Getting Started
Existing (deep or shallow) Anomaly Detection methods are typically designed as unsupervised learning (trained on fully unlabeled data) or semi-supervised learning (trained on exclusively labeled normal data) due to the lack of large-scale labeled anomaly data. As a result, they are difficult to leverage prior knowledge (e.g., a few labeled anomalies) when such information is available as in many real-world anomaly detection applications. These limited labeled anomalies may originate from a deployed detection system, e.g., a few successfully detected network intrusion records, or they may be from users, such as a small number of fraudulent credit card transactions that are reported by clients and confirmed by the banks. As it is assumed only a very small number of labeled anomalies are available during training, the approaches in this research line may be grouped under the umbrella ‘few-shot anomaly detection’. However, they also have some fundamental differences from the general few-shot learning. I will discuss more on the differences at the end. In this post, I will share some of our exciting work on leveraging deep learning techniques to address this problem.
The Research Problem
Given a set of large normal (or unlabeled) training data and a very limited number of labeled anomaly data, we aim to properly leverage those small labeled anomaly data and the large normal/unlabeled data to learn an anomaly detection model.
Deep Distance-based Anomaly Detection Approach
REPEN [1] is probably the first deep anomaly detection method that is designed to leverage the few labeled anomalies to learn anomaly-informed detection models. The key idea in REPEN is to learn feature representations such that anomalies have a larger nearest neighbor distance in a random data subsample than normal data instances. This random nearest neighbor distance is one of the most effective and efficient anomaly measures, as shown in [2, 3]. REPEN aims to learn feature representations that are tailored to this state-of-the-art anomaly measure. The framework of REPEN is illustrated as follows.
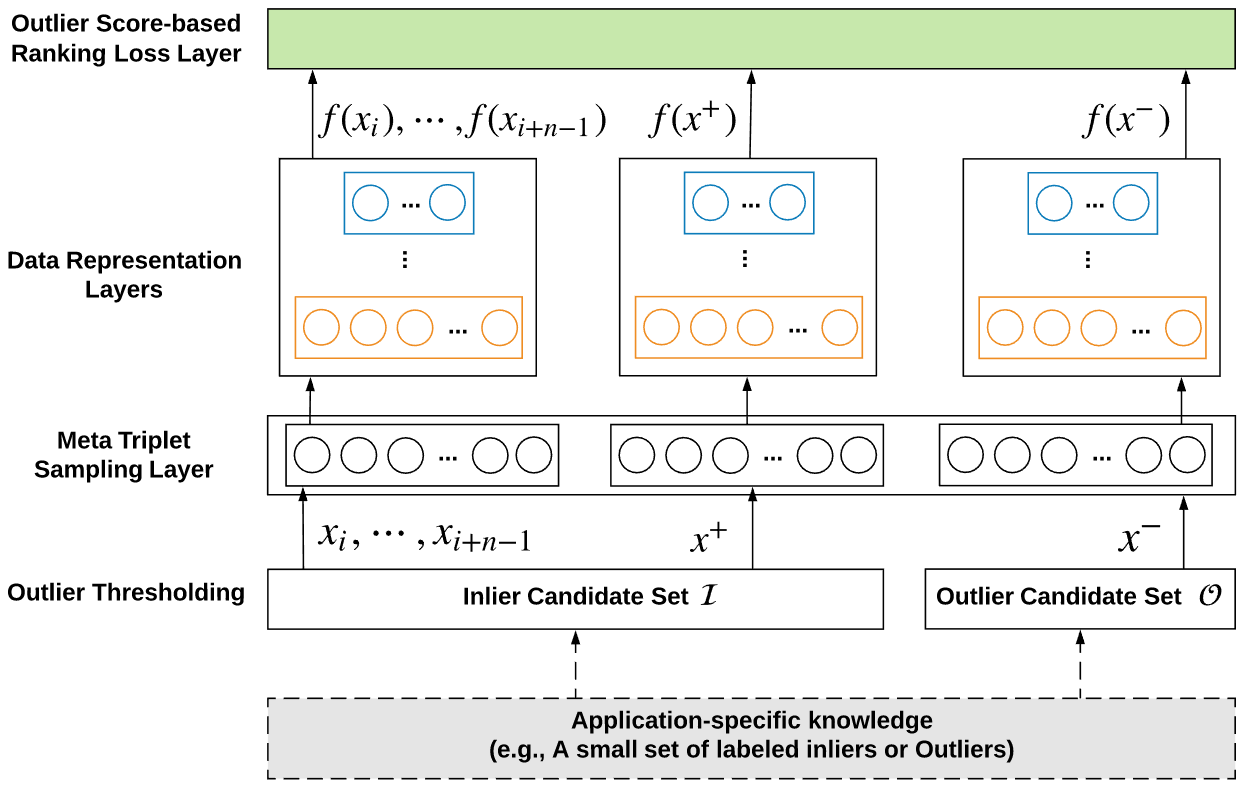
REPEN is enforced to learn a larger nearest neighbor distance of the anomaly x- than the normal instance x+ in a random data subset xi, …, x{i+n-1}. The overall objective is given as

