
After a decade of rapid growth in Artificial Intelligence (AI) model complexity and compute, 2023 marks a shift in focus to efficiency and the broad application of generative AI (GenAI). As a result, a new crop of models with less than 15 billion parameters, referred to as nimble AI, can closely match the capabilities of ChatGPT-style giant models containing more than 100B parameters, especially when targeted for particular domains. While GenAI is already being deployed throughout industries for a wide range of business usages, the use of compact, yet highly intelligent models, is rising. In the near future, I expect there will be a small number of giant modes and a giant number of small, more nimble AI models embedded in countless applications.
While there has been great progress with larger models, bigger is certainly not better when it comes to training and environmental costs. TrendForce estimates that ChatGPT training alone for GPT-4 reportedly costs more than $100 million, while nimble model pre-training costs are orders-of-magnitude lower (for example, quoted as approximately $200,000 for MosaicML’s MPT-7B). Most of the compute costs occur during continuous inference execution, but this follows a similar challenge for larger models including expensive compute. Furthermore, giant models hosted on third-party environments raise security and privacy challenges. Nimble models are substantially cheaper to run and provide a host of additional benefits such as adaptability, hardware flexibility, integrability within larger applications, security and privacy, explainability, and more (see Figure 1). The perception that smaller models don’t perform as well as larger models is also changing. Smaller, targeted models are not less intelligent – they can provide equivalent or superior performance for business, consumer, and scientific domains, increasing their value while decreasing time and cost investment.
A growing number of these nimble models roughly match the performance of ChatGPT-3.5-level giant models and continue to rapidly improve in performance and scope. And, when nimble models are equipped with on-the-fly retrieval of curated domain-specific private data and targeted retrieval of web content based on a query, they become more accurate and more cost-effective than giant models that memorize a wide-ranging data set.

As nimble open source GenAI models step forward to drive the fast progression of the field, this "iPhone moment," when a revolutionary technology becomes mainstream, is being challenged by an "Android revolution" as a strong community of researchers and developers build on each other’s open source efforts to create increasingly more capable nimble models.
Think, Do, Know: Nimble Models with Targeted Domains Can Perform Like Giant Models

To gain more understanding of when and how a smaller model can deliver highly competitive results for generative AI, it is important to observe that both nimble and giant GenAI models need three classes of competencies to perform:
- Cognitive abilities to think: Including language comprehension, summarization, reasoning, planning, learning from experience, long-form articulation and interactive dialog.
- Functional skills to do: For example – reading text in the wild, reading charts/graphs, visual recognition, programming (coding and debug), image generation and speech.
- Information (memorized or retrieved) to know: Web content, including social media, news, research, and other general content, and/or curated domain-specific content such as medical, financial and enterprise data.
Cognitive abilities to think. Based on its cognitive abilities, the model can "think" and understand, summarize, synthesize, reason, and compose language and other symbolic representations. Both nimble and giant models can perform well in these cognitive tasks and it is not clear that those core capabilities require massive model sizes. For example, nimble models like Microsoft Research’s Orca are showing understanding, logic, and reasoning skills that already match or surpass those of ChatGPT on multiple benchmarks. Furthermore, Orca also demonstrates that reasoning skills can be distilled from larger models used as teachers. However, the current benchmarks used to evaluate cognitive skills of models are still rudimentary. Further research and benchmarking are required to validate that nimble models can be pre-trained or fine-tuned to fully match the "thinking" strength of giant models.
Functional skills to do. Larger models are likely to have more functional skills and information given their general focus as all-in-one models. However, for most business usages, there is a particular range of functional skills needed for any application being deployed. A model used in a business application should have flexibility and headroom for growth and variation of use, but it rarely needs an unbounded set of functional skills. GPT-4 can generate text, code and images in multiple languages, but speaking hundreds of languages doesn’t necessarily mean that those giant models has inherently more underlying cognitive competencies – it primarily gives the model added functional skills to "do" more. Furthermore, functionally specialized engines will be linked to GenAI models and used when that functionality is needed – like adding mathematical "Wolfram superpowers" to ChatGPT modularly could provide best-in-class functionality without burdening the model with unnecessary scale. For example, GPT-4 is deploying plugins that are essentially utilizing smaller models for add-on functions. It’s also rumored that GPT-4 model itself is a collection of multiple giant (less than 100B parameters) "mixture of experts" models trained on different data and task distributions rather than one monolithic dense model like GPT-3.5. To get the best combination of capabilities and model efficiencies, it is likely that future multi-functional models might employ smaller, more focused mixture of experts models that are each smaller than 15B parameters.
