture. Smaller transistors to pack more computation into a single chip, more computational power, and better performance.
In 2015 Artificial intelligence was becoming big business. Because of this, GPUs were used to do a lot of "tensor" operations. A "tensor" sounds like a fancy idea, but you’re actually already familiar with them. A vector is a one dimensional tensor, a matrix is a two dimensional tensor, etc. Tensors are just some block of numbers in some dimension.
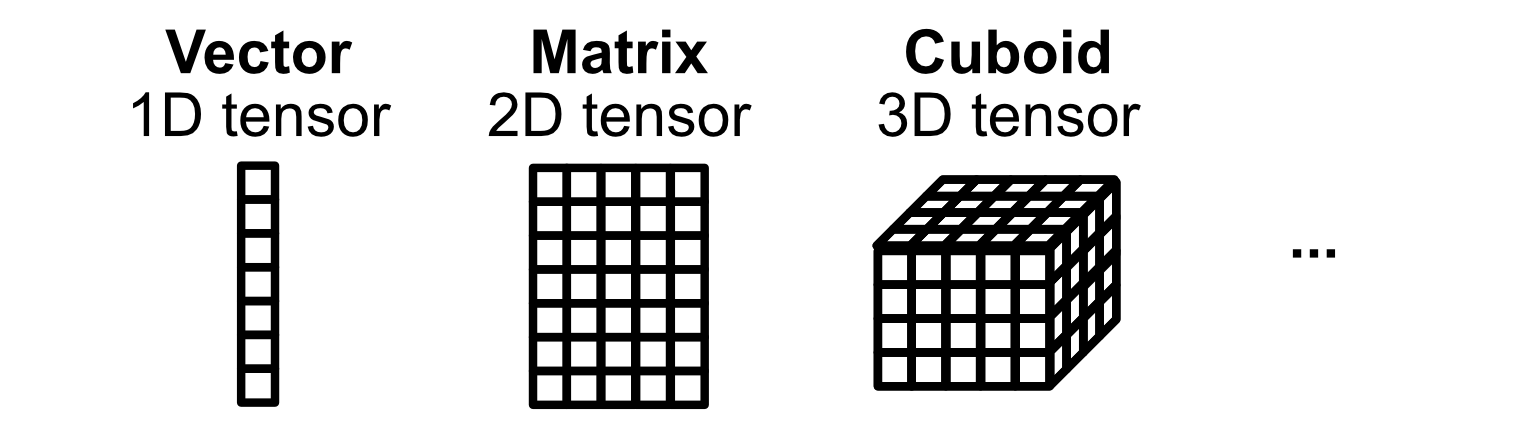
AI can be thought of as a bunch of tensor operations. Matrices multiplied by matrices, vectors added to vectors, etc. and while GPUs are much better than CPUs at doing tensor operations (due to their ability to parallelize), they’re not purpose built for tensor calculations specifically. GPUs can certainly do tensor operations, but there’s overhead required for GPUs to do them, which cuts into performance.
In their typical fashion, Google was quietly innovating behind the scenes. They developed a machine learning framework aptly called TensorFlow, and were experimenting with ways to improve their own AI processes. Among a lot of things, two questions began to stand out:
- What if we reduced the precision of a GPU?
- What if we made a GPU purpose built for tensor operations?
Thus, the TPU was born.
The TPU
TPU stands for "Tensor Processing Unit", and is like a GPU in a lot of ways but instead of focusing on Graphics, which is largely governed by vectors and a broad array of calculations, TPUs focus on computing with tensors and are designed to accommodate a relatively small choice of calculations.