where Q is the random data subset sampled from the unlabeled/normal training data, f is a neural network-enabled feature learning function, nn_dist returns the nearest neighbor distance of x in the data subset Q.
As you can see above, REPEN can work when the large training data contains either only normal data or fully unlabeled data. In the latter case and we also do not have the labeled anomaly data, REPEN uses some existing anomaly detectors to produce some pseudo-labeled anomaly data. So, REPEN can also work in an fully unsupervised setting.
Although the labeled anomaly data is limited, REPEN can achieve very remarkable accuracy performance when compared with its unsupervised version. Some of the impressive results can be found below. The AUC performance increases quickly as the number of labeled anomalies increases from 1 to 80.

The source code of REPEN is released at
Deep Deviation Network: An End-to-end Anomaly Detection Optimization Approach
Unlike REPEN that focuses on feature representation learning for the distance-based anomaly measure, deviation network – DevNet [4] – is designed to leverage the limited labeled anomaly data to perform end-to-end anomaly score learning. The key difference can be seen in the figure below, where the former optimizes the representations while the latter optimizes the anomaly scores.
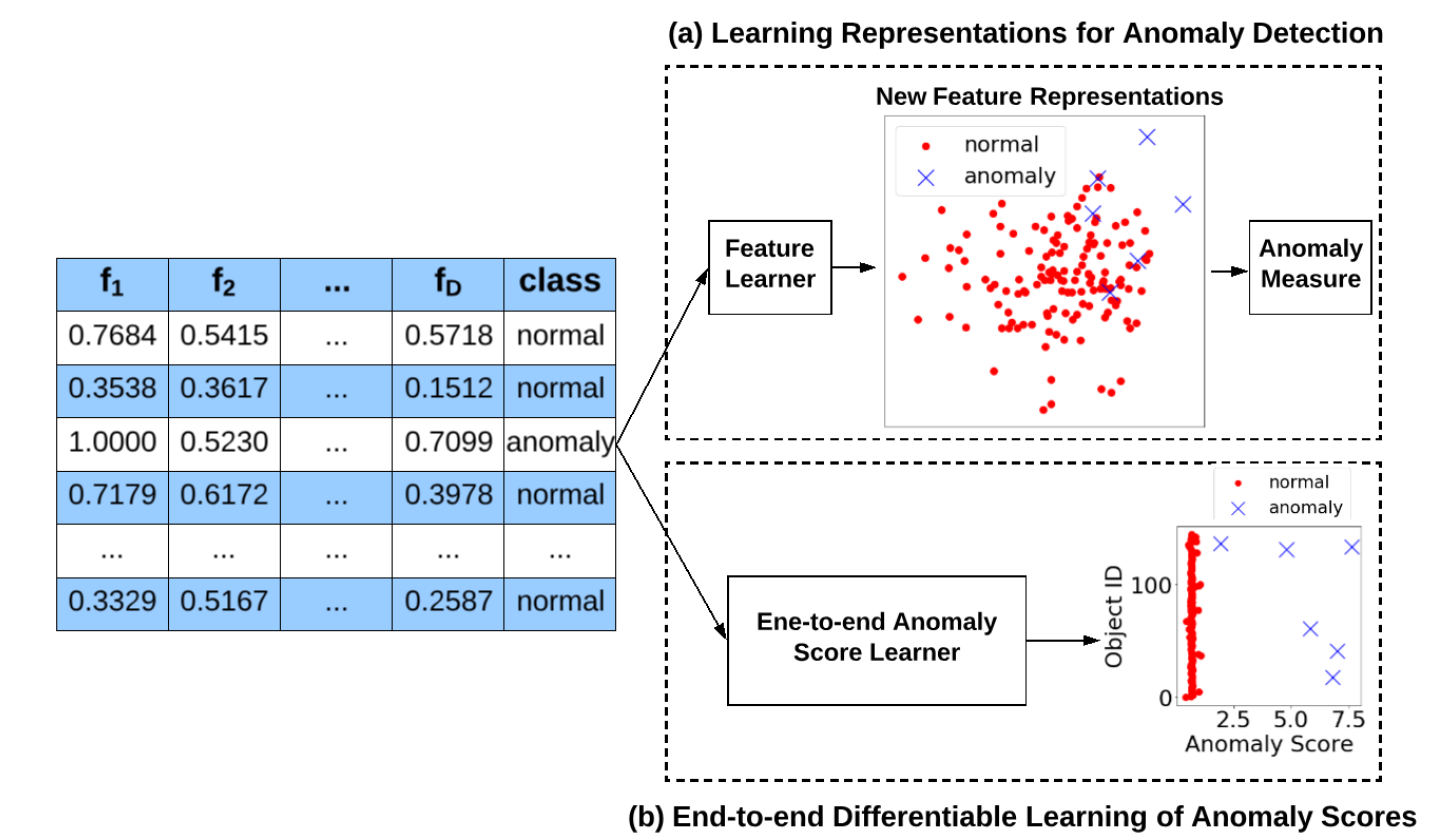
Specifically, as shown in the framework below, given a set of training data instances, the proposed framework first uses a neural anomaly score learner to assign it an anomaly score, and then defines the mean of the anomaly scores of some normal data instances based on a prior probability to serve as a reference score for guiding the subsequent anomaly score learning. Lastly, the framework defines a loss function, called deviation loss, to enforce statistically significant deviations of the anomaly scores of anomalies from that of normal data objects in the upper tail. In the implementation of DevNet, a Gaussian prior is used to perform a direct optimization of anomaly scores using a Z-Score-based deviation loss.

