
In this article, I will examine how large language models (LLMs) can convert natural language into SQL, making query writing more accessible to non-technical users. The discussion will include practical examples that showcase the ease of developing LLM-based solutions. We’ll also cover various use cases and demonstrate the process by creating a simple Slack application. Building an AI-driven database querying system involves several critical considerations, including maintaining security, ensuring data relevance, managing errors, and properly training the AI. In this story, I explored the quickest way to tackle these challenges and shared some tips for setting up a solid and efficient text-to-SQL query system.
Lately, it’s hard to think of any technology more impactful and widely discussed than large language models. Llm-based applications are now the latest trend, much like the surge of Apple or Android apps that once flooded the market. It is used everywhere in BI space and I previously wrote about it here [1]
Creating an AI-powered database querying system is a complex task. You’ll need to deal with many important factors like keeping things secure, ensuring data is relevant, handling errors, and training the AI properly. In this story, I explored the quickest way to tackle these challenges.
For example, I built this AI chatbot for Slack in 15 minutes using my old repository template for Serverless API and AWS Lambda function:

Text-to-SQL, reliability and RAGs
Generally speaking, simple Text-to-SQL models are absolutely unreliable and this would be the most common complaint for AI developers I saw in the past:
It looks right but in real life, this SQL is a complete nonsense.
If we’re working with an LLM that generates SQL queries, it can significantly improve if it has access to your database’s Data Definition Language (DDL), metadata, and a collection of well-crafted, optimized queries. By integrating this data, the LLM can produce SQL queries that are not only more reliable but also safer and better optimized for your specific database.
To boost the reliability of SQL generation, one effective approach is to use retrieval-augmented generation (RAG).
In simple terms, RAG allows an LLM to enhance its responses by pulling in additional, relevant data.
This means the model doesn’t just rely on its pre-existing knowledge but can access extra information to tailor its output more accurately to your needs. This method helps ensure that the generated queries align with the actual structure and requirements of your database, making them more effective and reducing the risk of errors.
Text-to-SQL model pain points and limitations
Providing an LLM with written instructions and context is a basic example of in-context learning, where the model derives its output based on the input provided during inference. However, this approach has inherent limitations:
Prompt Sensitivity: Since LLMs predict the next token based on the given input, slight variations in wording can lead to significantly different responses. The output of an LLM is highly dependent on the exact phrasing of the input. This sensitivity to phrasing rather than meaning can result in inconsistent outputs.
Reliability: Simple prompt-based SQL generators are generally unsuitable for enterprise use due to their unreliability. LLMs are prone to generating plausible-sounding but entirely fabricated information. In SQL generation, this can result in queries that appear correct but are fundamentally flawed, often creating fictitious tables, columns, or values.
It might look right but in real life, it will be complete nonsense.
Context Windows: LLMs have a limited capacity for input text or tokens, constrained by their architecture. For instance, ChatGPT 3.5 has a token limit of 4096, which may not suffice for comprehensively understanding a large SQL database with hundreds of tables and columns.
How to build a RAG
There are several robust Python libraries designed for general-purpose applications based on language models, such as LangChain and LlamaIndex. These libraries are great but there are others that are tailored specifically for Text-to-SQL needs, e.g. WrenAI and Vanna. For instance, Vanna.ai offers a targeted approach and is designed to simplify the integration of LLMs with your database, providing secure connections and options for self-hosting. This tool removes much of the complexity, making it easier to leverage LLMs for your specific application without the overhead of more general-purpose libraries.
