towards Deep Relational Learning
Graph structured data are all around us. With the recent advent of deep learning, it seems only natural that researchers started to explore this data representation with neural networks, too. Currently, we experience an explosion of the Graph Neural Network (GNN) class, with countless models being proposed under a variety of (catchy) names. Nevertheless, most of these models are based on the same simple graph propagation principle.
To look at the problem from a broader view, we will here reveal the underlying GNN principles from the general perspective of _Relational Machine Learning_, which we discussed in a previous article.
- Relational machine learning, in contrast to the (mostly) empirically-driven deep learning, builds heavily on the formal language of relational logic which, __ in turn, provides some solid principles for representing and manipulating structured data, such as various _sets, graphs, and relational database_s.
In this article, we will then explore an elegant way to connect relational learning with neural networks. This will allow us to elegantly capture the GNN models in a very transparent manner, allowing to subsequently generalize beyond their current state towards "Deep Relational Learning".
A Brief History of Relational Learning with NNs
While for many of us, the recent popularization of GNNs might be our first encounter with learning from structured data, there has actually been a long stream of research aimed at extrapolating machine learning models to these data representations.¹
Under the umbrella of _relational learning_, this problem has been dominated for decades by the approaches rooted in relational logic and their probabilistic extensions, referred to as _Statistical Relational Learning_ (SRL).
However, neural networks offered highly efficient latent representation learning, which was beyond the capabilities of the logical systems. Here, instead of treating the symbols as independent atomic objects, the idea of learning embeddings, i.e. distributed fixed-size numerical (vector) representations of the (discrete) symbolic objects, was introduced.
- It dates back to Linear Relational Embeddings [2], with follow-up papers proposing different schemas to improve learning and extend the embedding of symbols to their compositions. This stream of work also includes the now widely popular "word2vec" [3].
Learning embeddings of structures, such as trees, then dates back to Recursive Auto-Associative Memories [4].³² The representation of a (logical) relation in these works was typically approached as a similarity measure, parametrized e.g. by a tensor, between couples of objects (embeddings). This approach later became popular as Recursive Neural Networks [6].³³
Somewhat in parallel, the relational learning community proposed various modifications to adapt classic neural networks for relational (logic) representations, too. Much in the spirit of the SRL, the declared aim for the models here was to properly combine selection and aggregation bias, i.e. learn how to select relational patterns and how to aggregate information out of them at the same time.
- Considering merely the aggregation setting here corresponds to "multi-instance learning", i.e. learning from (independent) sets of samples, which was addressed in the relational learning community, too [8]. Recently, similar models then also resurged with "Deep Sets" [7] and alike architectures.
This SRL view motivated "Relational Neural Networks" [9] – a model with a structure based on a particular relational database schema from which the samples were to be drawn. A similarly motivated method was then introduced as the (original) "Graph Neural Network model" (GNN) [10] for graph data, respectively. Back then, these two "competing" methods were further reviewed and compared in [11] and [12].
The important insight here is that these methods followed the concept of dynamically structured neural models. This paradigm shift in computation then enabled to apply the core idea of end-to-end learning from raw relational data. This allowed the models to directly exploit the relational bias presented by the input examples, in contrast to the (propositionalisation) approaches based on preprocessing the structures into fixed-size vectors (tensors).
A Prior on Graph Neural Networks
The modern GNN variants can then be seen as a continuation of this original GNN concept (although they are typically simpler [13]). A common explanation here builds on the idea of "message passing", where each node is viewed as sending "messages" to its neighbors within the input graph Xi. While this explanation draws some important connections to the Weisfeiler-Lehman heuristic,¹⁴ it is perhaps more revealing to view GNNs directly through the structure of their underlying computational graph(s) Gi, similarly to viewing classic deep learning models.
From this viewpoint,¹⁵ GNNs can be seen as an extension of the standard CNN techniques of convolution and aggregation to irregular graph structures Xi with arbitrary edges (E) between the nodes (N). To facilitate this, instead of a static architecture sitting on a fixed pixel grid, they dynamically unfold each computational graph Gi from each input graph Xi.