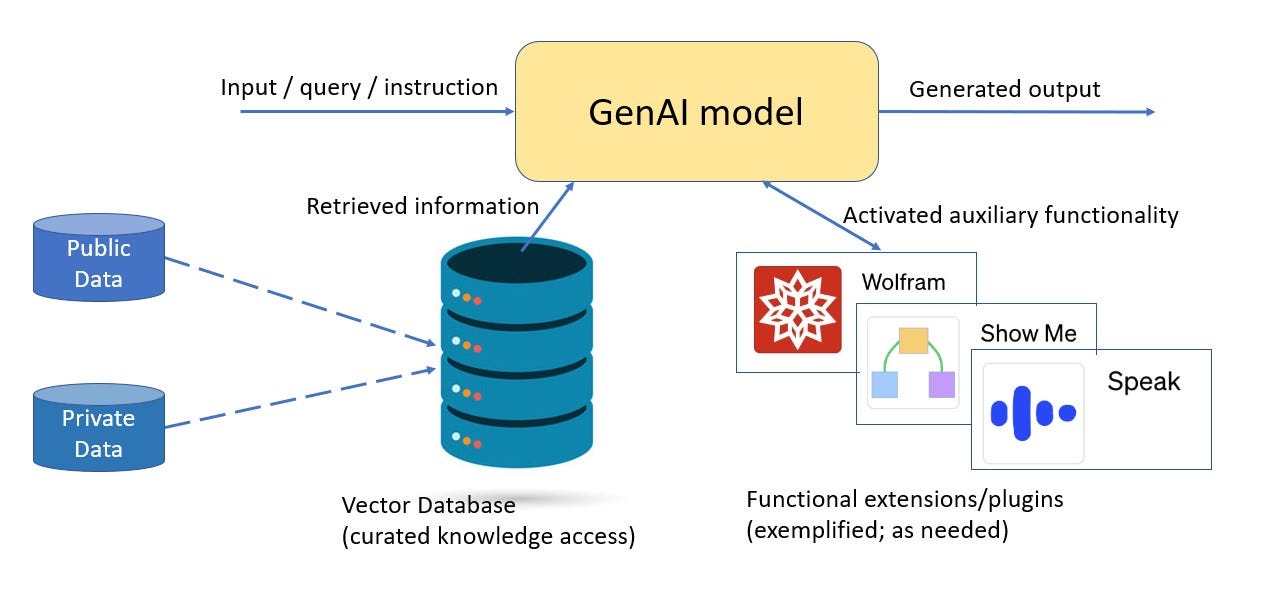
Information (memorized or retrieved) to know. Giant models "know" more by memorizing vast amounts of data within parametric memory, but it doesn’t necessarily make them smarter. They are just more generally knowledgeable than smaller models. Giant models have high value in zero-shot environments for new use cases, offering a general consumer base when there’s no need for targeting, and acting as a teacher model when distilling and fine-tuning nimble models like Orca. However, targeted nimble models can be trained and/or fine-tuned for particular domains, providing sharper skills for the capabilities needed.