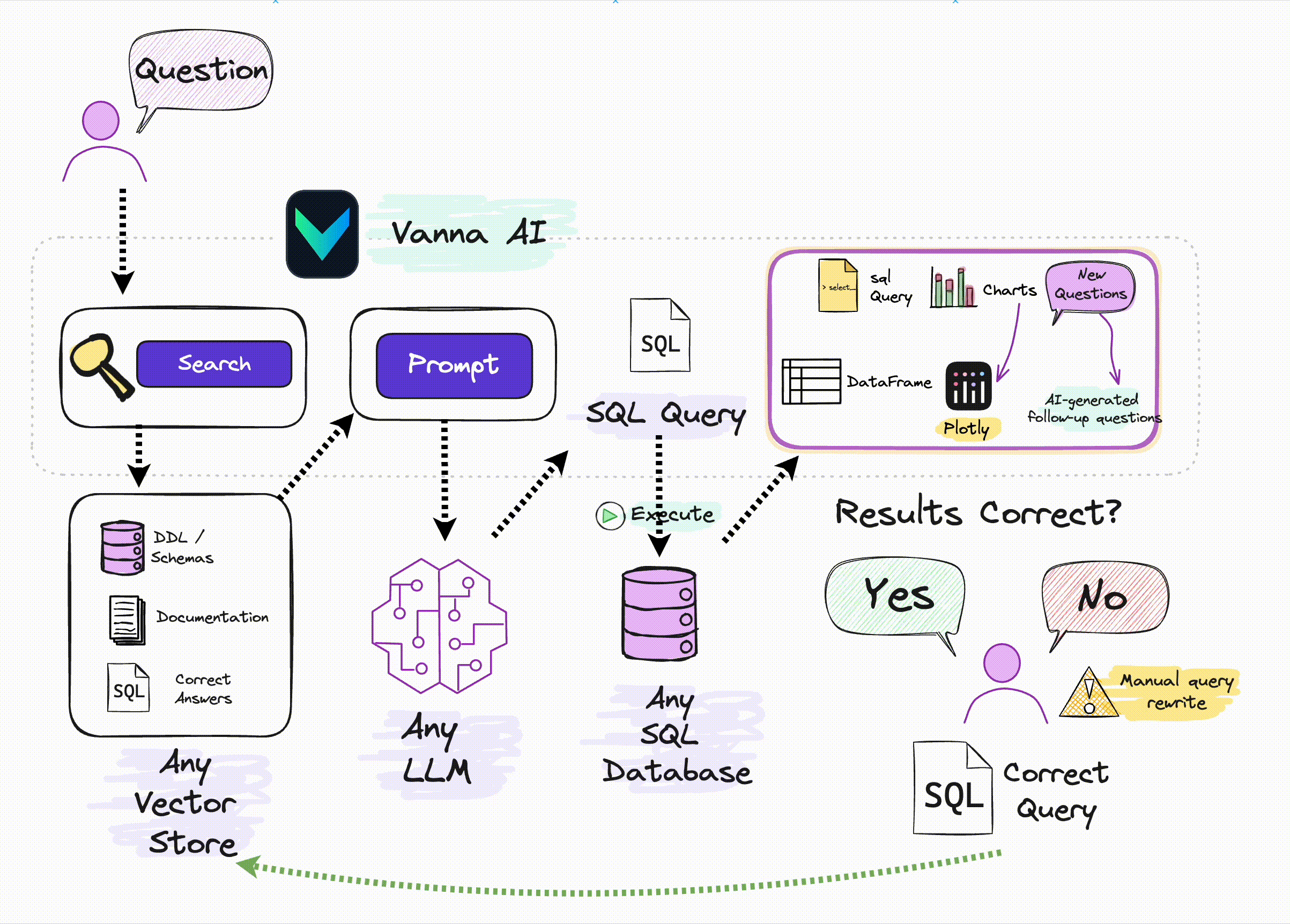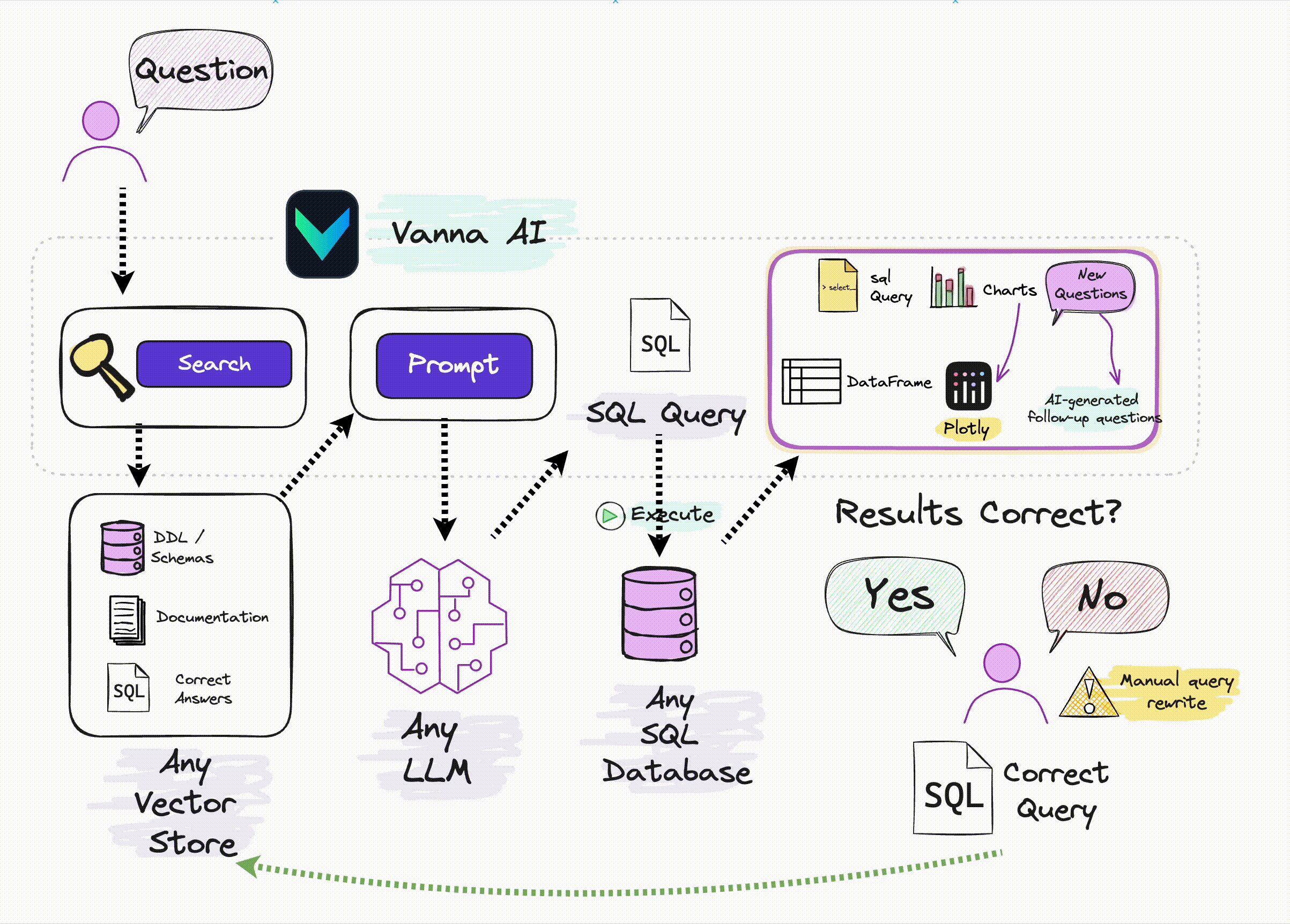