With that, a GNN is then simply a "standard" multi-layered feed-forward CNN architecture, with the only caveat that the structure of each layer k in the computational graph Gi exactly reflects the structure of the input graph Xi.
![A computational graph of a typical GNN ("g-Sage") with weigh-sharing ("convolution") within each layer, unfolded over some irregular input graph X (purple, left). The individual convolution operation nodes (C, ** orange) are followed by aggregation operations (Agg, blue) that form input into the next layer representation (X**¹) of the input graph (lighter purple). Image by the author (from [32]).](https://towardsdatascience.com/wp-content/uploads/2022/02/1EFQ-nw1MnT3alOZoeasiRQ.jpeg)
Particularly, every node N in each input graph Xi can be associated with a feature vector (or embedding), forming the input layer representation in the computational graph Gi. For computation of the next layer k representations, each node N calculates its own hidden representation h(N) by aggregating A ("pooling") the values of the neighboring nodes M : (N,M)∈ E adjacent in the input graph Xi. These can be further transformed by some parametric function C (convolution), which is being reused with the same parameterization W₁ within each respective layer k as:

- In some GNN models, this h˜ representation is further combined through another Cw₂ with the "central" node’s N representation from the previous layer k−1 to obtain the final updated value for layer k as:

This general "aggregate and combine" [17] computation scheme then covers a wide variety of the popular GNN models, which then reduces to the choice of particular aggregations A and activations/convolutions Cw. For instance in GraphSAGE [18], the operations are

while in the popular Graph Convolutional Networks [19], these can be even merged into a single step as

and the same generic principle applies to many other GNN works [17].²⁰
A critical perspective. Recently, a very large number of different variants of this computation formula have been proposed. In essence, each such introduced GNN variant came up with a certain combination of (common) activation and aggregation functions, and/or proposed extending the model with layers borrowed from other neural architectures. Ultimately, introducing exhaustive combinations of these common DL blocks under novel GNN names led to the ZOO of GNN models we see today, with largely ambiguous performances [21].³¹
To actually see through the principles of the models, it now seems that, after this rather common early research stage of "low-hanging fruit" collection, the GNN domain might benefit from some deeper insights…
The Perspective of Symmetries
A very insightful perspective on this recent (r)evolution of the GNN model class was then introduced by M. Bronstein et al., viewing the DL architectures through their underlying assumptions about symmetries in each domain. Starting with the common notion of symmetry from the field of geometry, this approach was then coined as "Geometric Deep Learning" (check out Michael Bronstein ‘s excellent article series on the topic here on Medium).
Naturally, all machine learning models are inherently trying to explore symmetries, i.e. some forms of repeated regularities, in the input data distributions. However, in some structured model classes, such regularities are present also in the model parameter space.
In deep learning, this is perhaps best known from the CNNs, designed to reflect invariance w.r.t. translation (shift) in pixel grids, which is the most popular example of such a geometric symmetry.
- This means that no matter where you shift the input pattern (within the scope of the "receptive field"), the model output will remain the same.²²

In a similar fashion, the Recurrent and Recursive Neural Networks were designed to reflect the recursive symmetry in linear and tree structures.
![The common weight sharing scheme and symmetry of a recurrent (left) and recursive (right) neural network. Image by the author (from [32]).](https://towardsdatascience.com/wp-content/uploads/2022/02/0eK_LOry45UsY8Ict.png)
Finally, the GNNs try to do the same with generic graph invariants, i.e. functions respecting graph isomorphism (permutation) __ symmetries.

The models reflecting the complete permutation symmetry on sets, such as the "deep sets", can then be seen as a "base case", where all the possible input permutations are considered equivalent.
- While in the preceding models, only a subset of the possible input permutations is treated invariantly (imagine, e.g., shifting image of a cat vs. shuffling all its pixels randomly).
