
A common challenge for every data science or product team is to align the new (product development) with the old (operational, support) tasks. When the full team is supposed to handle both, it means that on one side the team is required to keep a product deadline and launch a new product feature while, at the same time, the team is expected to work operationally and fix existing products and support commercial questions and calls. This situation causes unexpected context switches and, eventually, leads to less efficiency, failing deadlines, and stress.
In practice, this often leads to a situation where certain team members take on those additional tasks or are specialized to do so. But that is dangerous because as soon as one of these specialized team members goes on vacation, the whole company might feel that and has a problem.
Hence, an efficient and scalable data team needs to support both operational and new development work and create a system that includes:
- Good knowledge sharing among team members on how to do operational work and support products/customers
- Uninterrupted development work without much context switching
- Well-defined and estimated maintenance work to keep avoid unexpected deadlines
The Rotating On-Call System
One system that turned out to work very well for us in the past is a rotating on-call system that does handle more than "just" alerts in production. Simply put, this is a rotating system where one (or more) team members are the designated survivors for a specific amount of time and are purely responsible for operational work.
The person on call is not just doing a job, the person is protecting the entire team from all the chaos happening outside of the development work
To finish that point, this system allows for that only the on-call person (the designated survivor) is handling all the work that does not fall under "new development". During that time, the person on-call is not just doing a job, the person is protecting the entire team from all the chaos happening outside of the development work, including:
- Fix production pipeline issues
- Answer commercial / customer questions
- Support customer calls
- Reduce tech dept (backlog)
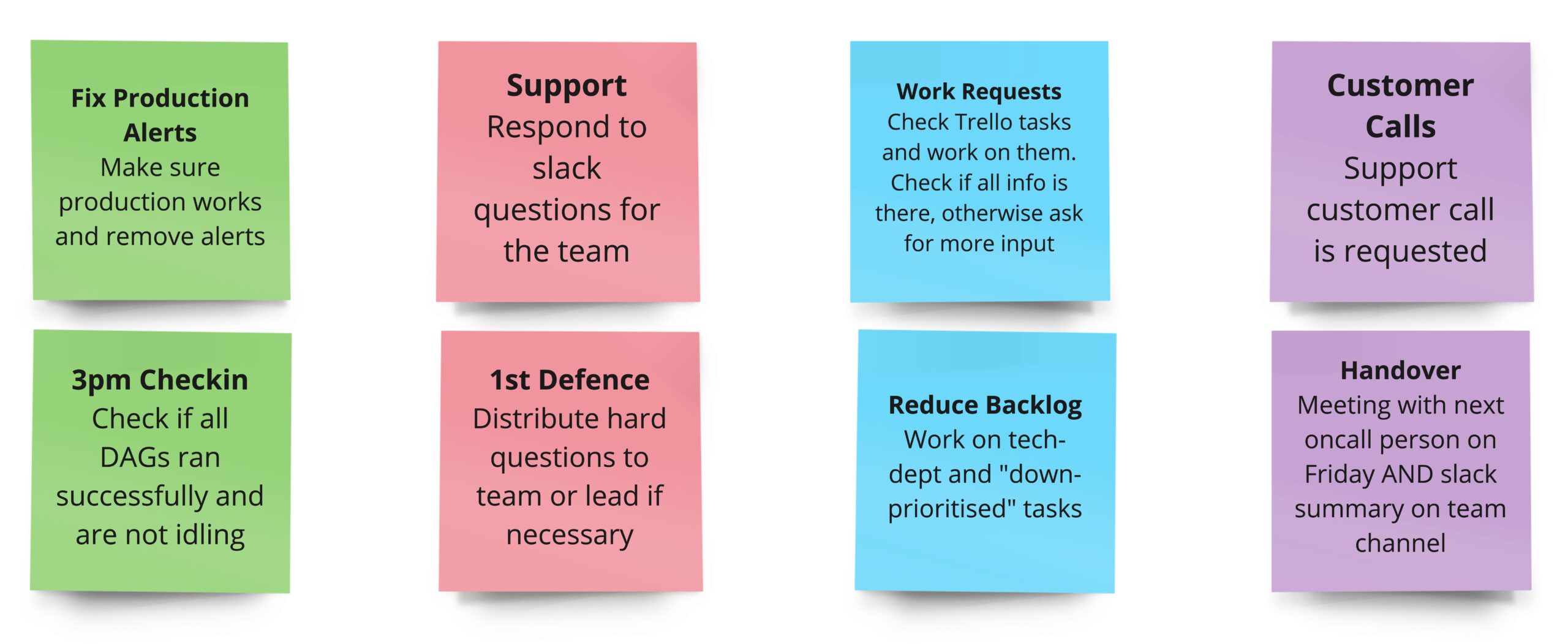
As can be seen in the figure above, handling the "classic" on-call system and making sure the production environment works is still the most important. However, if there are no issues in production, this frees up for other tasks like supporting commercial requests, customer calls, or reducing the backlog.
What are the benefits?
Switching to the system at first might not be easy. Not every team member can just take responsibility for the production pipeline, commercial support, and the tech dept. But that should not be a blocker. It is important to communicate properly that the person on-call owns those items and is the first line of defense but can ask for help at any time.
In the long run, this will bring a lot of benefits to the team and the entire organization. The most intuitive benefits are that it is way easier to estimate development work and that the team will become more efficient (less context switch). This also goes for the operational side where the number of people being part of the on-call system defines how much operational work is possible. This makes communication with the company and stakeholders way easier because a team of 5 people with 1 person in the rotation means 1 out of 5 FTEs is maintaining all systems and work related to existing products (20% operational, 80% development). That is easy to account for and to estimate.