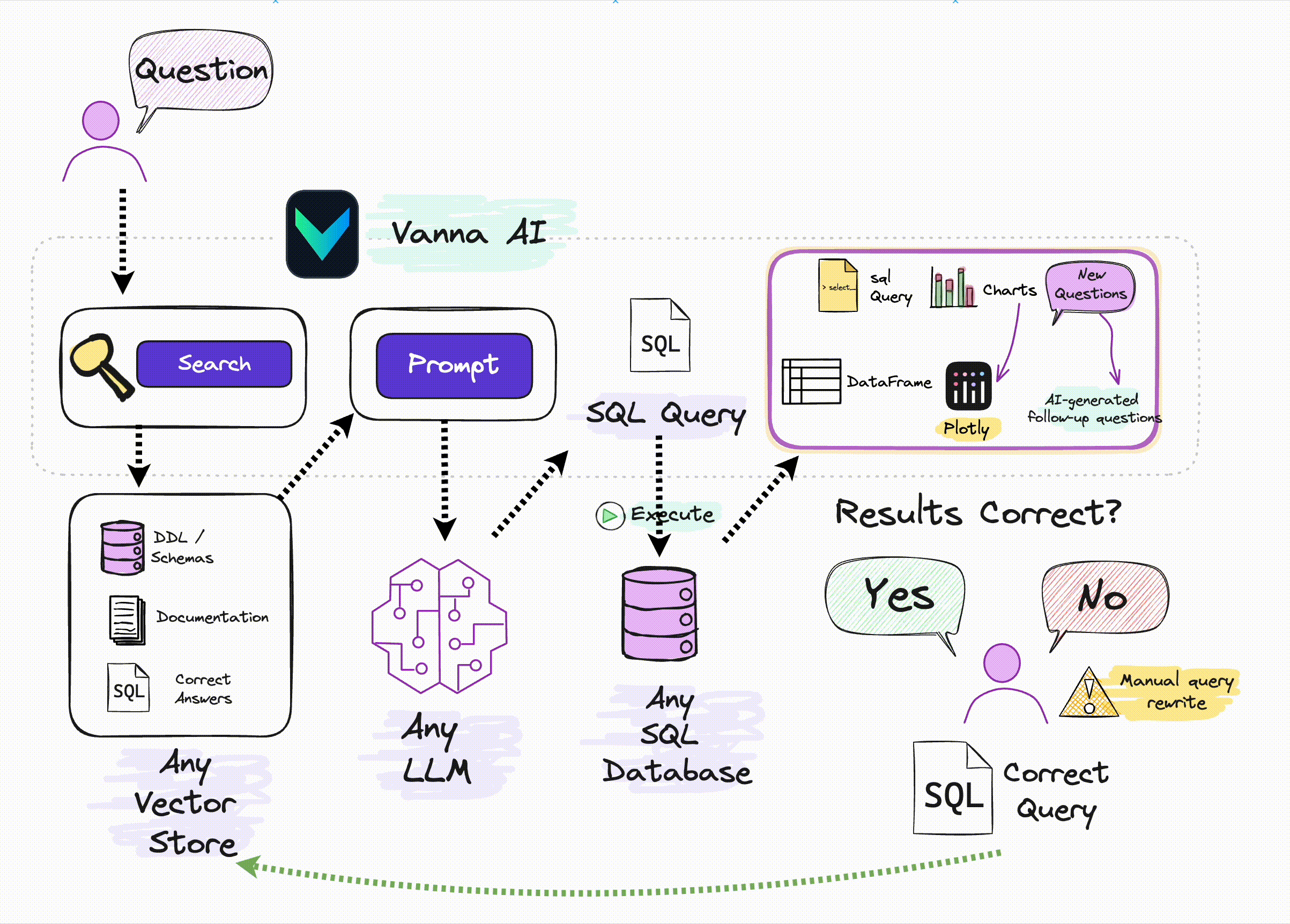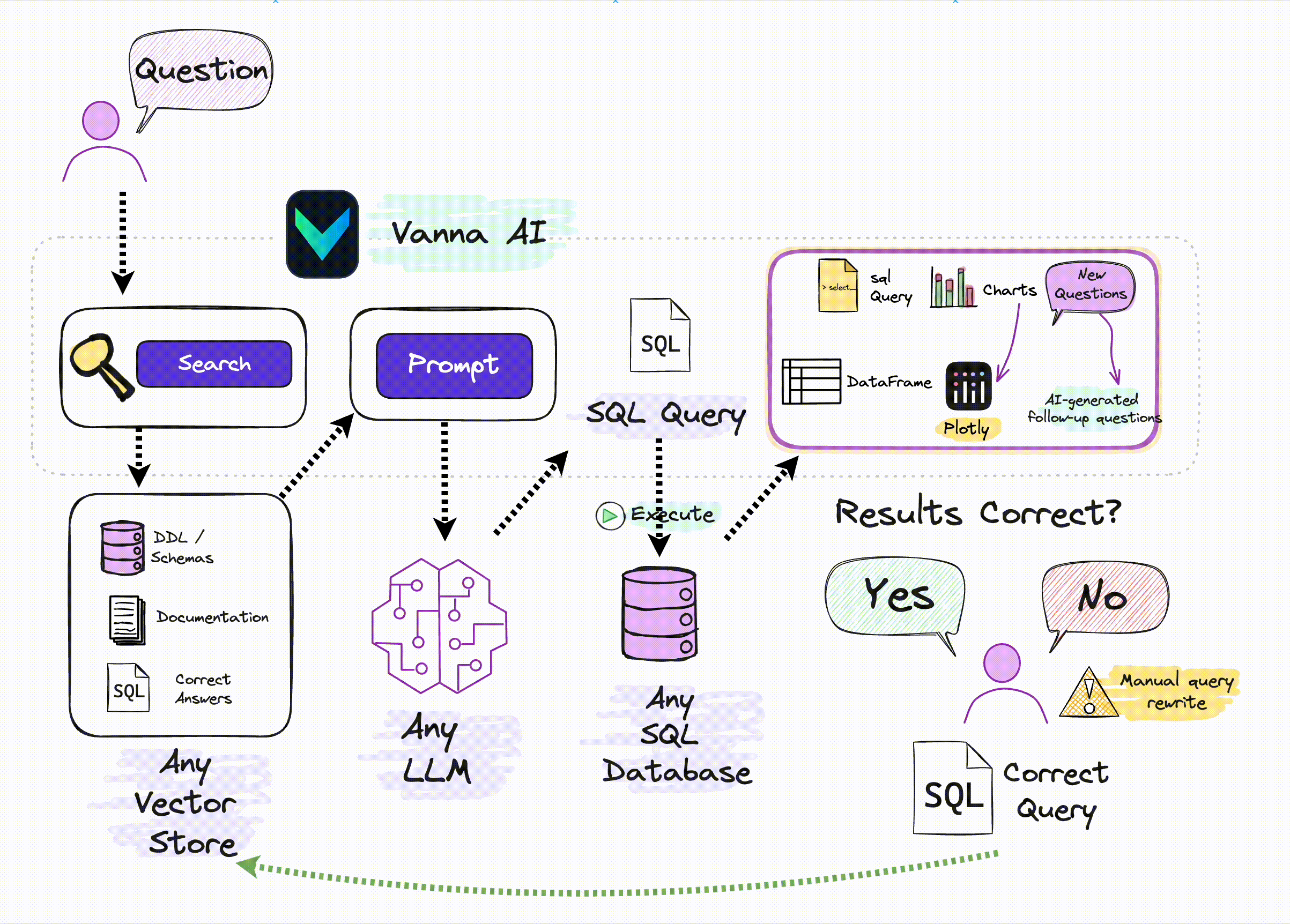
It works in two steps:
- Train a RAG "model" on your data using any LLM (below). All you need is the API key
- Start asking questions.