Naturally, incorporating the correct prior about the respective form of symmetry in each learning domain ultimately leads to better sample efficiency and generalization, and the history proved models allowing to exploit such priors very useful.
Beyond Geometric Symmetries
Traditionally, most of the deep learning progress has been driven empirically through applications, rather than some prior top-down theoretical analysis. This perhaps also motivates exploration in the main direction of the geometric symmetries arising in computer vision, being the most prevalent application domain. However, symmetries in neural networks need not to be confined to geometry.
Example. For a simple demonstration, let us revisit the simple logical XOR example from the previous article on Neural-Symbolic Integration.
- There we explained how encoding simple logical functions, such as AND and OR, played an important role in the early evolution of neural networks, where the inability of early "NNs" to learn the XOR problem caused a major setback.
Even though the solution to the XOR problem has been trivially known for decades, it remains, interestingly, non-trivial to learn properly even with modern-day deep learning! Particularly, while an optimal solution may consist of as few as 2 (or even 1) hidden neurons, it is very difficult to actually correctly train parameters of such a small network, as the optimization will mostly get stuck with sub-optimal solutions.²³ (try it easily for yourself!)
It is only when we employ the common ("brute-force") approach of increasing the network parameterization to much higher dimensions than necessary (app. 10+ hidden neurons for the binary XOR), the training finally becomes reliable.
While brute-force is often an answer in deep learning, such as when resorting to dataset augmentation, we can do better by incorporating the correct prior into the models instead. Particularly, here we know that the XOR function is symmetric since XOR(x₁,x₂) = XOR(x₂,x₁). Hence, we do not need to treat all the permutations independently, and there should be some internal symmetry in the neural parameterization of the function, too.
Consequently, instead of the (common) overparameterization approach, we can actually keep the small network size and further reduce the number of parameters by tying the weights.
![An example of an (automatically induced) symmetric weight-sharing prior for the binary XOR function learning. Image from [25] by the author's student Martin Krutsky.](https://towardsdatascience.com/wp-content/uploads/2022/02/1Mtd1qc5w2Uvpr8XoRDK92Q.png)
Such weight sharing then significantly improves learning of the logical functions,²⁵ similarly to the DL models employing the geometric symmetries via convolution in computer vision (and other applications).
Capturing Symmetries with Logic
Wouldn’t it be nice if, instead of overparameterization and other empirical (brute-force) tricks patched on top generic models, we could generally start from encoding the correct prior knowledge into the models to begin with?
The Geometric Deep Learning movement now suggests one such interesting perspective with the geometric symmetries-based view of neural network practices. However, this principle has for long been also studied in the field of relational learning as a logical "background knowledge" incorporation.
Is there any link between these two approaches? Does relational logic have anything to do with the (geometric) symmetries?
Yes. Despite being commonly overlooked (or looked down upon) by DL proponents, relational logic is actually a perfect formalism for capturing all sorts of symmetries and discrete domain regularities.²⁶
To align with the "geometric" interpretation, let us start with the simplest notion of the permutation symmetry in a set. With logic, there is no need to reinvent the wheel for this, as we already commonly define sets in logic as an enumeration of objects X satisfying a given property, i.e. { X | X is a node } or simply N(X) for some unary (property) relation N. Note that there is no notion about any ordering of the elements X in this representation of a set, and the corresponding permutation symmetry is thus respected by design!
This can then be directly generalized to the graphs, which are simply a case of a binary logical relation. Thus, to represent a graph, we can just write Edge(X,Y) to represent the set of all its edges. Naturally, we can also specify the sets of the corresponding nodes as Node(X) and Node(Y) here, too. Again, there is no notion about any ordering of the nodes or edges in such a representation.
- Moreover, relational logic does not stop with the graphs, and the same principles directly apply to higher-arity structures Relation(X,Y,Z,…) and their combinations through logical connectives (forming, e.g., the formal model for relational databases and SQL).