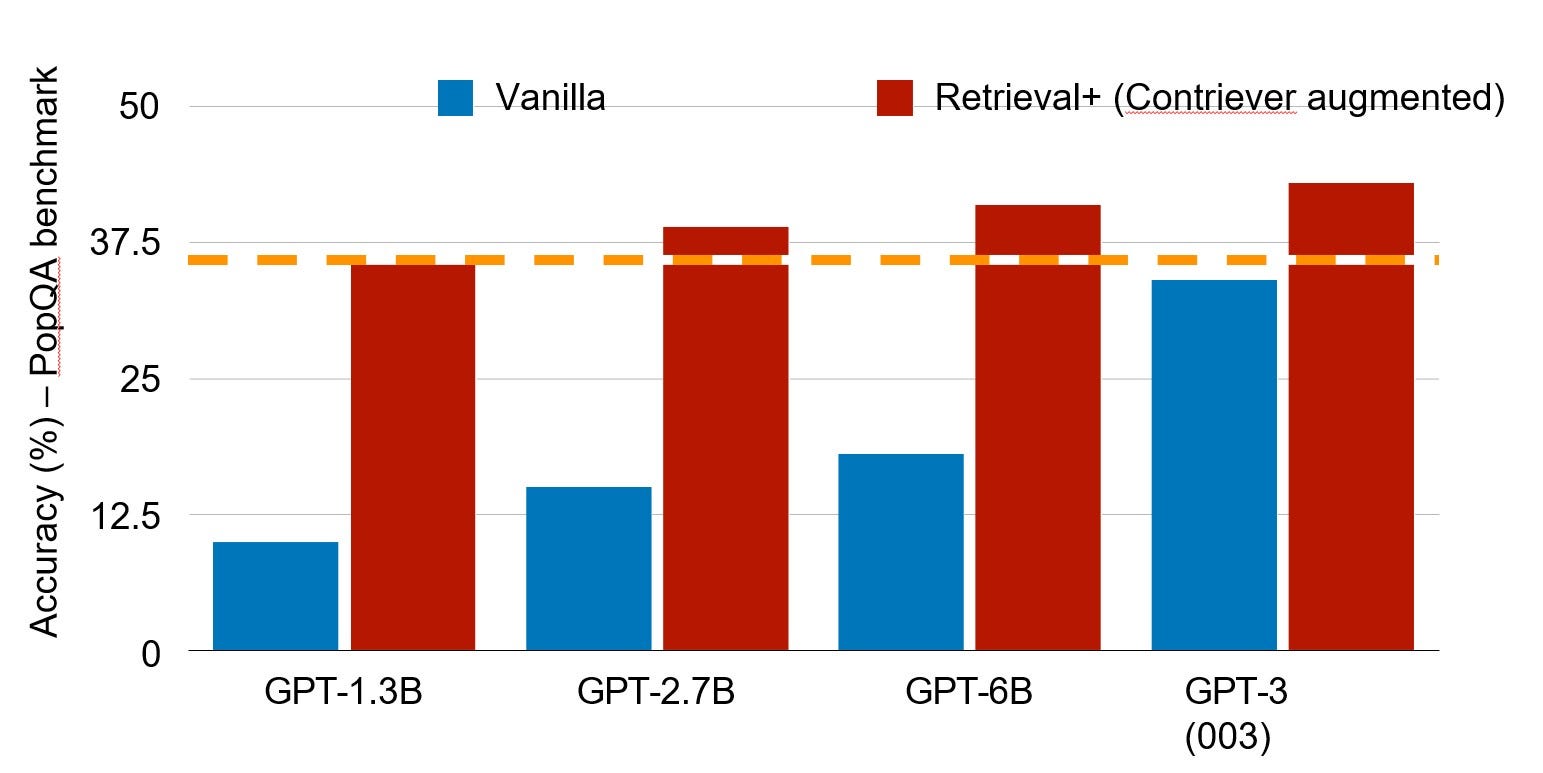
For example, a model that is targeted for programming can focus on a different set of capabilities than a healthcare AI system. Furthermore, by using retrieval over a curated set of internal and external data, the accuracy and timeliness of the model can be greatly improved. A recent study showed that on the PopQA benchmark, models as small as 1.3B parameters with retrieval can perform as well as a model more than hundred times their size at 175B parameters (see Figure 4). In that sense, the relevant knowledge of a targeted system with high-quality indexed accessible data may be much more extensive than an all-in-one general-purpose system. This may be more important for the majority of enterprise applications that require use-case or application-specific data – and in many instances, local knowledge instead of vast general knowledge. This is where the value of nimble models will be realized moving forward.
Three Aspects Contributing to the Explosive Growth in Nimble Models
There are three aspects to consider when assessing the benefits and value of nimble models:
- High efficiency at modest model sizes.
- Licensing as open source or proprietary.
- Model specialization as general purpose or targeted including retrieval.