Alternatively, you can use a pre-trained chinook Vanna model like so:
# create a Python environment
python3 -m venv env
source env/bin/activate
pip3 install --upgrade pip
pip3 install vanna# Run get_sql.py
import vanna as vn
from vanna.remote import VannaDefault
# Get your api key from vanna.ai nad replace here:
vn = VannaDefault(model='chinook', api_key='your-api-key')
vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
vn.ask('What are the top 10 artists by sales?')The terminal output will be the following:
...
LLM Response: SELECT a.ArtistId, a.Name, SUM(il.Quantity) AS TotalSales
FROM Artist a
JOIN Album al ON a.ArtistId = al.ArtistId
JOIN Track t ON al.AlbumId = t.AlbumId
JOIN InvoiceLine il ON t.TrackId = il.TrackId
GROUP BY a.ArtistId, a.Name
ORDER BY TotalSales DESC
LIMIT 10;
Extracted SQL: SELECT a.ArtistId, a.Name, SUM(il.Quantity) AS TotalSales
FROM Artist a
JOIN Album al ON a.ArtistId = al.ArtistId
JOIN Track t ON al.AlbumId = t.AlbumId
JOIN InvoiceLine il ON t.TrackId = il.TrackId
GROUP BY a.ArtistId, a.Name
ORDER BY TotalSales DESC
LIMIT 10;
SELECT a.ArtistId, a.Name, SUM(il.Quantity) AS TotalSales
FROM Artist a
JOIN Album al ON a.ArtistId = al.ArtistId
JOIN Track t ON al.AlbumId = t.AlbumId
JOIN InvoiceLine il ON t.TrackId = il.TrackId
GROUP BY a.ArtistId, a.Name
ORDER BY TotalSales DESC
LIMIT 10;
ArtistId Name TotalSales
0 90 Iron Maiden 140
1 150 U2 107
2 50 Metallica 91
3 22 Led Zeppelin 87
4 113 Os Paralamas Do Sucesso 45
5 58 Deep Purple 44
6 82 Faith No More 42
7 149 Lost 41
8 81 Eric Clapton 40
9 124 R.E.M. 39
WrenAI is another great open-source tool doing a similar thing. It is designed to streamline the process of querying data by converting natural language into SQL. WrenAI is compatible with various data sources, including DuckDB, MySQL, Microsoft SQL Server, and BigQuery. Additionally, it supports both open and local LLM inference endpoints, such as OpenAI’s GPT-3-turbo, GPT-4, and local LLM servers via Ollama. We can use entity relationships to train the model.
In this case, our model becomes more accurate as we provide extra data about our database:

This drag-and-drop style UI simplifies and improves model training a lot.
In each relationship, you can edit, add, or delete semantic connections between models, enabling the LLM to understand whether the relationships are one-to-one, one-to-many, or many-to-many.
Indeed, we don’t need to worry about our SQL semantics once it is defined.
Semantic layer and model training
Another critical consideration in developing an AI-powered database querying system is determining the appropriate tables and columns to which the AI should be granted access.
The selection of these data sources is pivotal, as it directly affects the accuracy and performance of the generated queries, as well as the overall system efficiency.
As I mentioned earlier, providing more detailed information about your database is crucial for accuracy and reliability. Data Definition Language (DDL) captures the structural aspects of a database, detailing elements such as tables, columns, and their interrelationships. Vanna excels in this domain compared to standard prompt-based SQL engines. The following code demonstrates how to retrieve DDL statements for SQLite.
Consider this code snippet below. It explains how to connect to your database and train your RAG model. In my case it will be BigQuery:
# train.py
# Connect to BigQuery
vn.connect_to_bigquery(project_id='my-project')
# The information schema query may need some tweaking depending on your database. This is a good starting point.
df_information_schema = vn.run_sql("SELECT * FROM INFORMATION_SCHEMA.COLUMNS")
# This will break up the information schema into bite-sized chunks that can be referenced by the LLM
plan = vn.get_training_plan_generic(df_information_schema)
plan
# If you like the plan, then uncomment this and run it to train
# vn.train(plan=plan)
# Training on SQL queries:
question = "How many albums did each customer buy?"
sql = vn.generate_sql(question)
display(sql)
#Optional if the response by Vanna is exactly as you intend, you can add in the training data
vn.train(question = question, sql=sql)By using this code above, you can iteratively input queries and assess their outputs. You can then choose to either let Vanna learn from the results or specify preferred queries for it to adapt.