The main job of a TPU is to do matrix multiplication.
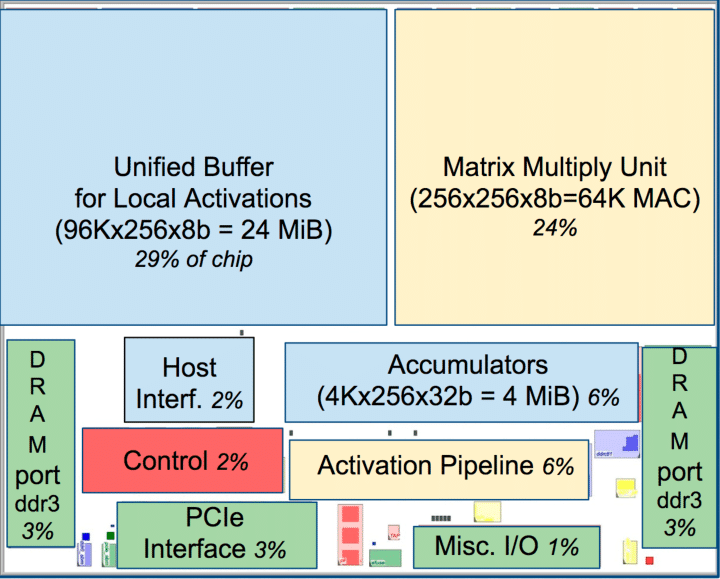
The TPU uses less precise numbers; still precise enough for AI, but less precise than the ones needed for physics simulations and graphics processing. That means the TPU can fit more operations in the same form factor. Also, the TPU can do matrix multiplication much more quickly by using a specialized matrix multiplication module. It does this by doing operations on entire vectors; a step above just parallelizing individual numerical calculations. Essentially, GPUs work on vectors of numbers, TPUs vectors of vectors. This makes TPUs less generalizable than GPUs, but the narrower scope allows for greater computational efficiency.
You can think of a TPU as, in some ways, a step backwards. Recall that the original GPU had purpose built hardware specifically for the graphics pipeline, and then subsequent GPUs employed a general purpose computing approach. Now, TPUs are going back to a purpose built approach, but for AI applications.
As manufacturing techniques become more sophisticated, all types of processors will become more powerful. However, as it becomes harder to squeeze more transistors onto a piece of silicone, hardware designers have been experimenting with designs that are maximally catered to specific use cases.
Nvidia realizes the power of this idea. Ever since their Volta microarchitecture released in 2017, Nvidia has included "Tensor Cores" within their GPUs, which are like putting tiny TPUs within their GPU.
This is a great video by Nvidia which highlights the performance gains of tensor cores from a high level, and has an especially handy video demonstrating how different types of parallelism can result in faster calculation.
I won’t harp on TPUs too much in this article because, to a large degree, they have many of the same general attributes and use cases as GPUs, they just happen to be a bit more performant for some applications. Also, with tensor cores in many modern GPUs, the distinction is often a bit fuzzy between the two anyway.