In terms of size, nimble general-purpose models, such as Meta’s LLaMA-7B and -13B or Technology Innovation Institute’s Falcon 7B open source models, and proprietary models such as MosaicML’s MPT-7B, Microsoft Research’s Orca-13B and Saleforce AI Research’s XGen-7B are improving in rapid succession (see Figure 6). Having a choice of high-performance, smaller models has significant implications for the cost of operation as well as the choice of compute environments. ChatGPT’s 175B parameter model and the estimated 1.8 trillion parameters for GPT-4 require a massive installation of accelerators such as GPUs with enough compute power to handle the training and fine-tuning workload. In contrast, nimble models can generally run inference on any choice of hardware, anywhere from a single socket CPU, through entry-level GPUs, and up to the largest acceleration racks. The definition of nimble AI has been currently set to 15B parameters empirically based on the outstanding results of models sized at 13B parameters or smaller. Overall, nimble models offer a more cost-effective and scalable approach to handling new use cases (see the section on advantages and disadvantages of nimble models).
The second aspect of open source licensing allows universities and companies to iterate on one another’s models, driving a boom of creative innovations. Open source models allow for the incredible progress of small model capabilities as demonstrated in Figure 5.
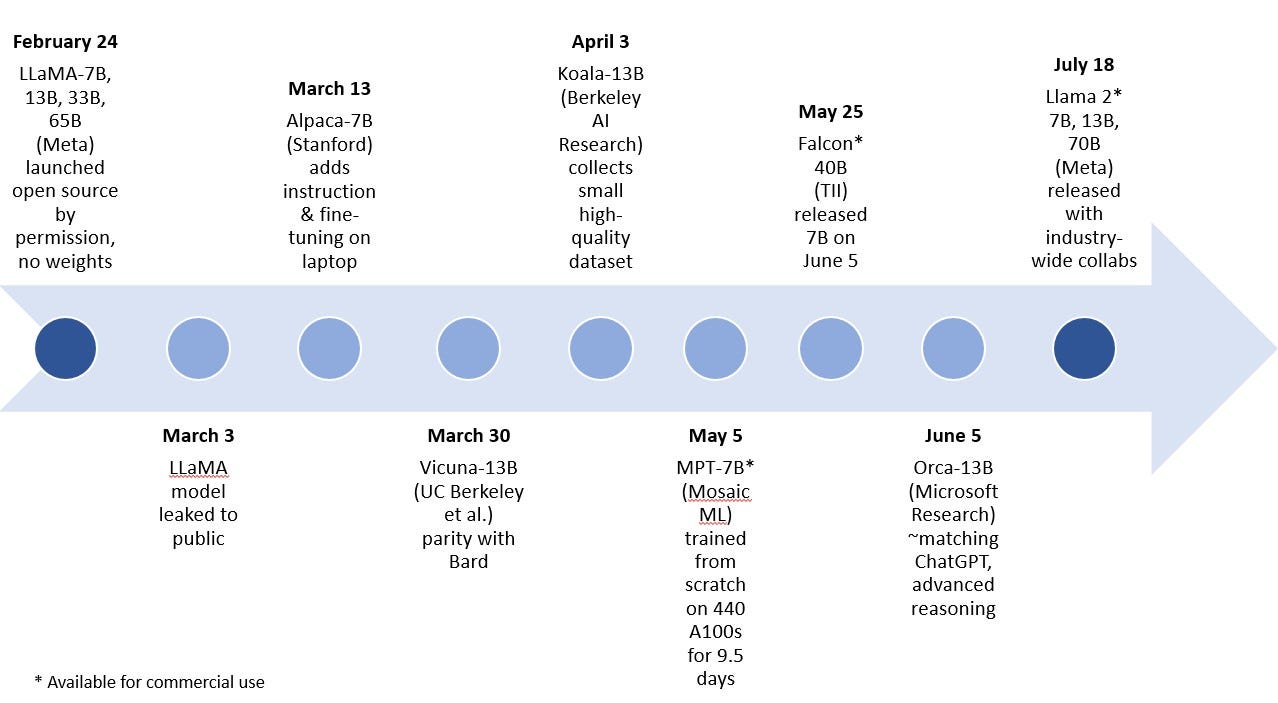
There are multiple examples from early 2023 of general nimble generative AI models starting with LLaMA from Meta, which has models with 7B, 13B, 33B, and 65B parameters. The following models in the 7B and 13B parameters range were created by fine-tuning LLaMA: Alpaca from Stanford University, Koala from Berkeley AI Research, and Vicuna created by researchers from UC Berkeley, Carnegie Mellon University, Stanford, UC San Diego, and MBZUAI. Recently, Microsoft Research published a paper on the not-yet-released Orca, a 13B parameter LLaMA-based model that imitates the reasoning process of giant models with impressive results prior to targeting or fine-tuning to a particular domain.
