
In today’s dynamic and competitive landscape, modern organisations heavily invest in their data assets. This investment ensures that teams across the entire organisational spectrum – ranging from leadership, product, engineering, finance, marketing, to human resources – can make informed decisions.
Consequently, data teams have a pivotal role in enabling organisations to rely on data-driven decision-making processes. However, merely having a robust and scalable data platform isn’t enough; it’s essential to extract valuable insights from the stored data. This is where data modeling comes into play.
At its essence, data modeling defines how data is stored, organised, and accessed to facilitate the extraction of insights and analytics. The primary objective of data modeling is to ensure that data needs and requirements are met to support the business and product effectively.
Data teams strive to offer organisations the ability to unlock the full potential of their data but usually encounter a big challenge that relates to how the data is structured such that meaningful analyses can be performed by the relevant teams. This is why modeling dimensions is one of the most important aspects when designing data warehouses.
Dimensions and Data Modeling
As organisations evolve and adapt to changing needs, the simplicity of early data models often gives way to complexity. Without proper modeling, this complexity can quickly spiral out of control, leading to inefficiencies and challenges in managing and deriving value from the data.
Dimensions are crucial components of data modeling as they offer a structured framework that allows data teams to organise their data. Essentially, dimensions represent the different perspectives from which data can be analysed and understood.
Put simply, dimensions provide a lens through which data can be interpreted, facilitating decision-making processes. Whether analysing sales trends, user engagement patterns, customer segmentation, or product performance, dimensions play a pivotal role in measuring and understanding various aspects of the data.
To illustrate, let’s consider a business that offers multiple products across different countries or markets. The following diagram depicts a cube representing the model, consisting of three dimensions: product, market, and time. By incorporating these dimensions, the business can extract different measures to inform decision-making processes.

In essence, dimensions assist organisations in several key ways:
- Organising Data: Dimensions streamline data organisation and make data navigation more intuitive. By categorising data into distinct perspectives, dimensions facilitate easier access and retrieval of relevant information
- Establishing Clear Relationships: Dimensions define clear relationships with fact tables, which typically store measures, transactions, or events. These relationships enable seamless integration of context with quantitative data, ensuring a comprehensive understanding of the underlying information
- Enhancing Analytical Capabilities: Dimensions enhance analytical capabilities by enabling data users to extract insights and build meaningful reports or dashboards. By slicing, dicing, and drilling down data along different dimensions, organisations can gain deeper insights into various aspects of their operations
- Improving System Performance: Dimensions play a crucial role in improving the performance of data systems. By structuring data efficiently and optimising queries, dimensions facilitate the extraction of valuable insights in a cost-efficient and timely manner, ultimately enhancing decision-making processes
Dimensions are indeed a critical aspect of data modeling, with the potential to significantly impact the effectiveness of your data products. However, they pose a unique challenge due to the dynamic nature of data. Data is not static; it continuously changes over time. Therefore, it becomes increasingly important to implement techniques that ensure changes are accurately captured and seamlessly integrated into the data models.
Understanding Slowly Changing Dimensions
Slowly Changing Dimensions (SCDs) represent a foundational concept in the context of Data Warehouse design, having a direct influence on the operational capacity of data analytics teams.
SCDs is a concept used to address how to capture and store data changes of dimensions over time. Put simply, Slowly Changing Dimensions offer a framework that enables data teams track data historicity within the data warehouse.
Failing to model SCDs in a way that is both proper and aligned with the needs of the business and product can have profound consequences. It may lead to an inability to accurately capture historical data, jeopardising the organisation’s capacity to report essential metrics. This poses a substantial risk, as it undermines the reliability and completeness of the analytical insights derived from the data.
In more technical terms, SCDs have the same natural key and an additional set of data attributes that may (or may not) change over time. The way teams handle these records could determine whether historicity is tracked and subsequently, whether the business metrics of interest can be extracted.
Furthermore, the implementation of SCDs within a data warehouse could also significantly impact other aspects of the data platform. For instance, neglecting to model SCDs properly could lead to the creation of non-idempotent data pipelines, which, in turn, may introduce various challenges in data management.
The five types of Slowly Changing Dimensions
Dealing with the challenges arising from changes to data over time involves employing various methodologies known as SCD Types.
