
Getting Started
When one wants to build an interpretable model, one usually hesitates between the two main families of intrinsically interpretable algorithms: Tree-based algorithms and rule-based algorithms. One of the main differences between them is that tree-based algorithms generate trees with disjoint rules, which has shortcomings such as the replicated subtree problem [1], while rule-based algorithms generate sets of rules and allow overlapping rules which may be a problem. Indeed, how can you make a decision when two (or more) rules are activated simultaneously? This is even more of a problem when the predictions of the rules are contradictory.
In this short article, I present two methods for obtaining a single prediction from a set of rules, less trivial than an average of predictions, but preserving the interpretability of the prediction.
Using expert aggregation methods
If you are not familiar with the theory of aggregation of experts, I refer you to the reading of my previous article "How to choose the best model?". The idea is simple: consider each rules as specialized experts and aggregate their predictions by a convex combination. The weight associated with a rule changes after each prediction: it increases if the expert’s prediction is good and decreases otherwise. Thus, the weight could be interpreted as the confidence we have in each expert at time t.
Unfortunately, the rules may be not activated. This means that the new observation does not fulfill their conditions. They are called "sleeping experts". The question is how can I assess the confidence of a rule that is not activated? There are two common methods. The first is to say "I won’t make a decision without information". This way, the weight of a sleeping rule remains the same until it becomes active again. The second is to ask, "Is it good that this rule is sleeping?". In this way, the new weighting of a sleeping rule is evaluated by considering the aggregate prediction instead of that of the rule. If the aggregated prediction is good, it means that the rule has been right to sleep, otherwise it means that the rule should have been active. These two methods are questionable. But it is proven that they provide similar results.
Using the partitioning trick
The partitioning is a very different idea, more "statistic". The idea is to turn the covering formed by the set of rules into a partition of separated cells (as shown in the figure below). Hence, the prediction will be the mean of the observation in the cell and the interpretation will be a conjunction of rules.
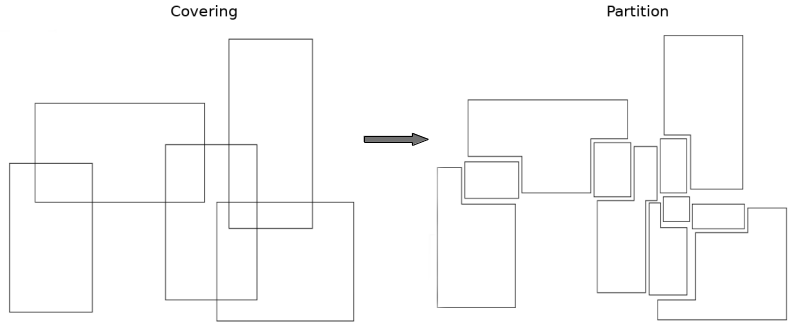
One may object that the construction of this partition is very time-consuming. And it is correct. So, to get around this problem, there exists the partitioning trick. The idea is to understand that it is not necessary to fully describe the partition to compute the prediction value. The trick is to identify the unique cell of the partition that contains the new observation x. By creating binary vectors, whose value is 1 if the new observation, x, fulfills the condition of the rule and 0 otherwise, the identification of the cell containing x is a simple sequence of vectorial operations. Thus, the complexity to calculate a prediction is O(nR), where n is the number of points in the train sets and R is the number of rules. The figure below is an illustration of this process (I refer to [2] for more details).

The main problem with this method it is that we have no control on the size of the cell. In other words, if the cell containing the new observation is too small, you may make a decision based on too few past observations. This problem occurs if you have few data in your training set. It can be interpreted as an unknown situation.
Conclusion
I have presented two methods allowing to make a decision even if your process is based on rules with overlapping. These two methods have pros and cons. The first one, based on the theory of expert aggregation, works well in practice and add a confidence score to the rules. The second, based on the partitioning trick, is better in theory. As mentioned in [3], it is a good way to generate an interpretable consistent estimator of the regression function.
References
[1] G.Bagallo and D.Haussler, Boolean feature discovery in empirical learning (1990), In Machine Learning, 5(1):71–99. Springer.
[2] V.Margot, J-P. Baudry, F. Guilloux and O. Wintenberger, Rule Induction Partitioning Estimator (2018), In International Conference on Machine Learning and Data Mining in Pattern Recognition 288–301. Springer.
[3] V.Margot, J-P. Baudry, F. Guilloux and O. Wintenberger, Consistent Regression using Data-Dependent Coverings (2021), In Electronic Journal of Statistics. The Institute of Mathematical Statistics and the Bernoulli Society.
About Us
Advestis is a European Contract Research Organization (CRO) with a deep understanding and practice of statistics, and interpretable machine learning techniques. The expertise of Advestis covers the modeling of complex systems and predictive analysis for temporal phenomena.