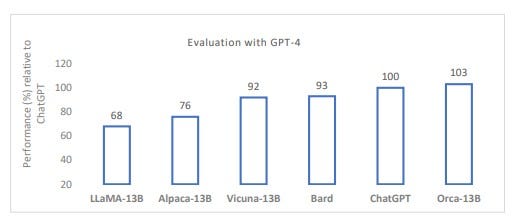
Vicuna could be a good proxy for recent open source nimble models that were derived from LLaMA as the base model. Vicuna-13B is a chatbot created by a university collaboration that has been "developed to address the lack of training and architecture details in existing models such as ChatGPT." After being fine-tuned on user-shared conversations from ShareGPT, the response quality of Vicuna is more than 90% compared to ChatGPT and Google Bard when using GPT-4 as a judge. However, these early open source models are not available for commercial use. MosaicML’s MPT-7B and Technology Innovation Institute’s Falcon 7B commercially usable, open source models are reportedly equal in quality to LLaMA-7B.
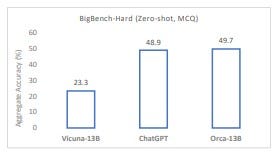
Orca "surpasses conventional instruction-tuned models such as Vicuna-13B by more than 100% in complex zero-shot reasoning benchmarks like Big-Bench Hard (BBH). It reaches parity with ChatGPT-3.5 on the BBH benchmark," according to researchers. Orca-13B’s top performance over other general models reinforces the notion that the large size of giant models may result from brute-force early models. The scale of giant foundation models can be important for some smaller models like Orca-13B to distill knowledge and methods, but size is not necessarily required for inference – even for the general case. A word of caution – a full evaluation of cognitive capabilities, functional skills, and knowledge memorization of the model will only be possible when it is broadly deployed and exercised.
As of the writing of this blog, Meta released their Llama 2 model with 7B, 13B and 70B parameters. Arriving just four months after the first generation, the model offers meaningful improvements. In the comparison chart, a nimble Llama 2 13B achieves similar results to larger models from the previous LLaMA generation as well as to MPT-30B and Falcon 40B. Llama 2 is open source and free for research and commercial use. It was introduced in tight partnership with Microsoft as well as quite a few other partners, including Intel. Meta’s commitment to open source models and its broad collaboration will surely give an additional boost to the rapid cross-industry/academia improvement cycles we are seeing for such models.
The third aspect of nimble models has to do with specialization. Many of the newly-introduced nimble models are general purpose – like LLaMA, Vicuna and Orca. General nimble models may rely solely on their parametric memory, using low-cost updates through fine-tune methods including LoRA: Low-Rank Adaptation of Large Language Models as well as retrieval-augmented generation, which pulls relevant knowledge from a curated corpora on-the-fly during inference time. Retrieval-augmented solutions are being established and continuously enhanced with GenAI frameworks like LangChain and Haystack. These frameworks allow easy and flexible integration of indexing and effectively accessing large corpora for semantics-based retrieval.
Most business users prefer targeted models that are tuned for their particular domain of interest. These targeted models also tend to be retrieval-based to utilize all key information assets. For example, healthcare users may want to automate patient communications.
Targeted models use two methods:
- Specialization of the model itself to the tasks and type of data required for the targeted use cases. This could be done in multiple ways, including pre-training a model on specific domain knowledge (like how phi-1 pre-trained on textbook-quality data from the web), fine-tuning a general purpose base model of the same size (like how Clinical Camel fine-tuned LLaMA-13B), or distilling and learning from a giant model into a student nimble model (like how Orca learned to imitate the reasoning process of GPT-4, including explanation traces, step-by-step thought processes, and other complex instructions).