SCD Type 0: Retain original
The first type of Slowly Changing Dimensions, known as SCD Type 0, deals with data that remains static over time. Examples of such data include Date of Birth, National Insurance Number (or Social Security Number for those in the US), and date dimensions.

SCD Type 1: Overwrite
Type 1 refers to data records that are overwritten each time a change occurs. This means that historical records are not retained, making it impossible to track changes over time.
Before implementing this dimension, it’s crucial to determine whether historical data for these attributes is necessary. Otherwise, the loss of historical data could limit the team’s analytics capabilities.
For instance, let’s consider a business that ships products to customers and needs to store shipping addresses. From an operational standpoint, the business only requires the customer’s latest address for delivery. However, if the business also aims to analyse how often a customer changes their address over time, SCD Type 1 may not be suitable. This type does not retain historical changes, potentially hindering the extraction of such insights.

SCD Type 2: Create new record
SCD Type 2 involves the creation of a new record each time a change occurs. This means that for the same natural key, a new record with a distinct surrogate key is generated to represent the change. This is the way SCD Type 2 preserves historical data.
By associating each natural key with at least one surrogate key, the system retains a trail of changes over time. This approach allows for the tracking of historical variations while maintaining a clear lineage of data evolution.
💡 A quick refresher on Natural vs Surrogate Keys
Natural Key: This is usually a column, or a set of columns, that exist(s) already in the table (i.e. they are attributes of the entity within the data model) and can be used to uniquely identify a record in a table.
Surrogate Key: This is usually a system-generated value – such as UUID, sequence or unique identifier – that has no business meaning and is only used to uniquely identify a record in a table.
In practice, this means that instead of overwriting existing records, as in SCD Type 1, a new record is added to the dimension table, with its own surrogate key. This method ensures that historical data remains intact and accessible for analytical purposes.
For instance, in a scenario where a customer updates their address, instead of modifying the existing customer record, a new record is appended to the dimension table. This approach enables the business to analyse past and present customer details, facilitating insights into trends, behaviours, and historical patterns.
There are several ways to implement SCD Type 2, each with its own approach to preserving historical data; some of them include:
- Timestamp Columns for Validity Intervals: One common approach is to utilise two timestamp columns to denote validity intervals. This method is widely used as it enables tracking of when a change occurred and facilitates effective time window analysis. By recording both the start and end timestamps, it becomes easier to understand the duration of each data version.

- Effective Date and Flag Columns: Another approach combines the use of two columns; an effective date column indicating when a change took effect and a flag column indicating the record’s current validity status.

SCD Type 3: Add new attribute
SCD Type 3 tracks changes in a dimension by introducing a new column to preserve limited historical data. Specifically, this type can capture one change per record.

Unlike the previous types discussed, SCD Type 3 maintains the same natural and surrogate keys for records that have undergone changes in at least one attribute.
This method is particularly useful in scenarios where the primary key must remain unchanged and correspond to a single natural key. Additionally, SCD Type 3 is suitable when only one-time changes need to be recorded, or when it’s guaranteed that a record will not undergo multiple updates.
SCD Type 4: History Tables
Dimensions conforming to SCD Type 4 are stored across two distinct tables. The first table maintains the current state of records, while the second table, known as the history table, preserves all past changes that are no longer valid. Additionally, the history table includes an extra attribute to denote the timestamp when each record was created.
Returning to our example, whenever a change occurs, the latest record is updated in the main table, while an entry is appended to the history table along with the effective timestamp attribute.