While every (former) computer science student is surely familiar with this formal (database) representation and the respective relational algebra/logic operations, it might not be directly obvious that such a formal concept can be used in machine learning practice. However, this has been exactly the point of the lifted modeling paradigm [27] (described in our previous article on relational learning), where this expressiveness of the relational logic formalism has been directly used to capture symmetries in machine learning problems.
Importantly, the symmetries here were not just descriptive, but the relational logic has been directly __ used to _encode graphical model_s, such as in the popular Markov Logic Networks [16].

However, while encoding priors on domain symmetries with relational logic into graphical models has been well studied for decades, it seems surprisingly lacking in deep learning.
- Sure, there is a certain distaste for logic in the deep learning community. Still, given the historical interplay between neural networks and propositional logic, this lack of foundations for logic-based symmetries in neural networks seems somewhat surprising.
However, it was exactly the "propositional fixation" of the standard neural networks that restricted them from capturing interesting (lifted) symmetries in learning problems, and complicated the integration of deep learning with relational logic, as outlined in the last article.
Deep Relational Learning
But wait a minute, now we have the powerful GNNs! They do not suffer from the propositional fixation anymore, since they can capture graph data. Can’t we just turn everything into graphs now, and use GNNs to solve all our problems?
Sure, graphs are ubiquitous and chances are that if you try, you can turn whatever problem at hand into a graph representation in one way or another. Consequently, it is very convenient to just apply one of the plethora of the off-the-shelf GNN models and see if you get lucky with some tuning.²⁸
However, note that this is yet another "if all you have is a hammer…" cognitive bias, analogous to the previously discussed "turn everything into vectors" methodology of propositionalization.
In the end, the GNNs are but a particular graph-propagation heuristic, with inherent limitations stemming from the underlying WL. Importantly, even if a GNN could capture the graph structure properly (beyond WL), this still would not guarantee anything about its actual learning (generalization) capabilities, similarly to how it is, apparently, not sufficient to stick with simple 2-layered NNs based on the universal approximation theorem [29].
That is why we design more and more sophisticated models and learning representations that directly reflect the structures of our problems instead. Consequently, turning complex relational learning representations and reasoning algorithms beyond graphs and graph propagation back into GNNs might not be the best idea.
So, wouldn’t it then be nice if, instead of trying to embed the more complex relational problem representations into graphs and GNNs, we could use the expressiveness of relational logic for some full-fledged "deep relational learning", capturing the symmetries in the current neural models as a special case, similarly to how the lifted graphical models generalized the standard graphical models in SRL?
As you might guess by now, there is a learning framework that does exactly that. Particularly, it takes the lifted modeling strategy and extrapolates it into the deep learning setting. This paradigm then enables to take the familiar correspondence between neural networks and propositional logic straight onto the relational level.
Consequently, in the same sense in which propositional logic is lifted to the higher expressiveness of relational logic, the framework lifts classic neural networks to a more expressive version of these models called "Lifted Relational Neural Networks" [34].³⁵
Lifted Relational Neural Networks
Similarly to the lifted graphical models, at the core of the "Lifted Relational Neural Networks" framework is a relational logic-based language for defining neural models, further referred to as "NeuraLogic". The language is directly derived from Datalog (or Prolog), which is commonly used for advanced database querying and logic programming, with one extra feature – it is differentiable.
- While there are many frameworks for differentiable programming now, NeuraLogic differs significantly by being declarative. This then allows to express some complex algorithms and principles in a very concise and elegant manner, which applies particularly for the relational problems exhibiting all sorts of regularities (symmetries).