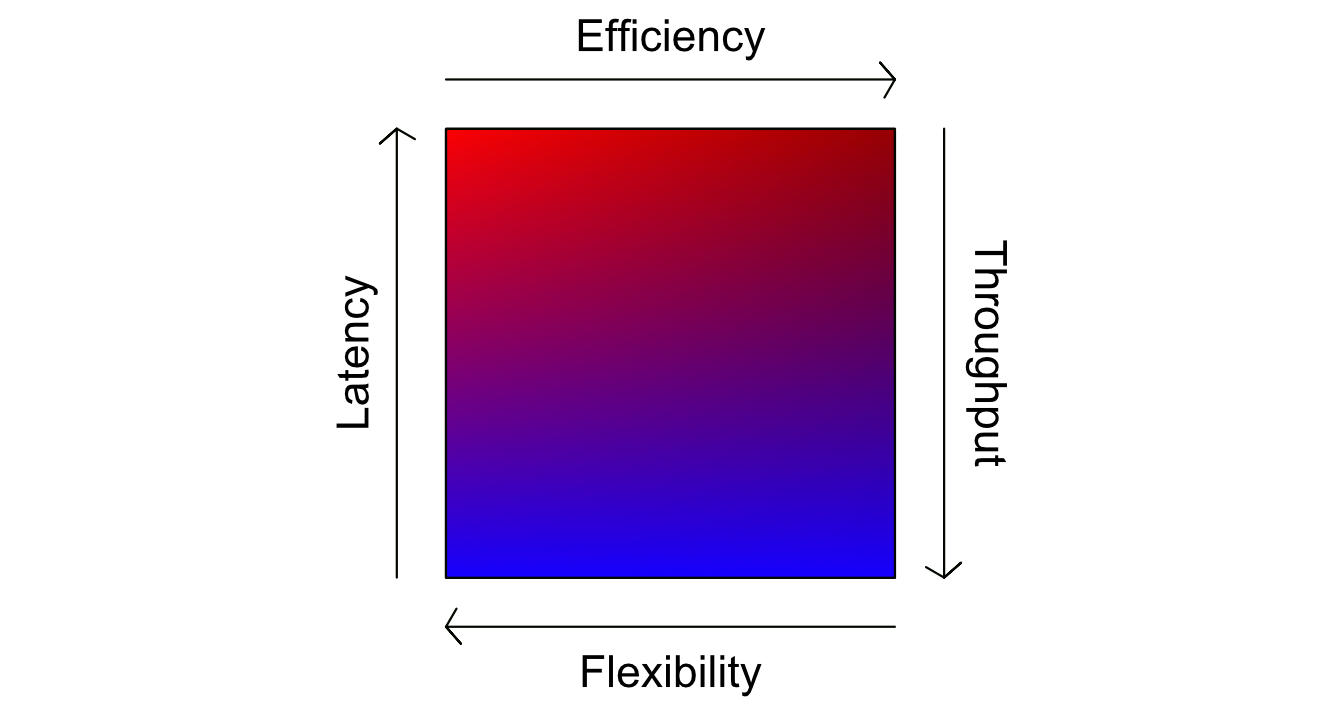
Dealing With Latency in Two Ways
I previously mentioned that CPUs employ cache to keep data close to cores so that calculations can be done as quickly as possible. GPUs also employ cache, but it’s not to reduce round trip latency. Rather, GPUs use cache to maintain throughput.
Instead of trying to describe this idea in terms of oversubscription, compute intensity, and memory efficiency (I recommend this video if you really want to get into the weeds), I think the core idea can be explained by the following image:
Even though a particular calculation might be fairly slow to get through a GPU, it uses cache to keep all it’s workers busy by having a large amount of backlogged data ready to process. CPUs, on the other hand, get calculations done quickly by optimizing cache to feed data to the right core as fast as possible, but can only handle a small number of calculations at a time. This subtle distinction, to a large degree, is why Groq exists.
How Latency Impacts Training vs Inference
The process of training an AI model basically consists of throwing a vast amount of data at the model, and asking it to update it’s internal parameters to result in a better output.
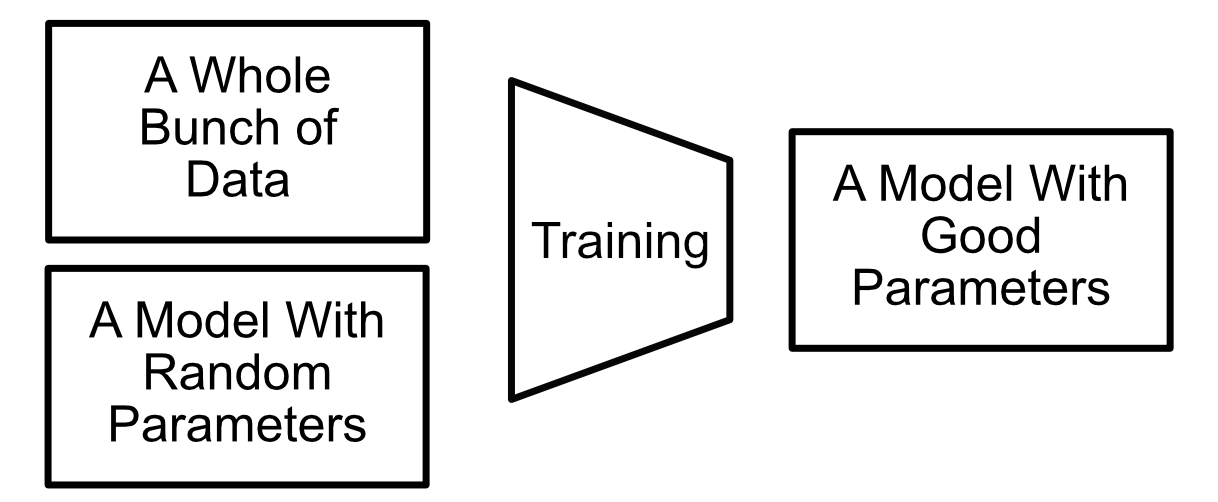
In training, we don’t really care too much about latency. If a model takes 3 days to train, no-one cares if the model is done a few milliseconds earlier or later. Training AI models is a classic throughput problem, and it’s a perfect use case for GPUs or TPUs.
Inference, on the other hand, is the process of actually using a model. You give a trained model data, and expect some reasonable response.
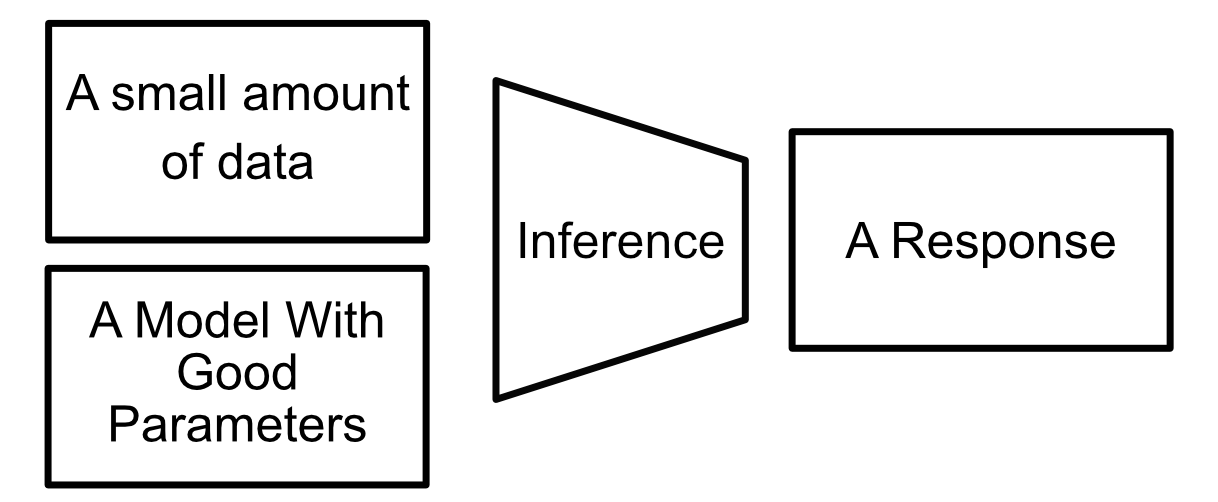
Latency does become a problem in some inference use cases. I cover autoregressive generation, for example, in my article about GPT.