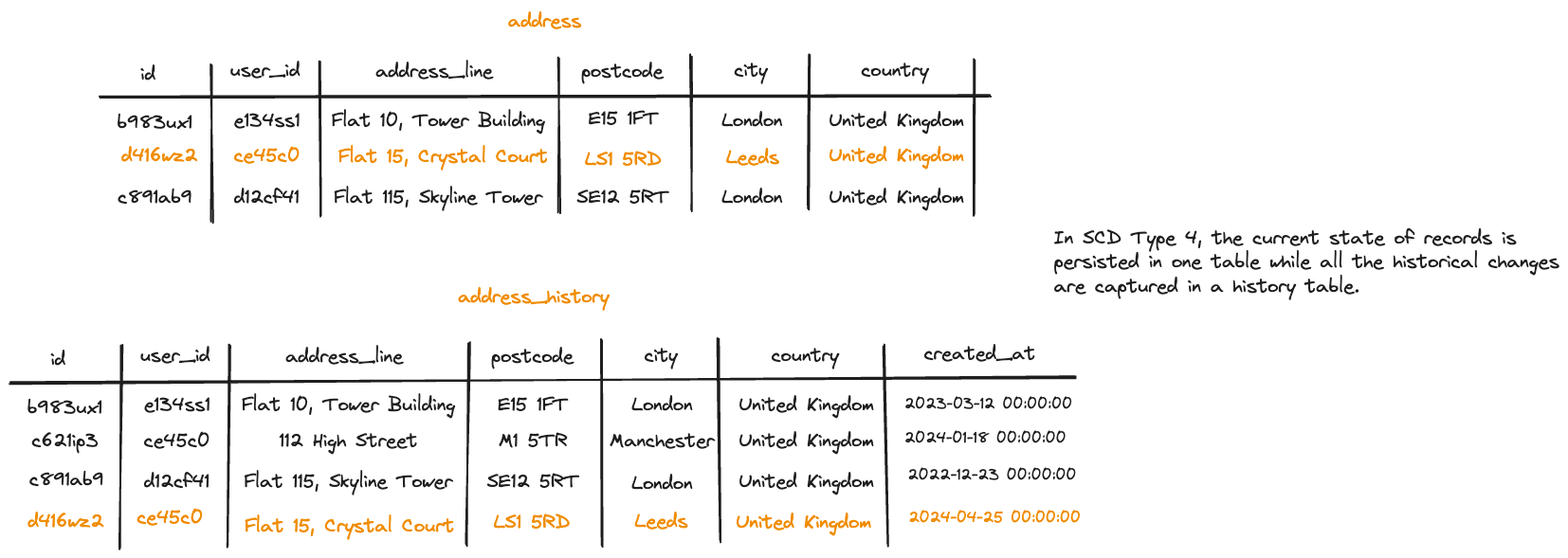
Unlike SCD Type 2, where historical records are managed by adding new entries to the dimension table, SCD Type 4 addresses the scalability issue posed by rapidly changing dimensions.
In this approach, columns expected to undergo frequent changes are relocated to a separate history table.
Implementing Slowly Changing Dimensions in a Data Warehouse
In the context of Data Warehouse design, early consideration of Slowly Changing Dimensions modeling is crucial. As highlighted previously, the effective capture of historical changes within dimensions significantly influences an organisation’s analytical capabilities.
Selecting the appropriate SCD type is not a one-size-fits-all decision; it hinges on both business and technical requirements. Therefore, the initial step is to identify dimensions that require historical retention. While some dimensions may not require capturing changes, others demand the preservation of historical records.
If uncertainty persists regarding whether historical changes should be captured for certain dimensions, it’s advisable to err on the side of caution and opt for SCD types that maintain historical data. This approach is particularly prudent unless data ingestion pipelines and jobs are entirely replayable, which, in my experience, is not always the case.
In cases where changes are not captured and data ingestion pipelines lack replayability, the risk of losing historical data permanently becomes apparent. This loss could severely limit the organization’s ability to conduct retrospective analysis and derive valuable insights from historical trends and patterns. Therefore, careful consideration and proactive measures are essential to ensure the preservation of historical data integrity within the data warehouse.
The selection of the appropriate SCD type should be based on the nature of the dimension and the expected frequency of change. It’s important to note that different dimensions may require different SCD types. However, implementing multiple SCD types means the team will need to manage several different patterns, which requires careful consideration. While this may introduce complexity, it’s crucial to ensure the accurate representation and maintenance of historical data across various dimensions.
As previously noted, these decisions reside at the intersection of business and technical requirements. Therefore, it’s crucial to engage not only data engineers but also data analysts and analytics engineers in defining the actual business needs. This collaborative approach ensures that both the technical feasibility and the business objectives are effectively addressed.
After capturing the business needs, the technical implementation during ingestion must accommodate the identified requirements. This ensures that the data ingestion processes align with and fulfil the established business needs effectively. On the technical side now, there are a few considerations that need to be taken into account.
ELT Pipelines
One approach used to ingest data – in a batch fashion – from an external source, be it a database, an API or a file store, is through ELT pipelines. In essence, an ELT pipeline functions by extracting data from a source, loading it into the destination system, and subsequently executing transformations on the ingested raw data.