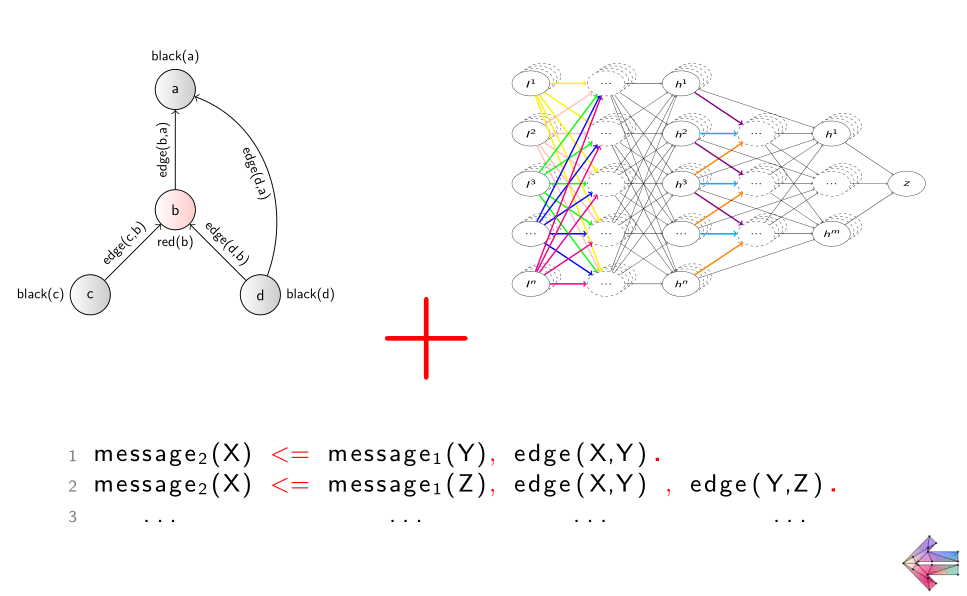
Example. Let us follow up on the above introduced formal principle of how relational logic captures symmetries in sets and graphs, and make it directly actionable while building a GNN. Particularly, we now know that a graph is a set of edges (edge(X,Y)) between nodes (node(X) and node(Y)). We then know that the generic GNN computation rule is to propagate/aggregate representations of nodes to their neighbors, which can be put into a logical rule as:
node2(X) <= W node1(Y), edge(X, Y).…and that’s it, really! This is a runnable code for a GNN (a GCN [19], in particular³⁰) in the NeuraLogic language. It reads as:
"To compute representation ‘node2‘ of any object X, aggregate a ‘W‘-eighted representation ‘node1‘ of all objects Y, where ‘edge‘ holds between the two."
- Those inclined to database interpretation of relational logic may read this as: "Join tables ‘node1’ and ‘edge’ on the column Y, group by X, and aggregate into a new table ‘node2‘ ".
Running this logical rule in the NeuraLogic framework then exactly corresponds to running a GCN in some conventional framework, i.e., it will execute the
formula discussed earlier. Naturally, the specification of the activation (σ) and aggregation (Agg) functions (and other hyperparameters), can be added to the rule, too. However, you can as well leave them like this at their defaults (tanh+avg) to enjoy the clarity of the underlying principle of the GCNs, i.e. the invariance w.r.t. the local permutations of the nodes and the respective edges.
With that, in NeuraLogic, the definition of the model symmetry prior becomes the code for the model itself!
Importantly, this rule is completely generic, i.e. there is no specific functionality in the whole NeuraLogic framework designed specifically for graphs or GNNs.
- Similarly simple lifted rules then encode the various recurrent/recursive and other symmetric weight-sharing (convolutional) schemes in deep learning models exemplified with colors in the images throughout this article.
This means that you can just as easily write arbitrary relational rules, encoding novel neural modeling constructs with advanced symmetry priors, and capture complex relational learning principles beyond the GNNs [36].