Large language models like the ones used in ChatGPT are just big next word predictors. It’s all fine and dandy to say we don’t care about adding a few milliseconds of latency to the output of a model, but adding a few milliseconds of latency to every predicted word in an output sequence is a different story.
Groq was capable of generating 572.60 predictions per second with Mixtral 8x7b in one of my tests, for instance. That’s 1.7 milliseconds per prediction. Inefficient hardware adding milliseconds of delay per prediction could make that output take twice as long, or even longer.
Similarly, what if your prediction is in some sequence of operations? You would need to wait around for a specific prediction to finish to continue along with your data pipeline, which could have a real impact on both the performance and cost of an internet scale application.
As advanced prompting techniques like chain of thought, and agent systems which require LLMs to think about problems, become more common, it becomes more important for these language models to be able to generate results faster, lest the delay of model output cause unacceptable degradation of end products and services.
We have a problem. When we train a model GPUs are perfectly fine. However, when we go to make a prediction we need to wait around for the GPU to do all it’s slow parallelization stuff. We still can’t use CPUs because, while they have low latency, they just can’t do the number of computations necessary to run a large AI model. TPUs might be a bit faster than GPUs, but they’re really not much better.
Enter Groq.
Groq: Throw out Everything
Now that we have an understanding of the history of computational hardware, as well as some of the subtle design constraints around various hardware approaches, we have the necessary knowledge to understand Groq.
Groq is a chip that does tensor operations. It’s made of silicone. It has transistors and registers… And that’s pretty much all the similarities Groq has to a traditional computer. Groq isn’t just a chip, it’s a card, on a node, in a server, on the cloud. Groq is an entire unified computer architecture designed specifically to allow for high throughput at low latencies for internet scale AI inference.