Depending on how a particular Slowly Changing Dimension has been modeled, the ELT pipeline needs to behave accordingly in order to comply with the requirements specified by the corresponding SCD type.
- SCD Type 0: The pipeline simply needs to load new records, given that existing records are not updated
- SCD Type 1: The pipeline does not need to retain historicity and this a
MERGE INTOquery can be used to insert new records and overwrite existing ones that match the specified natural key - SCD Type 2: The pipeline needs to insert new records for each change on the dimension table, along with the additional timestamp columns that indicate the effective time window of a particular record. A
MERGE INTOquery can simplify the process of inserting new records, and updating effective end dates of existing records that are no longer valid. - SCD Type 3: The pipeline can use a
MERGE INTOquery in order to insert new records and/or update the existing record to add the current value for an attribute that has changed - SCD Type 4: The ELT pipeline will now have to add or update records in two tables. Depending on the way you implement SCD type 4 you need to adjust the operations of the pipeline accordingly.
UDPATE(and thusMERGE INTO) are not so applicable in this type of SCD. Hence, you can write a query that adds inserts the new record in the table consisting of the current state of the dimension, and also captures the historical change in the history table
The above steps could preserve your preferred SCD type at ingestion time. However, many teams need to apply dimension modeling in more data models. A widely used tool for implementing the transformation step in ELT pipelines is the data build tool (dbt). In addition to ensuring that source tables adhere to the predetermined strategy for handling Slowly Changing Dimensions, it’s important to consider preserving historical data in other data models resulting from subsequent transformations.
dbt offers snapshots, a mechanism that captures changes to a mutable table over time. dbt snapshots inherently implement SCD Type 2 functionality, making them a convenient solution for managing historical data within transformed datasets.
Change Data Capture (CDC)
As mentioned earlier, ELT pipelines are commonly used to ingest data in batches. This means that changes happening in a source, will be captured at a slower pace by an ELT pipeline, since such jobs are scheduled to run on an hourly, daily, or even weekly/monthly schedule.
Change Data Capture pattern can be used to capture and ingest data changes at near real-time. It is a commonly used design pattern that aims to keep source and destinations systems in sync, while preserving the historical changes that occurred over time.
In technical terms, CDC can help us determine when a record has been created or changed. Every record ingested via CDC will usually indicate when the change has occured, what the attributes of the new record are and what kind of operation it relates to (i.e. INSERT, UPDATE or DELETE).
Even though CDC can be used to serve pretty much all SCD types, to my experience, it is widely adopted as part of modeling SCD of Type 2.
The impact of SCD on data pipelines’ idempotency
When building data pipelines, it’s crucial to ensure they are idempotent. The method used to capture changing dimensions could significantly affect your team’s capacity to construct idempotent pipelines and workflows that consume data from the Data Warehouse.
💡 A quick refresher on idempotent data pipelines
Idempotent pipeline: A pipeline that for the same input, it always produces the same results regardless of when or how many times you run it.
- SCD Type 0: Does not really affect idempotency in data pipelines since these dimensions don’t change over time
- SCD Type 1: In this type, only the latest value of an attribute is retained. Therefore, pipelines consuming data from a source modeled using SCD Type 1 are not idempotent. Every time a change occurs and the pipeline re-runs, a different output will be generated
- SCD Type 2: This type is probably the perfect one when it comes down to building idempotent pipelines. However, you need to be careful when using start and end validity intervals
- SCD Type 3: This SCD type could be considered as a partially idempotent but since it only captures only up to one data mutation, I would consider it as a non idempotent (unless it is guaranteed that attributes won’t change more than once)
Final Thoughts
Effectively capturing and managing changes in data dimensions is fundamental to a well-designed Data Warehouse. Therefore, understanding how each dimension should be modeled, considering the frequency and nature of attribute changes, is paramount.
Moreover, it’s crucial to recognize the broader implications of processes like ELT pipelines or CDC on Slowly Changing Dimensions. These processes can significantly influence how dimensional data evolves over time.
It’s important to emphasize that there’s no one-size-fits-all solution. Instead, decisions should be driven by the unique business and analytical requirements of the organization.
Retaining and appropriately modeling historical data changes is a core responsibility of Data Engineering teams. This not only ensures data integrity but also maximises the potential for leveraging organisational data effectively.