Overloading the system with too many tables and columns can result in increased token counts, elevated costs, and potentially diminished accuracy due to the language model’s risk of confusion or loss of key details. Conversely, insufficient data access limits the AI’s ability to generate precise and effective queries.
This is why this approach is very useful.
A few things to consider:
- Data Quality and Consistency: Select well-maintained, consistently updated data. Inconsistent or incomplete data can lead to inaccurate results and erode user trust.
- Security and PII: Ensure sensitive data is protected. Implement measures like data masking or tokenization to secure confidential information while enabling the AI to access relevant data.
- Relevance to Users: Choose tables and columns that are most relevant to the users’ likely questions. This ensures the AI has the necessary data to produce accurate and useful queries.
- SQL query Performance: Large or complex tables can slow down the AI’s query performance. Select tables and columns that are indexed and optimized to maintain efficient query generation and execution.
Maintaining the history of interactions
This is another common pain point in LLM development. Unlike common misconceptions, LLMs do not remember or learn about your specific data or system from individual queries unless they are explicitly trained with that information.
Each request to an untrained LLM is processed based on its most recent training data, not previous user interactions.
To generate accurate queries, it’s essential to provide the LLM with your chat history with each request. This should include relevant details about your schema and example queries, ensuring that the LLM can generate precise queries tailored to your data.
Training an AI-driven query system involves an iterative process of refinement and enhancement.
Text-to-SQL development best practices
A major concern with text-to-SQL in AI-powered database querying is the risk of unintended modifications to the database. To address this, it is crucial to implement measures that ensure the AI does not alter the underlying data.
- Make sure your generated SQL is validated: Introduce a query validation layer that reviews AI-generated queries before they are executed. This layer should filter out any commands that could modify the database, such as INSERT, UPDATE, DROP, etc. By validating queries before they are processed, you can prevent unintended changes to the database.
- AI service access permissions: Ensure that the AI system is granted only read-only access to the database. This restriction prevents any accidental or malicious changes to the data, preserving database integrity while still allowing the AI to generate queries for data retrieval.
- Monitor SQL query performance: Keeping an eye on usage and query performance metrics is always a good idea.
- Focus on insights: AI-generated SQL queries are excellent for data retrieval, but their true potential is realized when paired with advanced data analysis. By integrating these queries with analytical tools and workflows, you can uncover deeper insights and make more informed, data-driven decisions.
- Custom error handling: Even with meticulous model training and optimization of your text-to-SQL system, there may still be scenarios when generated queries contain parsing errors or have no results. Therefore, it is crucial to implement a mechanism for retrying the query generation and offering constructive feedback to the user in such scenarios. It will enhance the effectiveness and resilience of your text-to-SQL model and improve user experience.
By incorporating these validation mechanisms, you can ensure that AI-generated queries are both secure and reliable, reducing the risk of unintended database modifications and avoiding common query-related issues. This approach not only saves time and resources but also promotes a data-driven culture, where decisions are grounded in accurate and current insights.
Having these policies in place your organization can efficiently harness the full potential of its data, allowing non-technical users to access and analyze information on their own.
Building an AI-powered Slack bot assistant
For this, we will need our OpenAI API key, Slack account and AWS account to deploy the serverless API with a Lambda function.