In preparing for this article I had a conversation with Andrew Ling, the VP of software engineering at Groq. He described Groq as a first principles project. They looked at AI, the types of calculations needed to run AI, the software used to make AI, etc. and designed an entire computer system around that.
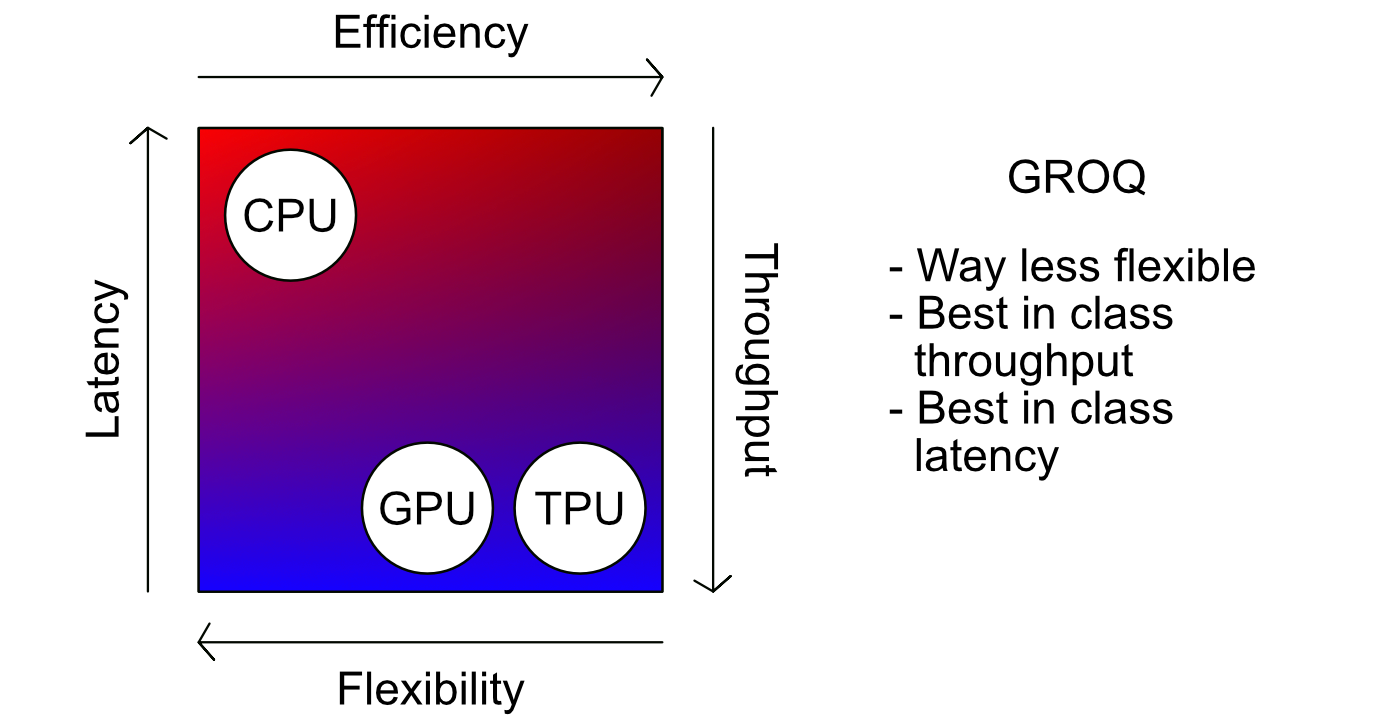
Unlike the CPU that was designed to do a completely different type of task than AI, or the GPU that was designed based on the CPU to do something kind of like AI by accident, or the TPU that modified the GPU to make it better for AI, Groq is from the ground up, first principles, a computer system for AI.
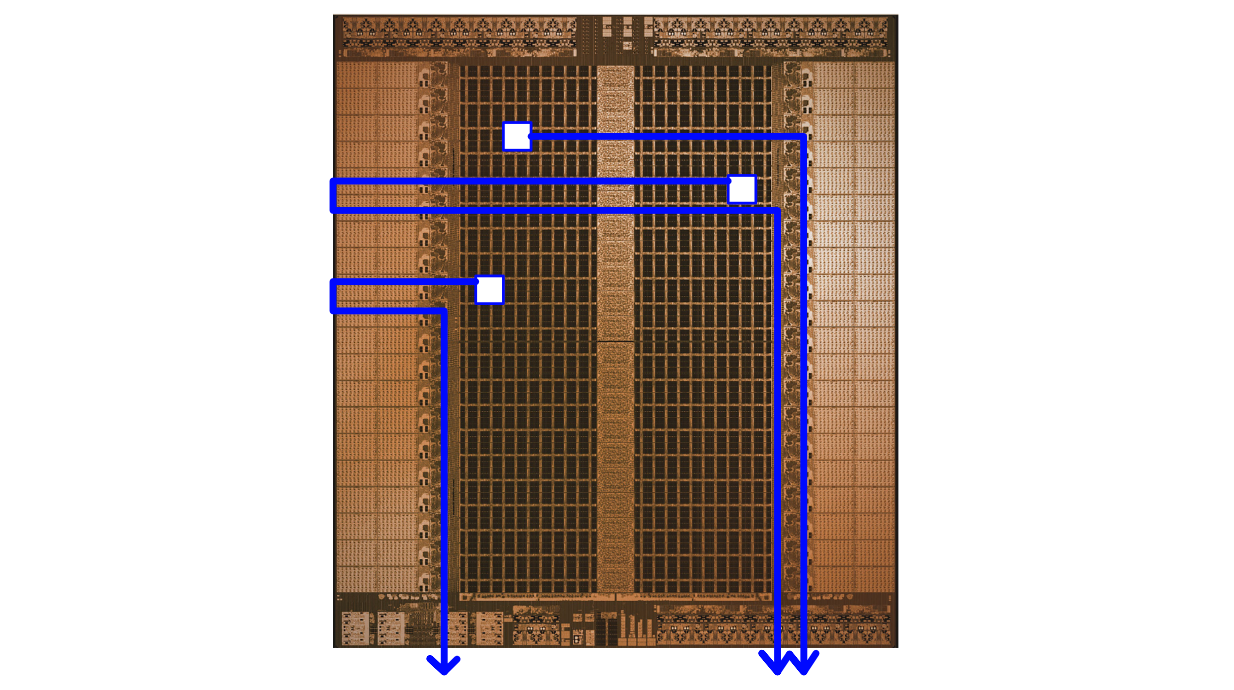
The core of the whole thing is the "Tensor Streaming Processor", (TSP). This is a massive single core chip designed specifically to do tensor operations in a machine learning context. Calling this thing a "single core" is weird because there’s so many things going on.