<iframe src="https://cdn.embedly.com/widgets/media.html?src=https%3A%2F%2Fwww.youtube.com%2Fembed%2F-5h-h0ukXk0%3Ffeature%3Doembed&display_name=YouTube&url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3D-5h-h0ukXk0&image=https%3A%2F%2Fi.ytimg.com%2Fvi%2F-5h-h0ukXk0%2Fhqdefault.jpg&key=a19fcc184b9711e1b4764040d3dc5c07&type=text%2Fhtml&schema=youtube" title="A sneak peek into "Beyond Graph Neural Networks with Lifted Relational Neural Networks" [32]" height="480" width="854">
While we conclude with this sneak peek on deep relational learning with Lifted Relational Neural Nets **** here, we will explore the NeuraLogic framework in detail in the next article, where we will showcase its practical usage, expressiveness, and computational efficiency.
- The most straightforward, and historically dominant, approach was to turn the relational data into fixed tensor representations as a preprocessing (propositionalization) step which however, as discussed previously, conceals a number of downsides.
[2] A. Paccanaro and Geoffrey E. Hinton. "Learning distributed representations of concepts using Linear Relational Embedding." In: IEEE Transactions on Knowledge and Data Engineering 13.2 (2001), pp. 232–244. issn: 10414347
[3] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. "Distributed Representations of Words and Phrases and their Compositionality." In: Advances in Neural Information Processing Systems 26 (2013), pp. 3111–3119.
[4] Jordan B. Pollack. "Recursive distributed representations." In: Artificial Intelligence 46.1–2 (1990), pp. 77–105. issn: 00043702.
[5] Geoffrey E. Hinton. "Mapping part-whole hierarchies into connectionist networks." In: Artificial Intelligence 46.1–2 (1990), pp. 47–75. issn: 00043702.
[6] Richard Socher, Danqi Chen, Christopher D Manning, and Andrew Ng. "Reasoning with neural tensor networks for knowledge base completion." In: Advances in neural information processing systems. Citeseer. 2013, pp. 926–934.
[7] Zaheer, Manzil, et al. "Deep sets." arXiv preprint arXiv:1703.06114 (2017).
[8] Ramon, J., & DeRaedt, L. (2000). Multi-instance neural networks. In Proceedings of ICML-2000 workshop on attribute-value and relational learning.
[9] Hendrik Blockeel and Werner Uwents. "Using neural networks for relational learning." In: ICML 2004 workshop on statistical relational learning and its connections to other fields. 2004, pp. 23–28.
[10] Franco Scarselli, Marco Gori, Ah Chung Tsoi, Markus Hagenbuchner, and Gabriele Monfardini. "The graph neural network model." In: IEEE transactions on neural networks 20.1 (2008), pp. 61–80
[11] Werner Uwents, Gabriele Monfardini, Hendrik Blockeel, Franco Scarselli, and Marco Gori. "Two connectionist models for graph processing: an experimental comparison on relational data." In: MLG 2006, Proceedings on the International Workshop on Mining and Learning with Graphs. 2006, pp. 211–220
[12] Werner Uwents, Gabriele Monfardini, Hendrik Blockeel, Marco Gori, and Franco Scarselli. "Neural networks for relational learning: An experimental comparison." In: Machine Learning 82.3 (July 2011), pp. 315–349. issn: 08856125.
[13] Lamb, Luis C., et al. "Graph neural networks meet neural-symbolic computing: A survey and perspective." arXiv preprint arXiv:2003.00330 (2020).
- The GNN models can be viewed as a continuous, differentiable version of the famous Weisfeiler-Lehman (WL) label propagation algorithm used for graph isomorphism refutation checking. In GNNs, however, instead of discrete labels, a continuous node representation (embedding) is being successively propagated into nodes’ neighborhoods, and vice versa for the corresponding gradient updates.
- Accepting this view of a dynamic computation graph, which is very similar to the previously introduced recursive networks, then makes the model stateless, which removes possible ambiguities stemming from the message passing explanation within the input graph.
[16] Richardson, Matthew, and Pedro Domingos. "Markov logic networks." Machine learning 62.1–2 (2006): 107–136.
[17] Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. "How powerful are graph neural networks?" In: arXiv preprint arXiv:1810.00826 (2018).