The loss function of DevNet is given as follows

where dev is a Z-score-based deviation function and defined as

where phi is a neural network-based mapping function that projects input x to a scalar output, mu and sigma are drawn from a Gaussian prior. This loss enables DevNet to push the anomaly scores of normal instances as close as possible to mu while enforce a deviation of at least a between mu and the anomaly scores of anomalies.
DevNet is evaluated on a wide range of real-world datasets. Some of the results are given as follows. DevNet shows significantly improved performance over several state-of-the-art competing methods, including REPEN, deep one-class classifier, few-shot classifier and the unsupervised method iForest. More interesting results can be found in [4].

The source code of DevNet and the datasets are released at
Few-shot Anomaly Detection vs. Few-shot Classification
In few-shot anomaly detection, the limited anomaly examples may come from different anomaly classes, and thus, exhibit completely different manifold/class features. This is fundamentally different from the general few-shot learning (mostly classification tasks), in which the limited examples are class-specific and assumed to share the same manifold/class structure. So, in few-shot anomaly detection, caution must be taken to deal with unknown anomalies that are from some novel type of anomaly classes. Two pieces of work [5, 6] are designed to address this problem. I will discuss these two studies later.
In addition to the two methods introduced above, there are a few other papers addressing the same problem. Please see the survey paper [7] for detail.
References
[1] Pang, G., Cao, L., Chen, L., & Liu, H. (2018, July). Learning representations of ultrahigh-dimensional data for random distance-based outlier detection. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 2041–2050). [2] Pang, G., Ting, K. M., & Albrecht, D. (2015, November). LeSiNN: Detecting anomalies by identifying least similar nearest neighbours. In 2015 IEEE international conference on data mining workshop (ICDMW) (pp. 623–630). IEEE. [3] Sugiyama, M., & Borgwardt, K. (2013). Rapid distance-based outlier detection via sampling. In Advances in Neural Information Processing Systems (pp. 467–475). [4] Pang, G., Shen, C., & van den Hengel, A. (2019, July). Deep anomaly detection with deviation networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 353–362). [5] Pang, G., Shen, C., Jin, H., & Hengel, A. V. D. (2019). Deep Weakly-supervised Anomaly Detection. arXiv preprint:1910.13601. [6] Pang, G., Hengel, A. V. D., Shen, C., & Cao, L. (2020). Deep Reinforcement Learning for Unknown Anomaly Detection. arXiv preprint:2009.06847. [7] Pang, G., Shen, C., Cao, L., & Hengel, A. V. D. (2020). Deep learning for anomaly detection: A review. arXiv preprint:2007.02500.