Basically, the TSP is organized into rows called superlanes. Each of these lanes contain all the necessary compute resources to run an AI model.

At the extreme ends are units specifically designed for matrix multiplication. These are kind of like Nvidias tensor cores, or the cores in a TPU. They allow for lightning fast matrix multiplication.

Next to the matrix multiplication units are switch units. These are purpose built to do very common operations like transposing (rotating) or shifting a matrix. A common calculation is to multiply a matrix by a transposed matrix, so it’s fitting that the switch units are directly next to the matrix multiply units.

The big dark areas are memory. And there’s a lot of it. The TSP packs in 220MB of SRAM on a single chip. That might not seem like a lot but SRAM is the memory used to make the super fast registers within the cores of CPUs and GPUs. Most GPUs only contain ~20MB of SRAM per chip, while the majority of the GPUs memory is DRAM (which is an order of magnitude slower than SRAM). So, Groq is able to squeeze in around 10x more high speed memory than a GPU.

In the very center of the TSP is the vector unit. The vector unit contains traditional ALUs, just like the ones found in CPUs, GPUs, and the humble Z80 we discussed way back at the beginning of the article. These ALUs allow the TSP to do pointwise vector operations, employ custom activation functions, and things of that nature. You can think of these like a tiny GPU within Groq, allowing Groq to do some more general purpose calculations as necessary.

At the top of the TSP is all the control circuitry which controls the entire core, and at the bottom of the TSP is I/O for getting data into and out of the chip.

As you can see, this is a pretty far cry from the CPU or GPU. There’s a single Core with a single control circuit, caching hierarchy got thrown out the window in favor of a bunch of high speed registers, and something like a GPU, the vector unit, is a stripe down the middle of the chip.
And things get even weirder.
Let’s try to understand how this chip works a bit better by observing how data flows through it.
How The TSP Processes a Stream of Tensors
Considering Groq is designed to efficiently run modern AI models, it’s no surprise that there are similarities in the way data flows through the TSP and the way data flows through an AI model. Virtually every AI model takes in some tensor, outputs some tensor , and has a bunch of tensor operations in the middle.