However, there are more benefits coming in over time, almost as side effects. All team members will become full-stack data scientists. The reason is that every team member needs to understand a certain minimum of the products, customers, systems, models/logic, and code infrastructure involved. They do not need to be experts but they will eventually become good enough to handle those alone for at least 1 week. This will also ensure that it is not at all an issue when a valuable team member goes on vacation since the person on-call will always have the team’s back.
In addition, even though this on-call time might sometimes be a bit more stressful, it gives the data scientist the opportunity to see what is outside of the team and to collaborate with the commercial side and customers. This can be a very valuable and rewarding experience.
How to set up such a system?
This is where it gets a little bit technical (for the people who like code, just scroll down to the very end). Setting up such a system is fairly straightforward but might involve some coding. The most important part is communication with the team and stakeholders and informing them how this is going to work.
Since the whole point of the system is to support the team, and not to create more overhead, I highly recommend fully automatizing it. To do so, you would need to have at least 3 systems in place:
- A pager system connected to production that alerts when production fails (e.g., Opsgenie or Pagerduty)
- A scheduling system that detects who is on call and can communicate that to another system (e.g., Apache Airflow or Keboola)
- A communication platform that is used to reach out to your team and to make tickets (e.g., Slack or Teams)
If you have those systems in place and you have API access to the pager system and to the communication platform, then you are almost done. The only thing left to do is to set up a job in the scheduling system that runs an API call first to get who is on call from the pager system and an API push afterward to communicate or overwrite channels/groups/tags in the communication platform.
Below is an example of how such a simple API call can look like that will provide you with the person on call from Opsgenie:
curl -X GET
'https://api.opsgenie.com/v2/schedules/{schedule_name}/on-calls?scheduleIdentifierType=name&flat=true'
--header 'Authorization: GenieKey {token}'After that, you want to run a command that does something in your communication system. For instance, in Slack, overwrite a user group so that it contains only the user who is on call:
curl -X POST
-F usergroup={usergroup}
-F users={user}
'https://slack.com/api/usergroups.users.update'
-H 'Authorization: Bearer {token}'At the end of this story, you will find a complete code version of how this code can be automatically scheduled. This will ensure that every time when someone tags your group on Slack (like @ team), only the person on-call will be tagged and can decide if more team members need to be notified. It also allows you to quickly add new tasks to the dag. For instance, when you want to notify the company or the team who is going on call now or if you want to adjust your ticketing system accordingly.
Summary
Having a rotating schedule for the team’s operational, commercial, and tech dept work is making your data team more efficient. It will reduce context switch and allows for better time estimations. In addition, it will educate full-stack data scientists that are confident in handling a wide range of issues to protect the rest of the team.
All images, unless otherwise noted, are by the author.
Code Appendix:
Example of an Airflow dag that fetches the person who is on call from Opsgenie and overwrites a user group in Slack to only contain that person. The coding is certainly not perfect (Data Scientist at work) but I am sure you get it:
# Import
from airflow import DAG, XComArg
from typing import Dict, List
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
from airflow.models import Variable
import json
# Fetch secret tokens
slack_token = Variable.get("slack_token")
opsgenie_token = Variable.get("opsgenie_token")
# Setup DAG
dag = DAG(
dag_id,
schedule_interval=schedule_interval,
default_args=default_args,
catchup=catchup,
max_active_runs=max_active_runs,
)
with dag:
# Run BashOperator fetching from Opsgenie who is on call
def fetch_who_is_on_call(**kwargs):
fetch_who_is_on_call_bash = BashOperator(
task_id="fetch_who_is_on_call_bash",
bash_command="""
curl -X GET
'https://api.opsgenie.com/v2/schedules/{schedule_name}/on-calls?scheduleIdentifierType=name&flat=true'
--header 'Authorization: GenieKey {token}'
""".format(
schedule_name="schedule_name",
token=opsgenie_token
),
dag=dag,
)
return_value = fetch_who_is_on_call_bash.execute(context=kwargs)
fetch_who_is_on_call_bash
return return_value
# run BashOperator in PythonOperator and provide context
opsgenie_pull = PythonOperator(
task_id="opsgenie_pull",
python_callable=fetch_who_is_on_call,
provide_context=True,
dag=dag,
)
# Overwrite slack group with the person on call
def overwrite_slack_group(**kwargs):
# First: get who is on call from PythonOperator
ti = kwargs.get("ti")
xcom_return = json.loads(ti.xcom_pull(task_ids="opsgenie_pull"))
user_email = xcom_return["data"]["onCallRecipients"][0]
user_dict = {
"data_scientist_a": "A03BU00KGK4",
"data_scientist_b": "B03BU00KGK4",
}
user_id = [
user_dict[k] for k in user_dict.keys() if k == user_email.split(".")[0]
]
# Second: Run BashOperator to overwrite slack group
overwrite_slack_group_bash = BashOperator(
task_id="overwrite_slack_group_bash",
bash_command="""
curl -X POST
-F usergroup={usergroup}
-F users={user}
https://slack.com/api/usergroups.users.update
-H 'Authorization: Bearer {token}'
""".format(
usergroup="usergroup_id",
user=user_id,
token=slack_token,
),
dag=dag,
)
overwrite_slack_group_bash.execute(context=kwargs)
overwrite_slack_group_bash
# Run BashOperator for slack overwrite in PythonOperator
overwrite_slack = PythonOperator(
task_id="overwrite_slack",
python_callable=overwrite_slack_group,
provide_context=True,
dag=dag,
)
opsgenie_pull >> overwrite_slack
return dag