High-level application logic:
- Slack application will POST text messages to our API
- Our serverless API deployed in AWS will send a Slack message to AWS Lambda
- AWS Lambda will ask OpenAI API for a response and will send it back to Slack
Go to Slack Apps and create a new application: https://api.slack.com/apps

Click "From scratch" and give it a name:

Next, let’s add a slash command to trigger our bot:

In the Edit Command section provide our serverless API endpoint (Request URL):

Finally, let’s Install it to our Slack workspace:

Let’s create a microservice to process Slack messages received by our bot. Our AWS Lambda application code can look like this if written in Node.js:
# app.js
const AWS = require('aws-sdk');
AWS.config.update({region: "eu-west-1"});
const axios = require('axios');
const OPENAI_API_KEY = process.env.openApiKey || 'OpenAI API key';
exports.handler = async (event, context) => {
console.log("app.handler invoked with event "+ JSON.stringify(event,null,2));
try {
context.succeed( await processEvent(event) );
} catch (e) {
console.log("Error: "+JSON.stringify(e));
context.done(e)
}
};
let processEvent = async (event) => {
/**
* Adding command parser fro Slack commands
*/
function commandParser(slashCommand) {
let hash;
let myJson = {};
let hashes = slashCommand.slice(slashCommand.indexOf('?') + 1).split('&');
for (let i = 0; i < hashes.length; i++) {
hash = hashes[i].split('=');
myJson[hash[0]] = hash[1];
}
myJson.timestamp = Date.now();
return myJson;
};
try {
let channel_id = commandParser(event.body).channel_id;
let user_name = commandParser(event.body).user_name;
let txt = commandParser(event.body).text;
// Get response:
let message = await processMessageText(txt,user_name,channel_id);
return {
"statusCode": 200,
"headers": {},
"body": JSON.stringify(message),
"isBase64Encoded": false
};
} catch (err) {
console.log('Error handling event', err);
return {
"statusCode": 500,
"headers": {},
"body": '{}',
"isBase64Encoded": false
};
}
};
const processMessageText = async(txt, user_name, channel_id) => {
let Response = await fetchAi(txt);
let message = {
response_type: 'in_channel',
text: `@${user_name} , ${Response} `
};
return message;
};
const fetchAi = async(prompt) => {
try {
const response = await axios.post(
'https://api.openai.com/v1/chat/completions',
{
model: "gpt-3.5-turbo",
messages: [{ role: "user", content: prompt }],
max_tokens: 150,
temperature: 0.7,
},
{
headers: {
'Authorization': `Bearer ${OPENAI_API_KEY}`,
'Content-Type': 'application/json',
},
}
);
const generatedText = response.data.choices[0].message.content;
return generatedText;
} catch (e) {
return [{NOW: 'You are unable to get a response atm.'}];
}
};
Deploy our API and serverless application with AWS Cloudformation or Terraform and we are ready to go!

In one of my previous articles, I discussed the benefits of deploying applications with Infrastructure as Code [2].
Conclusion
Lately, it’s hard to think of any technology more impactful and widely discussed than large language models. LLM-based applications are now the latest trend, much like the surge of Apple or Android apps that once flooded the market. Training models using DDL statements, custom queries, metadata or documents to refine definitions simplifies the process of LLM development. For instance, if your business uses custom metrics, supplying this additional context will help it generate more accurate and relevant outputs.
Building an AI-powered database querying system is not a trivial task. You’ll need to deal with many important factors like keeping things secure, ensuring data is relevant, handling errors, and training the AI properly. Training an AI-driven query system involves an iterative process of refinement and enhancement. By developing a comprehensive reference guide, supplying diverse example queries, and managing context windows effectively, you can build a robust system that facilitates quick and accurate data retrieval for users.
In this story, I explored the quickest way to tackle these challenges and shared some tips for setting up a solid and efficient AI query system.
Recommended read:
[1] https://medium.com/towards-data-science/artificial-intelligence-in-analytics-f11d2deafdf0
[2] https://medium.com/gitconnected/infrastructure-as-code-for-beginners-a4e36c805316
[3] https://platform.openai.com/docs/quickstart?context=node
[4] https://github.com/openai/openai-node/tree/master/examples