- Curating and indexing relevant data for on-the-fly retrieval, which could be a large volume, but still within the scope/space of the targeted use case. Models can retrieve public web and private consumer or enterprise content that is continuously updated. Users determine which sources to index, allowing the choice of high-quality resources from the web plus more complete resources like an individual’s private data or a company’s enterprise data. While retrieval is now integrated into both giant and nimble systems, it plays a crucial role in smaller models as it provides all the necessary information for the model performance. It also allows for businesses to make all their private and local information available to a nimble model running within their compute environment.
Nimble Generative AI Model Advantages and Disadvantages
In the future, the size of compact models might drift up to 20B or 25B parameters, but still stay far below the 100B parameters scope. There is also a variety of models of intermediate sizes like MPT-30B, Falcon 40B and Llama 2 70B. While they are expected to perform better than smaller models on zero-shot, I would not expect them to perform materially better for any defined set of functionalities than nimble, targeted, retrieval-based models.
When compared with giant models, there are many advantages of nimble models, which are further enhanced when the model is targeted and retrieval-based. These benefits include:
- Sustainable and lower cost models: Models with substantially lower costs for training and inference compute. Inference run-time compute costs might be the determining factor for viability of business-oriented models integrated into 24×7 usages, and the much-decreased environmental impact is also significant when taken in aggregate across broad deployments. Finally, with their sustainable, specific, and functionally oriented systems, nimble models are not attempting to address ambitious goals of artificial general intelligence (AGI) and are therefore less involved in the public and regulatory debate related to the latter.
- Faster fine-tune iterations: Smaller models can be fine-tuned in a few hours (or less), adding new information or functionality to the model through adaptation methods like LoRA, which are highly effective in nimble models. This enables more frequent improvement cycles, keeping the model continuously up to date with its usage needs.
-
Retrieval-based model benefits: Retrieval systems refactor knowledge, referencing most of the information from the direct sources rather than the parametric memory of the model. This improves the following: – Explainability: Retrieval models use source attribution, providing provenance or the ability to track back to the source of information to provide credibility. – Timeliness: Once an up-to-date source is indexed, it is immediately available for use by the model without any need for training or fine-tuning. That allows for continuously adding or updating relevant information in near real-time. – Scope of data: The information indexed for per-need retrieval can be very broad and detailed. When focused on its target domains, the model can cover a huge scope and depth of private and public data. It may include more volume and details in its target space than a giant foundation model training dataset. – Accuracy: Direct access to data in its original form, detail, and context can reduce hallucinations and data approximations. It can provide reliable and complete answers as long as they are in the retrieval space. With smaller models, there is also less conflict between traceable curated information retrieved per-need, and memorized information (as in giant models) that might be dated, partial and not attributed to sources.
- Choice of hardware: Inference of nimble models can be done practically on any hardware, including ubiquitous solutions that might already be part of the compute setting. For example, Meta’s Llama 2 nimble models (7B and 13B parameters) are running well on Intel’s data center products including Xeon, Gaudi2 and Intel Data Center GPU Max Series.
- Integration, security and privacy: Today’s ChatGPT and other giant GenAI models are independent models that usually run on large accelerator installations on a third-party platform and are accessed through interfaces. Nimble AI models can run as an engine that is embedded within a larger business application and can be fully integrated into the local compute environment. This has major implications for security and privacy because there is no need for exchange/exposure of information with third-party models and compute environments, and all security mechanisms of the broader application can be applied to the GenAI engine.
- Optimization and model reduction: Optimization and model reduction techniques such as quantization, which reduces computational demands by converting input values to smaller output values, have shown strong initial results on nimble models with increasing power efficiency.
Some challenges of nimble models are still worth mentioning:
- Reduced range of tasks: General-purpose giant models have outstanding versatility and especially excel in zero-shot new usages that were not considered earlier. The breadth and scope that can be achieved with nimble systems is still under evaluation but seems to be improving with recent models. Targeted models assume that the range of tasks is known and defined during pre-training and/or fine-tuning, so the reduction in scope should not impact any relevant capabilities. Targeted models are not single task, but rather a family of related capabilities. This can lead to fragmentation as a result of task- or business-specific nimble models.