[18] Will Hamilton, Zhitao Ying, and Jure Leskovec. "Inductive representation learning on large graphs." In: Advances in neural information processing systems. 2017, pp. 1024–1034.
[19] Thomas N. Kipf and Max Welling. "Semi-Supervised Classification with Graph Convolutional Networks." In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24–26, 2017, Conference Track Proceedings. OpenReview.net, 2017
- We note we only discussed "spatially" represented graphs and operations. However, some GNN approaches represent the graphs and the convolution operation in spectral, Fourier-domain. However, we note that these again mostly follow the same "aggregate and combine" principles, and can be rewritten accordingly [17].
[21] Dwivedi, Vijay Prakash, et al. "Benchmarking graph neural networks." arXiv preprint arXiv:2003.00982 (2020).
- More precisely, the shared weights induced by application of the convolutional filters introduce equivariance w.r.t. the respective transformation of the filter, while incorporating the aggregation function (e.g. max or avg) on top via pooling extends it further into the transformation invariance.
- Although there are, theoretically, no local minima in the error function (e.g., cross-entropy) here, there are diverging regions towards the borders of the parameter space and large saddle points, making the gradient-based optimization very difficult.
-
Similarly for the simpler AND and OR functions which are, however, too trivial to demonstrate the significance of this overparameterization problem with NNs. Interestingly, while the functional parallel between the logic units and neurons has been well acknowledged, to the best of our knowledge no work has previously exploited the trivial symmetries of the logical functions in the corresponding neural weights to improve learning.
[25] Martin, Krutský. Exploring symmetries in Deep Learning. BSc thesis. Czech Technical University in Prague, 2021.
- Naturally, logic is more suited for describing regularities in the discrete domains, while the geometric explanation is more natural in the continuous domains, such as computer vision and robotics.
[27] Kimmig, Angelika, Lilyana Mihalkova, and Lise Getoor. "Lifted graphical models: a survey." Machine Learning 99.1 (2015): 1–45.
- This is now even more tempting, given the recent hype around the GNN concept and, with enough hyperparameter tuning, people have indeed successfully utilized GNN on a wide range of problems. Sure enough, even the logical expressions can be turned into a graph representation, as outlined in [13]. However, this does not mean that GNNs are a proper algorithm to solve the underlying problem of logic inference!
[29] Cybenko, George. "Approximation by superpositions of a sigmoidal function." Mathematics of control, signals and systems 2.4 (1989): 303–314.
- Note the alignment with the classic matrix view H² = σ (W H¹ A) **** of the GCN rule, where H¹² are the node representation matrices and A is the adjacency matrix (analogous to the ‘edge’ predicate here).
- A number of critical review papers revealed that the actual performance gains of a lot of these GNN modifications are, as opposed to the traditionally self-claimed state-of-the-art results in all the papers, very often rather insignificant, sometimes failing to beat even simple (unstructured) baseline models [21], rendering the need for the large number of the GNN variants, a bit dubious.
- A similar line of work arose also from the old idea of recursively transformed reduced descriptions [5], upon which auto-encoders and many other works have been building.
- Note that, in principle, recursive neural networks can be thought of as a general form of recurrent neural networks, which unfold recursively over sequences, while recursive networks unfold over (regular) trees.
[34] Sourek, Gustav, et al. "Lifted relational neural networks." Journal of Artificial Intelligence Research (2018).
- Interestingly, this approach with various modeling constructs, including some GNN and subgraph-GNN variants, was already published in 2015, and later (2017) also extended to automated learning of such constructs. However, the explanation of the framework was rooted in relational logic instead of (just) graphs, which probably looked bizarre to the ML audience.
[36] Gustav Sourek, Filip Železný, and Ondřej Kuželka. "Beyond graph neural networks with lifted relational neural networks." Machine Learning 110.7 (2021): 1695–1738.
The author is profoundly grateful to Ondrej Kuzelka for the countless ideas in the underlying concept of Lifted Relational Neural Networks.








{kind=link}