Groq employs something called a "stream", which allows vectors to flow through the Groq TSP in a similar way. I mentioned how Groq has superlanes which run laterally throughout the chip. "streams" flow through superlanes, and allow data to interact with the various components of the TSP.
And when I say flow, I really do mean flow. Data is constantly moving around a TSP, flowing through the chip, and through various functional components. This means Groq doesn’t need some cache hierarchy with a bunch of complicated control logic, Groq passes data from one component to another directly.
This is very different than both the CPU and GPU, which fetch data from cache in order to do some calculation, then send the data back to cache.

The Groq’s TSP is even weirder in terms of how it handles the execution of instructions. A CPU, or GPU, has some control circuit that reads instructions sequentially. It fetches data, then it performs the calculation.
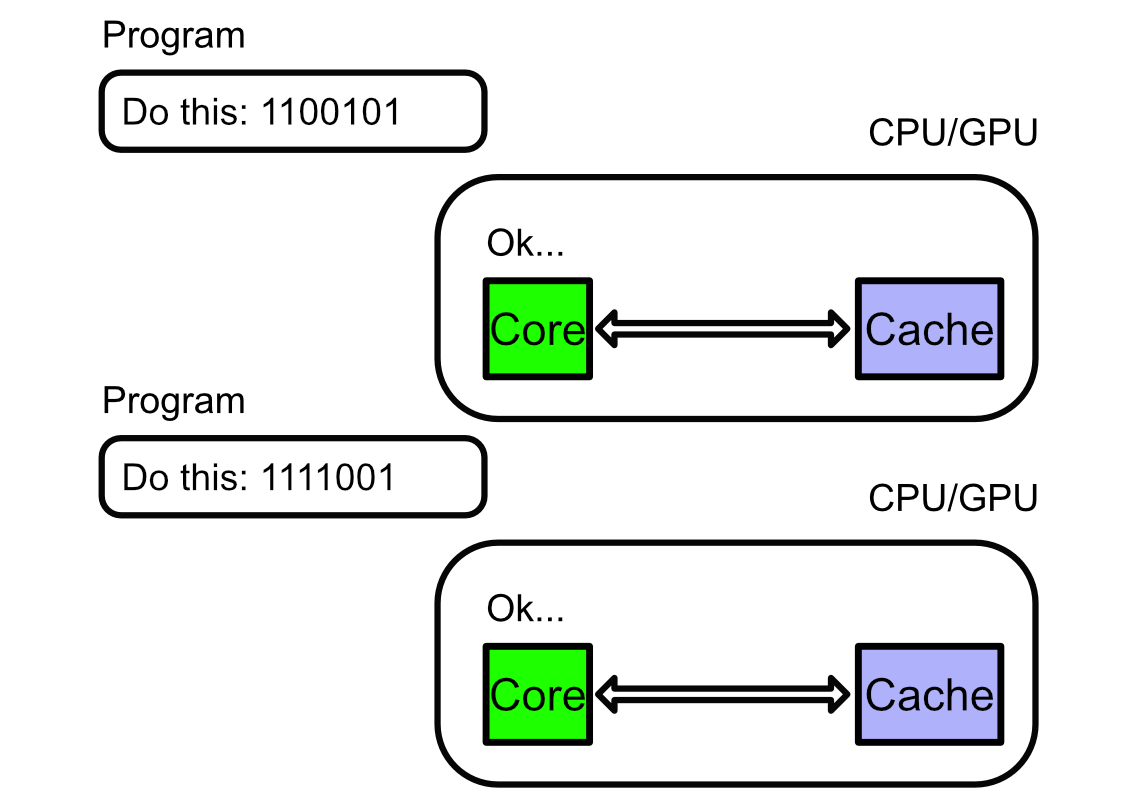
Groq, on the other hand, assigns a list of instructions to each functional unit, including the instruction to do nothing at all, ahead of time. As data streams through Groq, the functional components shuffle through instructions. If a functional unit has data, and an instruction to do, it does it.
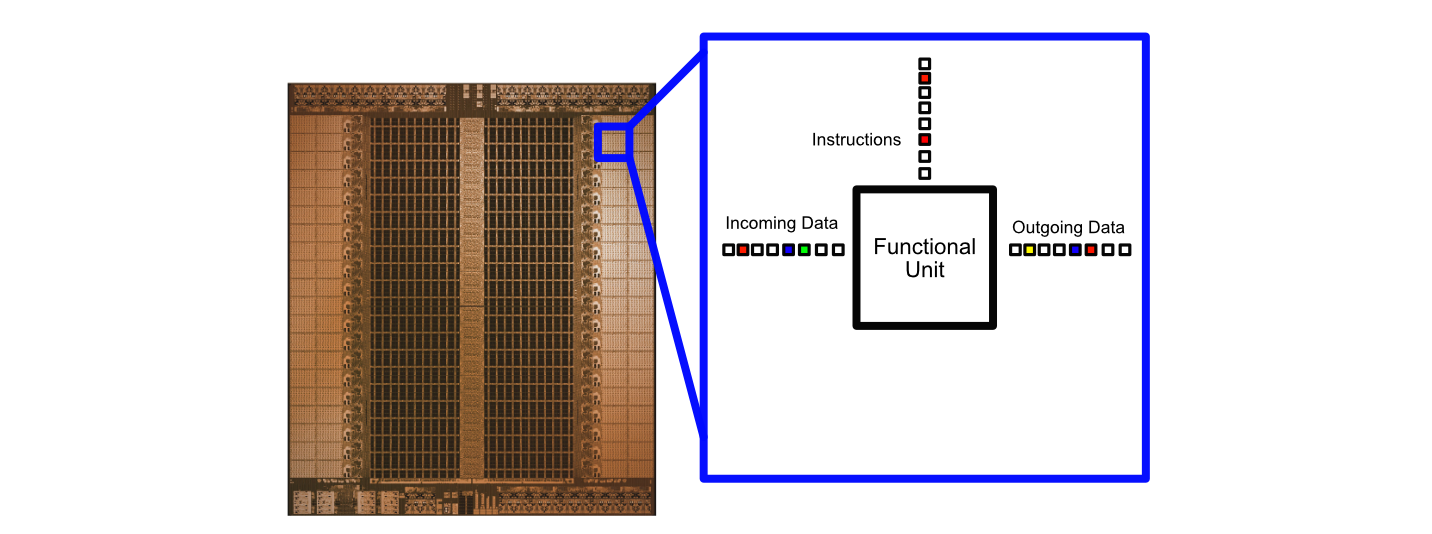
Of course, this approach doesn’t make any sense when you’re talking about a traditional program, where you might not know which operation to execute beforehand. However, our machine learning model is already defined, we know all the calculations required to make an inference, so we know what operations will need to be computed ahead of time.
I think of the TSP as many complicated games of space invaders. You have data shuffling back and forth through the chip, and each functional component has to time their decisions to do (or not do) operations just right.
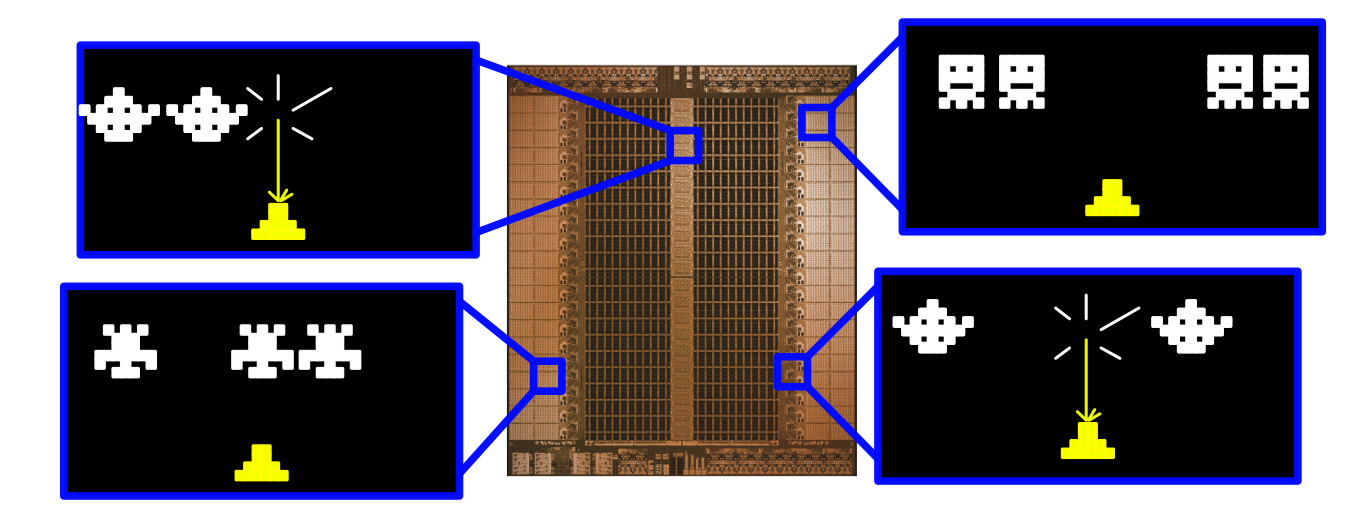
Groq knows how much data will be fed into the chip, where it will end up, what calculations that will be done, and how long those calculations will take; this is all figured out and optimized at compile time. This is all possible because of one of Groqs most important fundamental design characteristics; determinism.
Determinism
Determinism is the concept of knowing what will happen before it happens. When you write a simple program, and you already know what will happen, that’s a deterministic program.