- May be improved with few-shot fine-tuning: For a model to address a targeted space effectively, fine-tuning is not always required, but can aid the effectiveness of AI by adjusting the model to the tasks and information needed for the application. Modern techniques enable this process to be done with a small number of examples and without the need for deep data science expertise.
- Retrieval models need indexing of all source data: Models pull in needed information during inference through index mapping, but there is risk of missing an information source, making it unavailable to the model. To ensure provenance, explainability and other properties, targeted retrieval-based models should not rely on detailed information stored in the parametric memory, and instead rely mainly on indexed information that is available for extraction when needed.
Summary
The major leap in generative AI is enabling new capabilities such as AI agents conversing in plain language, the summarization and generation of compelling text, image creation, utilization of the context of previous iterations and much more. This blog introduces the term "nimble AI" and makes the case for why it will be the predominant method in deploying GenAI at scale. Simply put, nimble AI models are faster to run, quicker to refresh through continuous fine-tuning, and more amenable to rapid technology improvement cycles through the collective innovation of the open source community.
As demonstrated through multiple examples, the outstanding performance that emerged through the evolution of the largest models shows that nimble models do not require the same massive heft as the giant models. Once the underlying cognitive abilities have been mastered, the required functionality tuned and the data made available per-need, nimble models provide the highest value for the business world.
That said, nimble models will not render giant models extinct. Giant models are still expected to perform better in a zero-shot, out-of-the-box setting. These large models also might be used as the source (teacher model) for distillation into smaller, nimble models. While giant models have a huge volume of additional memorized information to address any potential use, and are equipped with multiple skills, this generality is not expected to be required for most GenAI applications. Instead, the ability to fine-tune a model to the information and skills relevant for the domain, plus the ability to retrieve recent information from curated local and global sources, would be a much better value proposition for many applications.
Viewing nimble, targeted AI models as modules that can be incorporated into any existing application offers a very compelling value proposition including:
- Requires a fraction of the cost for deployment and operation.
- Adaptable to tasks and private/enterprise data.
- Updatable overnight, and can run on any hardware from CPU, to GPU or accelerators.
- Integrated into current compute environment and application.
- Runs on premise or in a private cloud.
- Benefits from all security and privacy settings.
- Higher accuracy and explainability.
- More environmentally responsible while providing a similar level of generative AI capabilities.
Impressive progress on a small number of giant models will continue. However, the industry will most likely need just a few dozen or so general-purpose nimble base models, which can then be used to build countless targeted versions. I foresee a near-term future in which a broad scaling of advanced GenAI will permeate all industries, mostly by integrating nimble, targeted secure intelligence modules as their engines of growth.
References
- Tseng, P. K. (2023, March 1). TrendForce Says with Cloud Companies Initiating AI Arms Race, GPU Demand from ChatGPT Could Reach 30,000 Chips as It Readies for Commercialization. TrendForce. https://www.trendforce.com/presscenter/news/20230301-11584.html
- Introducing MPT-7B: A New Standard for Open Source, Commercially Usable LLMs. (2023, May 5). https://www.mosaicml.com/blog/mpt-7b
- Mukherjee, S., Mitra, A., Jawahar, G., Agarwal, S., Palangi, H., &and Awadallah, A. (2023). Orca: Progressive Learning from Complex Explanation Traces of GPT-4. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2306.02707
- Wolfram, S. (2023, March 23). ChatGPT Gets Its "Wolfram Superpowers"!. Stephen Wolfram Writings. https://writings.stephenwolfram.com/2023/03/chatgpt-gets-its-wolfram-superpowers/