Computers are ones and zeros, and a bunch of electronic components which use those ones and zeros to do simple math. From bottom to top, a computer knows what’s going on. Thus, a computer is deterministic.
Except, actually, most computers are not deterministic.
Your CPU is responsible for running a bunch of random things based on both your feedback, as well as the goings on of complicated software within your computer. You might close a tab. A piece of software might spool up a bunch of processes. There’s a lot of crazy complicated stuff going on in a computer, all based on random and complicated feedback, which makes it essentially impossible for a CPU to keep track of everything.
As a result, CPUs are greedy. They’re given data, they compute on that data, and they do it as fast as possible. In fact, modern CPUs often go faster than possible. Some CPUs guess work that they will need to do, and do it in the hopes that a program will ask for it to be done. Sometimes the CPU guesses right, sometimes wrong, and all in the name of trying to execute programs as quickly as possible.
many people think of computers like a ticking clock, perfectly executing a vast number of calculations in perfect harmony. In reality, it’s like a bunch of short order cooks flinging half prepared ingredients between each other.

GPUs and TPUs, in inheriting the core ideas of CPUs, also inherit this non-determinism. They’re greedy computational systems that try to do a bunch of calculations as quickly as possible, and have complex caching and control systems to help orchestrate how data gets distributed around a bunch of, essentially, independent computational systems. This messiness is largely required, and there’s a method to the madness which has been optimized by many brilliant minds, but it does result in energy, time, and money wasted on executions which are not strictly necessary.
Groq, on the other hand, is deterministic. For every tick of it’s 1.25GHz clock, Groq knows where data is, where it’s going, and what operations are being done. This is how Groq can perform multiple games of the most complicated version of space invaders without missing a beat. This is all possible because Groq works on problems that can be executed deterministically. You have a pre-defined AI model, and you need to pass data through that model to make some inference.

Scaling Up To The Cloud
You might be able to imagine the house of cards that computers are. The CPU is this greedy execution machine, trying it’s best to complete commands as fast as possible. It has to talk to a GPU which is also doing it’s own thing. Imagine being a company like OpenAI; you have a bunch of these computers in massive server rooms, all talking to one another, and you’re trying to get them to all, efficiently, run a single, massive, multi trillion parameter AI model.
In a word, chaos. In three words, absolute unadulterated chaos.
The folks at Groq talk about heterogeneous systems a lot. Basically, when you have a computer system made up of a bunch of independent actors, each doing their own thing, it can lead to a lot of headache. These servers are made of hardware designed for running a bunch of separate programs, not one massive AI model all at once. Groq’s TSPs exist within cards, which exist within nodes, which exist within racks. End to end, Groq is an entire unified compute system that is designed for AI.
This blows my mind; They’ve managed to preserve determinism throughout the entire system. Within a massive server room with a bunch of big machines, Groq can send a vector from one chip to another, and know when it will arrive down to around 10 clock ticks. If you’re familiar with networking at all, you know how insane that is.
This complete determinism from the TSP allows them to build determinism up to the server room, allowing Groq to optimize everything from single chip execution, to how large amounts of data can get sent through numerous cards to minimize latency. Also, because Groq knows everything about everything, it doesn’t have to worry about packets. It can just send raw data directly from one chip to another. No headers, no overhead. Faster. It’s easy to see how, when you have a multi trillion parameter language model running throughout an entire server room all working to answer a single question, this cohesiveness can be very useful in generating responses quickly.
Conclusion
This article could keep going on and on. I could talk about how Groq uses the dragonfly topology to optimize communication between components, or I could talk about how Groq is composed of plesiochronous links, which are almost synchronous, and how Groq uses software and hardware deskewing techniques to maintain global synchronicity. We’re talking about a $1.1 billion startup here. I can’t cover everything in one article.
Unless you’re planning on starting your own hardware company though, a lot of these details aren’t really important. What is important is this:
- CPUs, GPUs, and TPUs are a vital tool in many applications, but they have their drawbacks
- Latency is a very important concept in hardware, and how latency is managed has a big impact on which hardware is useful in a given application.
- By hyper specializing on AI model inference, Groq is capable of both remarkable latency and throughput, positioning itself as the cutting edge choice for hardware accelerated inference.
- As hardware constraints become more difficult to overcome, and performance requirements become more demanding, we may see an era of purpose built hardware emerging in the near future.
Follow For More!
I describe papers and concepts in the ML space, with an emphasis on practical and intuitive explanations.

Attribution: You can use any image in this post, and/or a small excerpt, for your own non-commercial purposes so long as you reference this article, https://danielwarfield.dev, or both. Copying of this entire article, or sections of this article, is not permitted. An explicit commercial license may be granted upon request.
Further Reading
Sorted based on relevance and importance to the content of this article.
Speculative Sampling – Intuitively and Exhaustively Explained
In this article we’ll discuss "Speculative Sampling", a strategy that makes text generation faster and more affordable without compromising on performance. First we’ll discuss a major problem that’s slowing down modern language models, then we’ll build an intuitive understanding of how speculative sampling elegantly speeds them up, then we’ll implement speculative sampling from scratch in Python.
Transformers – Intuitively and Exhaustively Explained
In this post you will learn about the transformer architecture, which is at the core of the architecture of nearly all cutting-edge large language models. We’ll start with a brief chronology of some relevant natural language processing concepts, then we’ll go through the transformer step by step and uncover how it works.
GPT – Intuitively and Exhaustively Explained
In this article we’ll be exploring the evolution of OpenAI’s GPT models. We’ll briefly cover the transformer, describe variations of the transformer which lead to the first GPT model, then we’ll go through GPT1, GPT2, GPT3, and GPT4 to build a complete conceptual understanding of the state of the art.
What Are Gradients, and Why Do They Explode?
Gradients are arguably the most important fundamental concept in machine learning. In this post we will explore the concept of gradients, what makes them vanish and explode, and how to rein them in.








{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}