- Schreiner, M. (2023, July 11). GPT-4 architecture, datasets, costs and more leaked. THE DECODER. https://the-decoder.com/gpt-4-architecture-datasets-costs-and-more-leaked/
- ChatGPT plugins. (n.d.). https://openai.com/blog/chatgpt-plugins
- Izacard, G., Caron, M., Hosseini, L., Riedel, S., Bojanowski, P., Joulin, A., & Grave, E. (2021). Unsupervised Dense Information Retrieval with Contrastive Learning. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2112.09118
- Mallen, A., Asai, A., Zhong, V., Das, R., Hajishirzi, H., and Khashabi, D. (2022). When not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2212.10511
- Papers with Code – PopQA Dataset. (n.d.). https://paperswithcode.com/dataset/popqa
- Introducing LLaMA: A foundational, 65-billion-parameter large language model. (2023, February 24). https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
- Introducing Falcon LLM. (n.d.). https://falconllm.tii.ae/
- Nijkamp, E., Hayashi, H., Xie, T., Xia, C., Pang, B., Meng, R., Kryscinski, W., Tu, L., Bhat, M., Yavuz, S., Xing, C., Vig, J., Murakhovs’ka, L., Wu, C. S., Zhou, Y., Joty, S. R., Xiong, C., and Savarese, S. (2023). Long Sequence Modeling with XGen: A 7B LLM Trained on 8K Input Sequence Length. Salesforce AI Research. https://blog.salesforceairesearch.com/xgen/
- Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. (2021, June 17). LoRA: Low-Rank Adaptation of Large Language Models. arXiv (Cornell University). https://doi.org/10.48550/arXiv.2106.09685
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S., and Kiela, D. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. NeurIPS 2020. https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html
- Introduction LangChain. (n.d.). https://python.langchain.com/docs/get_started/introduction.html
- Haystack. (n.d.). https://www.haystackteam.com/core/knowledge
- Mantium. (2023). How Haystack and LangChain are Empowering Large Language Models. Mantium. https://mantiumai.com/blog/how-haystack-and-langchain-are-empowering-large-language-models/
- Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. (2023, March 13). Alpaca: A Strong, Replicable Instruction-Following Model. Stanford University CRFM. https://crfm.stanford.edu/2023/03/13/alpaca.html
- Geng, X., Gudibande, A., Liu, H., Wallace, E., Abbeel, P., Levine, S. and Song, D. (2023, April 3). Koala: A Dialogue Model for Academic Research. Berkeley Artificial Intelligence Research Blog. https://bair.berkeley.edu/blog/2023/04/03/koala/
- Chiang, W. L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J. E., Stoica, I., and Xing, E. P. (2023, March 30). Vicuna: An Open Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality. LMSYS Org. https://lmsys.org/blog/2023-03-30-vicuna/
- Rodriguez, J. (2023, April 5). Meet Vicuna: The Latest Meta’s Llama Model that Matches ChatGPT Performance. Medium. https://pub.towardsai.net/meet-vicuna-the-latest-metas-llama-model-that-matches-chatgpt-performance-e23b2fc67e6b
- Papers with Code – BIG-bench Dataset. (n.d.). https://paperswithcode.com/dataset/big-bench
- Meta. (2023, July 18). Meta and Microsoft introduce the next generation of Llama. Meta. https://about.fb.com/news/2023/07/llama-2/
- Meta AI. (n.d.). Introducing Llama 2. https://ai.meta.com/llama/
- Gunasekar, S., Zhang, Y., Aneja, J., Mendes, C. C. T., Allie, D. G., Gopi, S., Javaheripi, M., Kauffmann, P., Gustavo, D. R., Saarikivi, O., Salim, A., Shah, S., Behl, H. S., Wang, X., Bubeck, S., Eldan, R., Kalai, A. T., Lee, Y. T., and Li, Y. (2023). Textbooks Are All You Need. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2306.11644
- Toma, A., Lawler, P. R., Ba, J., Krishnan, R. G., Rubin, B. B., and Wang, B. (2023). Clinical Camel: An Open-Source Expert-Level Medical Language Model with Dialogue-Based Knowledge Encoding. arXiv (Cornell University). https://doi.org/10.48550/arxiv.2305.12031
- Patel, D., and Ahmad, A. (2023, May 4). Google "We Have No Moat, And Neither Does OpenAI." SemiAnalysis. https://www.semianalysis.com/p/google-we-have-no-moat-and-neither
- Accelerate Llama 2 with Intel AI Hardware and Software Optimizations. (n.d.). Intel. https://www.intel.com/content/www/us/en/developer/articles/news/llama2.html
- Smaller is better: Q8-Chat, an efficient generative AI experience on Xeon. (n.d.). Hugging Face. https://huggingface.co/blog/generative-ai-models-on-intel-cpu







